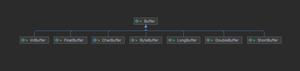
03_MapReduce框架原理_3.4InputSplit切片类(源码)

// 切片类,表示 一份被Mapper处理的数据public abstract class InputSplit {
// 获取切片对象的 长度(单位Bytes)
public abstract long getLength() throws IOException, InterruptedException;
// 获取当前切片对象的 存储信息
public abstract
String[] getLocations() throws IOException, InterruptedException;
// 获取所有切片对象的 存储信息
public SplitLocationInfo[] getLocationInfo() throws IOException {
return null;
}
}
FileSplit对应的是一个输入文件,也就是说,如果用FileSplit对应的FileInputFormat作为输入格式,
那么即使文件特别小,也是作为一个单独的InputSplit来处理,而每一个InputSplit将会由一个独立的Mapper Task来处理。
在输入数据是由大量小文件组成的情形下,就会有同样大量的InputSplit,
从而需要同样大量的Mapper来处理,大量的Mapper Task创建销毁开销将是巨大的,甚至对集群来说,是灾难性的!
// 切片类,表示 一份被Mapper处理的数据// 作为 InputFormat的getSplits方法的返回值
// 作为 InputFormat的createRecordReader方法的输入
// 每个切片 包含文件的一部分 或者整个文件(不可切分或者 文件大小小于切片*1.1时)
public class FileSplit extends InputSplit implements Writable {
private Path file; // 切片 所属的文件名称
private long start; // 切片对应 在文件中的 启示位置
private long length; // 切片长度(字节数)
private String[] hosts; // 切片 所属 block的存储host信息
private SplitLocationInfo[] hostInfos;
// 构造器
public FileSplit() {}
// 构造器
public FileSplit(Path file, long start, long length, String[] hosts) {
this.file = file;
this.start = start;
this.length = length;
this.hosts = hosts;
}
// 构造器
public FileSplit(Path file, long start, long length, String[] hosts,
String[] inMemoryHosts) {
this(file, start, length, hosts);
hostInfos = new SplitLocationInfo[hosts.length];
for (int i = 0; i < hosts.length; i++) {
// because N will be tiny, scanning is probably faster than a HashSet
boolean inMemory = false;
for (String inMemoryHost : inMemoryHosts) {
if (inMemoryHost.equals(hosts[i])) {
inMemory = true;
break;
}
}
hostInfos[i] = new SplitLocationInfo(hosts[i], inMemory);
}
}
/** The file containing this split"s data. */
public Path getPath() { return file; }
/** The position of the first byte in the file to process. */
public long getStart() { return start; }
/** The number of bytes in the file to process. */
@Override
public long getLength() { return length; }
@Override
public String toString() { return file + ":" + start + "+" + length; }
////////////////////////////////////////////
// Writable methods 序列化方法
////////////////////////////////////////////
@Override
public void write(DataOutput out) throws IOException {
Text.writeString(out, file.toString());
out.writeLong(start);
out.writeLong(length);
}
@Override
public void readFields(DataInput in) throws IOException {
file = new Path(Text.readString(in));
start = in.readLong();
length = in.readLong();
hosts = null;
}
@Override
public String[] getLocations() throws IOException {
if (this.hosts == null) {
return new String[]{};
} else {
return this.hosts;
}
}
@Override
@Evolving
public SplitLocationInfo[] getLocationInfo() throws IOException {
return hostInfos;
}
}
CombineFileSplit是针对小文件的分片,它将一系列小文件封装在一个InputSplit内,这样一个Mapper就可以处理多个小文件。
可以有效的降低进程开销。与FileSplit类似,CombineFileSplit同样包含文件路径,分片起始位置,
分片大小和分片数据所在的host列表四个属性,只不过这些属性不再是一个值,而是一个列表。
需要注意的一点是,CombineFileSplit的getLength()方法,返回的是这一系列数据的数据的总长度。
// 切片类,表示 一份被Mapper处理的数据// 一个切片对象,可以包含多个文件
public class CombineFileSplit extends InputSplit implements Writable {
private Path[] paths;
private long[] startoffset;
private long[] lengths;
private String[] locations;
private long totLength;
/**
* default constructor
*/
public CombineFileSplit() {}
public CombineFileSplit(Path[] files, long[] start,
long[] lengths, String[] locations) {
initSplit(files, start, lengths, locations);
}
public CombineFileSplit(Path[] files, long[] lengths) {
long[] startoffset = new long[files.length];
for (int i = 0; i < startoffset.length; i++) {
startoffset[i] = 0;
}
String[] locations = new String[files.length];
for (int i = 0; i < locations.length; i++) {
locations[i] = "";
}
initSplit(files, startoffset, lengths, locations);
}
private void initSplit(Path[] files, long[] start,
long[] lengths, String[] locations) {
this.startoffset = start;
this.lengths = lengths;
this.paths = files;
this.totLength = 0;
this.locations = locations;
for(long length : lengths) {
totLength += length;
}
}
/**
* Copy constructor
*/
public CombineFileSplit(CombineFileSplit old) throws IOException {
this(old.getPaths(), old.getStartOffsets(),
old.getLengths(), old.getLocations());
}
public long getLength() {
return totLength;
}
/** Returns an array containing the start offsets of the files in the split*/
public long[] getStartOffsets() {
return startoffset;
}
/** Returns an array containing the lengths of the files in the split*/
public long[] getLengths() {
return lengths;
}
/** Returns the start offset of the i<sup>th</sup> Path */
public long getOffset(int i) {
return startoffset[i];
}
/** Returns the length of the i<sup>th</sup> Path */
public long getLength(int i) {
return lengths[i];
}
/** Returns the number of Paths in the split */
public int getNumPaths() {
return paths.length;
}
/** Returns the i<sup>th</sup> Path */
public Path getPath(int i) {
return paths[i];
}
/** Returns all the Paths in the split */
public Path[] getPaths() {
return paths;
}
/** Returns all the Paths where this input-split resides */
public String[] getLocations() throws IOException {
return locations;
}
public void readFields(DataInput in) throws IOException {
totLength = in.readLong();
int arrLength = in.readInt();
lengths = new long[arrLength];
for(int i=0; i<arrLength;i++) {
lengths[i] = in.readLong();
}
int filesLength = in.readInt();
paths = new Path[filesLength];
for(int i=0; i<filesLength;i++) {
paths[i] = new Path(Text.readString(in));
}
arrLength = in.readInt();
startoffset = new long[arrLength];
for(int i=0; i<arrLength;i++) {
startoffset[i] = in.readLong();
}
}
public void write(DataOutput out) throws IOException {
out.writeLong(totLength);
out.writeInt(lengths.length);
for(long length : lengths) {
out.writeLong(length);
}
out.writeInt(paths.length);
for(Path p : paths) {
Text.writeString(out, p.toString());
}
out.writeInt(startoffset.length);
for(long length : startoffset) {
out.writeLong(length);
}
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < paths.length; i++) {
if (i == 0 ) {
sb.append("Paths:");
}
sb.append(paths[i].toUri().getPath() + ":" + startoffset[i] +
"+" + lengths[i]);
if (i < paths.length -1) {
sb.append(",");
}
}
if (locations != null) {
String locs = "";
StringBuffer locsb = new StringBuffer();
for (int i = 0; i < locations.length; i++) {
locsb.append(locations[i] + ":");
}
locs = locsb.toString();
sb.append(" Locations:" + locs + "; ");
}
return sb.toString();
}
}
以上是 03_MapReduce框架原理_3.4InputSplit切片类(源码) 的全部内容, 来源链接: utcz.com/z/536188.html