Python数据分析实战:降雨量统计分析报告分析
![Python数据分析实战:降雨量统计分析报告分析[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/3128211643_1.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于菜J学Python ,作者小小明
最近遇到一个有点烧脑的需求,其实也不算烧脑,主要是判断条件过多,对于我这种记忆力差,内存小的人来说容易出现内存溢出导致大脑宕机。也可能是因为我还没有找到能减小大脑内存压力的方法。
先看看需求吧:

主要就是要根据左侧的表格自动生成右侧的Word统计报告,实际的各种可能性情况远比图中展示的要更加复杂。
好了,直接开始干代码吧!
1数据读取
import pandas as pddf
= pd.read_csv("11月份数据.csv", encoding="gbk")# 当前统计月份month = 11
df = df.query("月份==@month")
df.head(10)
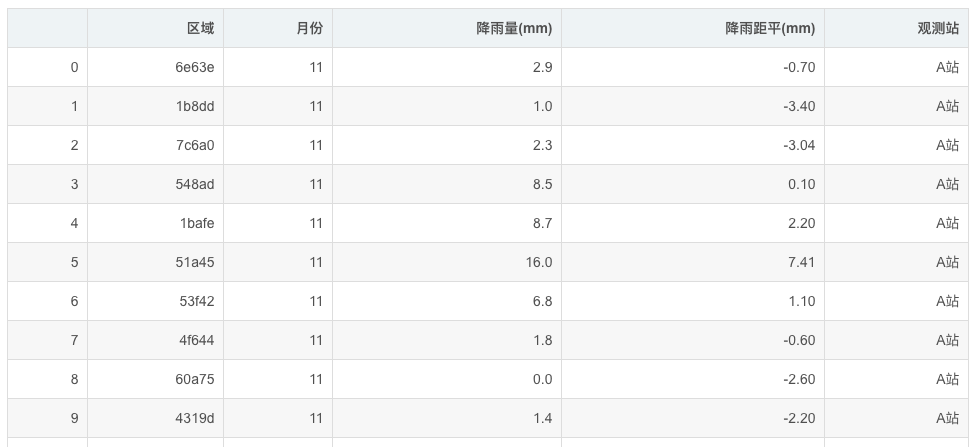
预览数据:
2异常数据过滤
查看缺失值数量:
pd.isnull(df).sum()
结果:
区域 0月份 0
降雨量(mm) 0
降雨距平(mm)
1观测站 0
dtype: int64
仅一个缺失值数据,可直接删除:
df.dropna(inplace=True)
3计算观测站降雨量相对往年的变化
计算降雨量比往年高,跟往年比无变化,以及比往年低的次数分别是多少:
rainfall_high = df.eval("`降雨距平(mm)` > 0").value_counts().get(True, 0)rainfall_equal
= df.eval("`降雨距平(mm)` == 0").value_counts().get(True, 0)rainfall_low
= df.eval("`降雨距平(mm)` < 0").value_counts().get(True, 0)print(rainfall_high, rainfall_equal, rainfall_low)13 1 18
上面的结果中rainfall_high表示降雨量比往年平均水平高的次数,rainfall_equal表示降雨量比往年平均水平持平的次数,rainfall_low表示降雨量比往年平均水平低的次数。
于是分情况讨论生成第一段的报告:
p1 = f"{month}月份"if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p1 += f"除{rainfall_equal}个观测站降雨量较往年无变化外,"
if rainfall_high == 0:
p1 += f"各气象观测站降雨量较往年均偏低。"
elif rainfall_low == 0:
p1 += f"各气象观测站降雨量较往年均偏高。"
else:
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
p1 += f"大部分气象观测站降雨量较往年偏高。"
elif rainfall_low > rainfall_high*1.1:
p1 += f"大部分气象观测站降雨量较往年偏低。"
else:
p1 += f"各气象观测站降雨量较往年整体持平。"
p1
结果:
"11月份大部分气象观测站降雨量较往年偏低。"
4计算各区域降雨量的极值
再生成第二段的报告:
p2 = ""t
= df["降雨量(mm)"]p2
+= f"各区域降雨量在{t.min()}~{t.max()}mm之间,其中{df.loc[t.argmax(), "区域"]}区域的降雨量最大,为{t.max()}mm。"p2
结果:
"各区域降雨量在0.0~16.0mm之间,其中51a45区域的降雨量最大,为16.0mm。"
5分观测站统计
让我脑袋疼的地方就是从这里的代码开始的,后面还有更复杂的需求就不公布了。
对每个观测站分别统计哪些区域偏高,哪些区域持平,哪些区域偏低:
p3s = []for station, tmp in df.groupby("观测站"):t
= tmp["降雨量(mm)"]p3
= f"各区域降雨量在{t.min()}~{t.max()}mm之间,"rainfall_high_mask
= tmp.eval("`降雨距平(mm)` > 0")rainfall_equal_mask
= tmp.eval("`降雨距平(mm)` == 0")rainfall_low_mask
= tmp.eval("`降雨距平(mm)` < 0")rainfall_high
= rainfall_high_mask.value_counts().get(True, 0)rainfall_equal
= rainfall_equal_mask.value_counts().get(True, 0)rainfall_low
= rainfall_low_mask.value_counts().get(True, 0)# print(rainfall_high, rainfall_equal, rainfall_low)if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p3 += "除"
p3 += "、".join(tmp.loc[rainfall_equal_mask, "区域"]+"区域")
p3 += "降雨量较往年无变化外,"
if rainfall_high == 0:
p3 += f"各区域降雨量均较往年偏低"
elif rainfall_low == 0:
p3 += f"各区域降雨量均较往年偏高"
t = tmp["降雨距平(mm)"].abs()
p3 += f"{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 += "除"
p3 += "、".join(tmp.loc[rainfall_equal_mask, "区域"]+"区域")
p3 += "降雨量较往年无变化,"
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
if rainfall_equal == 0:
p3 += "除"
p3 += "、".join(tmp.loc[rainfall_low_mask, "区域"]+"区域")
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, "降雨距平(mm)"].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_high_mask, "降雨距平(mm)"].abs()
p3 += f"其余各区域降雨量较往年偏高{t.min()}~{t.max()}mm;"
elif rainfall_low > rainfall_high*1.1:
if rainfall_equal == 0:
p3 += "除"
p3 += "、".join(tmp.loc[rainfall_high_mask, "区域"]+"区域")
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, "降雨距平(mm)"].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_low_mask, "降雨距平(mm)"].abs()
p3 += f"其余各区域降雨量较往年偏低{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 = p3[:-1]+"外,"
p3 += f"各区域降雨量较往年偏高和偏低的数量持平,其中"
p3 += "、".join(tmp.loc[rainfall_low_mask, "区域"]+"区域")
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, "降雨距平(mm)"].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm,"
else:
p3 += f"{t.min()}mm,"
p3 += "、".join(tmp.loc[rainfall_high_mask, "区域"]+"区域")
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, "降雨距平(mm)"].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm;"
else:
p3 += f"{t.min()}mm;"
p3s.append([station, p3])
p3s[-1][-1] = p3s[-1][-1][:-1]+"。"
p3s
可能是我还没有想出较好的封装方式导致代码变得这么复杂,如果有巧妙解决这个问题的朋友,希望能够加菜J学Python交流群一起探讨。
6将组织好的文本写入到word中
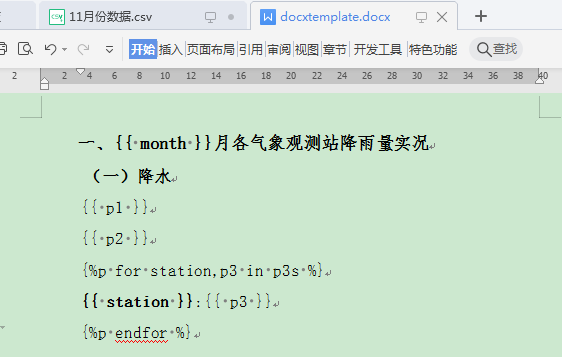
Word模板文件docxtemplate.docx的内容:
一、{{ month }}月各气象观测站降雨量实况(一)降水
{{ p1 }}{{ p2 }}
{
%p for station,p3 in p3s %}{{ station }}:{{ p3 }}
{
%p endfor %}
即:
Python渲染代码:
from docxtpl import DocxTemplatetpl
= DocxTemplate("docxtemplate.docx")context
= {"month": month,"p1": p1,"p2": p2,"p3s": p3s,}
tpl.render(context)
tpl.save(
"11月降雨量报告.docx")
执行完毕,得到Word统计分析报告:

以上是 Python数据分析实战:降雨量统计分析报告分析 的全部内容, 来源链接: utcz.com/z/537646.html