MySQL性能优化小结

基础概念简述
锁
数据库通过锁机制来解决并发场景 — 共享锁(读锁)和排他锁(写锁)。读锁是不阻塞的,多个客户端可以在同一时刻读取同一个资源;写锁是排他的,并且会阻塞其他的读锁和写锁。
简单提下乐观锁和悲观锁:
- 乐观锁:通常用于数据竞争不激烈的场景,多读少写,通过版本号和时间戳实现
- 悲观锁:通常用于数据竞争激烈的场景,每次操作都会锁定数据
要锁定数据需要一定的锁策略来配合。
- 表锁:锁定整张表,开销最小,但是会加剧锁竞争
- 行锁:锁定行级别,开销最大,但是可以最大程度的支持并发
但是 MySQL 的存储引擎的真实实现不是简单的行级锁,一般都是实现了多版本并发控制(MVCC)。MVCC 是行级锁的变种,多数情况下避免了加锁操作,开销更低。MVCC 是通过保存数据的某个时间点快照实现的。
事务
事务保证一组原子性的操作,要么全部成功,要么全部失败。一旦失败,回滚之前的所有操作。MySQL 采用自动提交,如果不是显式的开启一个事务,则每个查询都作为一个事务。
隔离级别控制了一个事务中的修改,哪些在事务内和事务间是可见的。四种常见的隔离级别:
- 未提交读(
Read UnCommitted):事务中的修改,即使没提交对其他事务也是可见的。事务可能读取未提交的数据,造成 脏读 - 提交读(
Read Committed):一个事务开始时,只能看见已提交的事务所做的修改。事务未提交之前,所做的修改对其他事务是不可见的。也叫 不可重复读,同一个事务多次读取同样记录可能不同 - 可重复读(
RepeatTable Read):同一个事务中多次读取同样的记录结果时结果相同 - 可串行化(
Serializable):最高隔离级别,强制事务串行执行
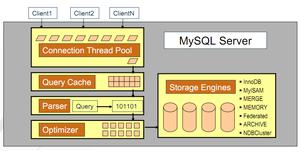
存储引擎
InnoDB引擎:最重要,使用最广泛的存储引擎。被用来设计处理大量短期事务,具有高性能和自动崩溃恢复的特性MyISAM引擎:不支持事务和行级锁,崩溃后无法安全恢复
创建时优化
Schema和数据类型优化
整数
TinyInt, SmallInt, MediumInt, Int, BigInt 使用的存储8,16,24,32,64位存储空间。
使用 Unsigned 表示不允许负数,可以使正数的上线提高一倍。
实数
Float,Double:支持近似的浮点运算Decimal:用于存储精确的小数
字符串
VarChar:存储变长的字符串。需要1或2个额外的字节记录字符串的长度Char:定长,适合存储固定长度的字符串,如MD5值Blob,Text:为了存储很大的数据而设计的。分别采用二进制和字符的方式
时间类型
DateTime:保存大范围的值,占8个字节TimeStamp:推荐,与UNIX时间戳相同,占4个字节
优化建议点
- 尽量使用对应的数据类型。比如,不要用字符串类型保存时间,用整型保存IP
- 选择更小的数据类型。能用
TinyInt不用Int - 标识列(
identifiercolumn),建议使用整型,不推荐字符串类型,占用更多空间,而且计算速度比整型慢 - 不推荐
ORM系统自动生成的Schema,通常具有不注重数据类型。例如,使用很大的VarChar类型,索引利用不合理等问题 - 真实场景混用范式和反范式。冗余高查询效率高,插入更新效率低;冗余低插入更新效率高,查询效率低
- 创建完全的独立的汇总表缓存表,定时生成数据,用于用户耗时时间长的操作。对于精确度要求高的汇总操作,可以采用 历史结果+最新记录的结果 来达到快速查询的目的
- 数据迁移,表升级的过程中可以使用影子表的方式,通过修改原表的表名,达到保存历史数据,同时不影响新表使用的目的
索引
索引包含一个或多个列的值。MySQL 只能高效的利用索引的最左前缀列。索引的优势:
- 减少查询扫描的数据量
- 避免排序和零时表
- 将随机 IO 变为顺序 IO (顺序IO的效率高于随机IO)
B-Tree
使用最多的索引类型。采用 B-Tree 数据结构来存储数据(每个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的遍历)。B-Tree 索引适用于全键值,键值范围,键前缀查找,支持排序。
B-Tree 索引限制:
- 如果不是按照索引的最左列开始查询,则无法使用索引
- 不能跳过索引中的列。如果使用第一列和第三列索引,则只能使用第一列索引
- 如果查询中有个范围查询,则其右边的所有列都无法使用索引优化查询
哈希索引
只有精确匹配索引的所有列,查询才有效。存储引擎会对所有的索引列计算一个哈希码,哈希索引将所有的哈希码存储在索引中,并保存指向每个数据行的指针。
哈希索引限制:
- 无法用于排序
- 不支持部分匹配
- 只支持等值查询如
=,IN( ),不支持< >
优化建议点
- 注意每种索引的适用范围和适用限制。
- 索引的列如果是表达式的一部分或者是函数的参数,则失效
- 针对特别长的字符串,可以使用前缀索引,根据索引的选择性选择合适的前缀长度
- 使用多列索引的时候,可以通过
AND和OR语法连接 - 重复索引没必要,如(A,B)和(A)重复
- 索引在
where条件查询和group by语法查询的时候特别有效 - 将范围查询放在条件查询的最后,防止范围查询导致的右边索引失效的问题
- 索引最好不要选择过长的字符串,而且索引列也不宜为
null
查询时优化
三个重要指标
- 响应时间 (服务时间,排队时间)
- 扫描的行
- 返回的行
查询优化点
- 避免查询无关的列,如使用
select *返回所有的列。 - 避免查询无关的行
- 切分查询。将一个对服务器压力较大的任务,分解到一个较长的时间中,并分多次执行。如要删除一万条数据,可以分10次执行,每次执- 行完成后暂停一段时间,再继续执行。过程中可以释放服务器资源给其他任务。
- 分解关联查询。将多表关联查询的一次查询,分解成对单表的多次查询。可以减少锁竞争,查询本身的查询效率也比较高。因为
MySQL的连接和断开都是轻量级的操作,不会由于查询拆分为多次,造成效率问题。 - 注意
count的操作只能统计不为null的列,所以统计总的行数使用count(*) group by按照标识列分组效率高,分组结果不宜出行分组列之外的列- 关联查询延迟关联,可以根据查询条件先缩小各自要查询的范围,再关联
union查询默认去重,如果不是业务必须,建议使用效率更高的union alllimit分页优化。可以根据索引覆盖扫描,再根据索引列关联自身查询其他列。如:
SELECT id,
NAME,
age
WHERE
student s1
INNER JOIN (
SELECT
id
FROM
student
ORDER BY
age
LIMIT 50,5
) AS s2 ON s1.id = s2.id
其它优化点
- 表关联查询时务必遵循 小表驱动大表 原则;
- 使用查询语句
where条件时,不允许出现 函数,否则索引会失效; - 使用单表查询时,相同字段尽量不要用
OR,因为可能导致索引失效,比如:SELECT * FROM table WHERE name = "手机" OR name = "电脑",可以使用UNION替代; LIKE语句不允许使用%开头,否则索引会失效;- 组合索引一定要遵循 从左到右 原则,否则索引会失效;比如:
SELECT * FROM table WHERE name = "张三" AND age = 18,那么该组合索引必须是name,age形式; - 索引不宜过多,根据实际情况决定,尽量不要超过 10 个;
- 每张表都必须有 主键,达到加快查询效率的目的;
- 分表,可根据业务字段尾数中的个位或十位或百位(以此类推)做表名达到分表的目的;
- 分库,可根据业务字段尾数中的个位或十位或百位(以此类推)做库名达到分库的目的;
- 表分区,类似于硬盘分区,可以将某个时间段的数据放在分区里,加快查询速度,可以配合 分表 + 表分区 结合使用
- 文章作者:彭超
- 本文首发于个人博客:https://antoniopeng.com/2019/12/08/mysql/MySQL%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E5%B0%8F%E7%BB%93/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 彭超 | Blog!
以上是 MySQL性能优化小结 的全部内容, 来源链接: utcz.com/z/533110.html