pyspider定时爬取的问题
多个爬虫出现该问题,爬取的是同一主站下的不用部分。
https://tophub.today/n/mproPp...
https://tophub.today/n/x9ozB4...
#!/usr/bin/env python# -*- encoding: utf-8 -*-
# Created on 2021-03-19 07:34:08
# Project: tophub_zhihu_1
from pyspider.libs.base_handler import *
"""
抓取今日热榜 知乎实时热点
{
"date": 日期,
"hotword": 热点话题,
'rank': 热度,
'hot': 热度排序,
'user': 知乎用户,
'url': 回答链接,
'content': 回答内容,
}
"""
import datetime
class Handler(BaseHandler):
# self.crawl方法的默认参数
# ref: http://docs.pyspider.org/en/latest/apis/self.crawl/#handlercrawl_config
crawl_config = {
'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:86.0) Gecko/20100101 Firefox/86.0',
"headers": {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
},
#"proxy":_proxy,
"timeout" : 1000, #超时时间
"itag": "v2.03" # 爬虫版本--zhaoza:2.0版本,启动不爬取网页
}
@every(minutes=1440) # 每天运行一次这个函数
def on_start(self):
url = 'https://tophub.today/n/mproPpoq6O'
self.crawl(url, callback=self.list_detail)
@config(age= 10 * 60 * 60) # 页面10小时内不重复抓取-10 * 60 * 60
def list_detail(self, response):
table = response.doc('table').eq(0) # 获取页面上的第一个table元素,也就是 "实时热点" table
for rank, row in enumerate(table('tr').items(), 1):
hotword = row('td.al').text()
url = row('td.al a').attr.href
hot = row('td').eq(2).text()
# 爬取每一项,并把当前项的标题、排名、热度值传给下一页面 search_page
self.crawl(url, callback=self.search_page, save=dict(hotword=hotword, rank=rank, hot=hot, url=url, page=0))
@config(priority=2)
def search_page(self, response):
items = response.doc('div.List-item')
for i in items.items():
user = i('div.AuthorInfo .AuthorInfo-name a.UserLink-link').text()
url = i('div.ContentItem>meta[itemprop="url"]').attr.content
content = i('div.RichContent-inner').text()
today = datetime.date.today()
data = {
"date": "%d%02d%02d" % (today.year, today.month, today.day),
"hotword": response.save['hotword'],
'rank': response.save['rank'],
'hot': response.save['hot'],
'user': user,
'url': url,
'content': content,
}
# 一般情况下,直接使用return,一个页面只能返回一条数据
# 使用 send_message来在一个页面上返回多条数据
# http://docs.pyspider.org/en/latest/apis/self.send_message/#selfsend_messageproject-msg-url
self.send_message(self.project_name, data, url=url) # 这里传入url是框架去重使用
# print(data)
def on_message(self, project, msg):
return msg
爬虫效果:每日爬取对应网址列表内容。
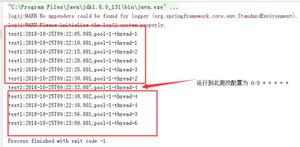
问题描述:爬虫启动第一次爬取正常运行,定时每隔一天再次爬取,之后到定时时间时无法正常爬取。
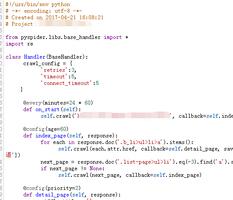
到定时爬取时间时,active tasks中仅有下图内容
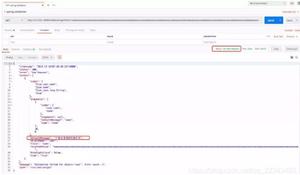
对应taskdb中记录如下图。
正常运行的爬虫taskdb中对应记录如下图。
鬼鬼,真的整不出来了。以前用的时候是正常的。
以上是 pyspider定时爬取的问题 的全部内容, 来源链接: utcz.com/a/158739.html