update()与save()有什么区别

update()与save()的区别
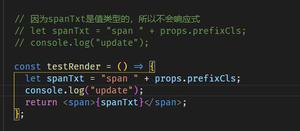
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,而update()则是针对修改的项进行针对的更新效率高耗时少。
所以以后对数据的修改保存用update()
让我们通过orm对数据库操作时候,让终端显示内部查询操作sql语句:
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = { 'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上
补充:
除了配置外,还可以通过一点query即可查看查询语句,具体操作如下:
only 与 defer
拿到的是一个对象 两者是相反的
(前提设置:设置每次操作数据库时候都会有sql语句现实在pycharm终端,上面已说明步骤)
先看看only:
看看defer
相关推荐:《Python相关教程》
choice属性
choice这个属性,用来限制用户做出选择的范围。比如说性别的选择(男或女)
class MyUser(models.Model):name = models.CharField(max_length=32)
password = models.CharField(max_length=32)
choices = ((1, '男'), (2, '女'), (3, '其它'))
gender = models.CharField(choices=choices, default=1, max_length=5)
choice接收一个元组(保证值不可变),同理每一个选项也是由一个元组(value,display_name)构成。显而易见,display_name就是要在页面中展示的。
如何取到value和displayname?
比如说实例一个User对象user_obj,
user_obj.gender = value (通过属性取value)
user_obj.get_gender_display() = display_name (通过 get_属性_display()方法取display_name)
在模板中可以通过模板语言{{ user_obj.gender }}很简单地显示value,但不能直接调用get属性_display方法(模板毕竟是模板语言),要解决这个问题,可以用自定义过滤器来搞定:
来回顾一下如何自定义过滤器:
1,在应用名下新建一个名为templatetags文件夹
2,在该文件夹内新建一个py文件,名字随意
3,在该py文件内添加固定代码和自定义过滤器代码
from django import templateregister = template.Library()
@register.filter(name='displayName')
def displayName(obj):
res = obj.get_gender_display
return res()
# 视图层:
from django.shortcuts import render, HttpResponse,reverse
# Create your views here.
from app01 import models
def index(request):
obj = models.MyUser.objects.filter(pk=1).first()
return render(request, 'index.html', locals())
# 前端(html页面):
{% load my_file %}
{{ obj|displayName}}
bulk_create批量插入数据
当我们使用orm来一次性新增很多表记录的时候,等待结果的时间会非常的慢,如果一次性需要批量插入很多数据的时候就需要使用bulk_create来批量插入数据。
import randomuser_list = ['用户[{}]'.format(i) for i in range(100)]
data = []
for j in user_list:
data.append(models.MyUser(name=j, password='123', gender=str(random.choice([1, 2, 3]))))
models.MyUser.objects.bulk_create(data)
select_related和prefetch_related
def select_related(self, *fields)性能相关:表之间进行join连表操作,一次性获取关联的数据。
总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
以上是 update()与save()有什么区别 的全部内容, 来源链接: utcz.com/z/523383.html