elasticsearch第三讲

tmdb 表示的是模板名称 dmdb1 表示的是当前的索引
脚本方式编辑
##编辑模板POST _scripts/tmdb
{
"script": {
"lang": "mustache",
"source": {
"_source": ["title", "overview"],
"size": 20,
"query": {
"multi_match": {
"query": "{{q}}",
"fields": ["title", "overview"]
}
}
}
}
}
## 编辑查询
POST tmdb1/_search/template
{
"id": "tmdb",
"params": {
"q": "basketball with cartoon aliens"
}
}
aliases 的用户
它相当于 es 某个文档的一个别名,可以把多个索引放入到同一个视图中,也可以添加过滤器,把符合条件的索引数据 查询出来,最后集中成一个别名,查询该别名可以把多个索引里的数据都查询出来
#### 新增别名POST _aliases
{
"actions": [
{
"add": {
"index": "news",
"alias": "new1"
}
},
{
"add": {
"index": "blogs",
"alias": "new1"
}
}
]
}
## 查询的时候 会吧对应的news和blogs里的数据都查询出来
POST new1/_search
{
"query": {
"match_all": {}
}
}
### 删除别名
POST _aliases
{
"actions": [
{
"remove": {
"index": "blogs",
"alias": "new1"
}
},
{
"remove": {
"index": "news",
"alias": "new1"
}
}
]
}
function score query
表示的是对结果数据重新算分,然后排序,详情自行百度
新算分 = 老算分 * 投票数
使用modifier 新算分 = 老算分 * log( 1+投票数)
引入 factor 老算分 * log( 1 + factor * 投票数)
当前的 boostMode 都是为 multipfy, 表示的是老算法和后边的关系,可以为 sum 等等可以查官网信息
max boost 表示的是 当前的分数控制的最大范围
DELETE blogsPUT blogs/_doc/1
{
"title": "About popularity",
"content": "In this post we wil talk about...",
"votes": 0
}
PUT blogs/_doc/2
{
"title": "About popularity",
"content": "In this post we wil talk about...",
"votes": 100
}
PUT blogs/_doc/3
{
"title": "About popularity",
"content": "In this post we wil talk about...",
"votes": 1000000
}
POST blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 3
}
}
}
suggester 推荐的使用方式
suggest_mode missing表示的是 如果索引中如果存在,则不提供建议,例如lucen solid中的solid; popular 表示的是 推荐出现的频率比较高的词例如:
rock会推荐rocks,因为文档里面有两个里面有 rocks;always表示的是 不论是否存在在索引中都会推荐
POST articles/_bulk {"index": {}}
{"body": "lucene is very cool"}
{"index": {}}
{"body": "Elasticsearch builds on top of lucene"}
{"index": {}}
{"body": "Elasticsearch rocks"}
{"index": {}}
{"body": "elastic is the company behind ELK stack"}
{"index":{}}
{"body": "Elk stack rocks"}
{"index":{}}
{"body": "elasticsearch is rock solid"}
POST articles/_search
{
"suggest": {
"test1": {
"text": "lucen solid",
"term": {
"field": "body",
"suggest_mode": "missing"
}
}
}
}
completion suggester
联想词信息,基于fst 内存查找的方式,速度比较快,但是局限也是 只能从首字母开始匹配
DELETE articlesGET articles/_mapping
PUT articles
{
"mappings": {
"properties": {
"title_completion": {
"type": "completion"
}
}
}
}
POST articles/_bulk
{"index": {}}
{"title_completion": "lucene is very cool"}
{"index": {}}
{"title_completion": "Elasticsearch builds on top of lucene"}
{"index": {}}
{"title_completion": "Elasticsearch rocks"}
{"index": {}}
{"title_completion": "elastic is the company behind ELK stack"}
{"index":{}}
{"title_completion": "Elk stack rocks"}
{"index":{}}
{"title_completion": "elasticsearch is rock solid"}
POST articles/_search?pretty
{
"suggest": {
"articles_suggester": {
"prefix": "e",
"completion": {
"field": "title_completion"
}
}
}
}
completion 可以根据分类进行查找不同的文档, type为 category 表示任意字符串
DELETE commentsPUT comments
{
"mappings": {
"properties":{
"comment_autocomplete": {
"type": "completion",
"contexts": [
{
"type": "category",
"name": "comment_category"
}
]
}
}
}
}
POST comments/_doc/1
{
"comment": "I love the star war movies",
"comment_autocomplete": {
"input": ["star wars"],
"contexts": {
"comment_category": "movies"
}
}
}
POST comments/_doc/2
{
"comment": "Where can I find a Starbucks",
"comment_autocomplete": {
"input": ["starbucks"],
"completions": {
"comment_category": "coffee"
}
}
}
POST comments/_search
{
"suggest": {
"YOUR_SUGGESTION": {
"text": "star",
"completion":{
"field": "comment_autocomplete",
"contexts":
{
"comment_category": "movies"
}
}
}
}
}
配置夸集群搜索
通过命令的方式,可以吧多个集群里面的数据进行搜索
elasticsearch-7.5.0/bin/elasticsearch -E node.name=cluster1_node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301elasticsearch-7.5.0/bin/elasticsearch -E node.name=cluster2_node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302
elasticsearch-7.5.0/bin/elasticsearch -E node.name=cluster3_node -E cluster.name=cluster3 -E path.data=cluster3_data -E discovery.type=single-node -E http.port=9203 -E transport.port=9303
curl -XPUT "http://localhost:9201/_cluster/settings" -H "Content-Type:application/json" -d "{"persistent":{"cluster":{"remote":{"cluster1":{"seeds":["127.0.0.1:9301"], "transport.ping_schedule":"30s"},"cluster2":{"seeds":["127.0.0.1:9302"],"transport.ping_schedule":"30s","transport.compress": true, "skip_unavailable":true},"cluster3":{"seeds":["127.0.0.1:9303"]}}}}}"
curl -XPUT "http://localhost:9202/_cluster/settings" -H "Content-Type:application/json" -d "{"persistent":{"cluster":{"remote":{"cluster1":{"seeds":["127.0.0.1:9301"], "transport.ping_schedule":"30s"},"cluster2":{"seeds":["127.0.0.1:9302"],"transport.ping_schedule":"30s","transport.compress": true, "skip_unavailable":true},"cluster3":{"seeds":["127.0.0.1:9303"]}}}}}"
curl -XPUT "http://localhost:9203/_cluster/settings" -H "Content-Type:application/json" -d "{"persistent":{"cluster":{"remote":{"cluster1":{"seeds":["127.0.0.1:9301"], "transport.ping_schedule":"30s"},"cluster2":{"seeds":["127.0.0.1:9302"],"transport.ping_schedule":"30s","transport.compress": true, "skip_unavailable":true},"cluster3":{"seeds":["127.0.0.1:9303"]}}}}}"
curl -XPOST "http://localhost:9201/users/_doc" -H "Content-Type:application/json" -d "{"name":"user1", "age": 10}"
curl -XPOST "http://localhost:9202/users/_doc" -H "Content-Type:application/json" -d "{"name":"user2", "age": 20}"
curl -XPOST "http://localhost:9203/users/_doc" -H "Content-Type:application/json" -d "{"name":"user3", "age": 30}"
访问方式
http://localhost:9201/cluster1:users,cluster2:users,cluster3:users/_search
node.master=false 可以设置当前节点不能为主节点
如果配置成功,则如果更改node.master=true的时候,启动当前的服务,则会报错
master not discovered or elected yet, an election requires不能找到主节点,解决方式是 删除 对应的data数据,但是这样对应的 数据信息也全部删除掉啦;可以优先启动 原主节点,然后再启动删除以后的 节点,这样数据会重新同步过来
es 如果设置的主分片为3 副本为1,如果数据分布到不同的机器上,如果某台机子挂掉,则改机子里面的数据对应的副本也会同步到其他机器上,如果挂掉的机器是主分片,则会在副本中重新选举 主分片
主分片创建的时候就确定不能修改,除非删除索引 重新录入;
文档到分片的路由算法
shard = hash(_routing) % number_of_primary_shards
hash 确保均匀的分布到分片中 默认_routing 是文档的id
可以指定_routing 的值 这里就是 主分片不能修改的原因
PUT posts/_doc/100?routing=bigdata{
"title": "Master Elasticsearch",
"body": "Let"s Rock"
}
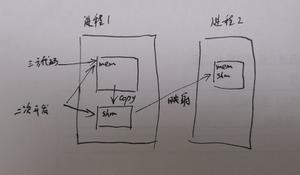
es分片和生命周期
单个倒排索引表示的是一个 segment,segment是不可变更的,多个segment就是 index,他对应的是es中的分片
当有文档写入的时候,会生成新的 segment ,查询的时候会查询所有的 segments,对结果汇总 ,删除文档信息 保存在 .del 文件中
es refresh
将index buffer 写入到 segment的过程叫 refresh,
refresh 默认1秒执行一次,refresh成功以后就可以被搜索到啦;
如果系统有大量的数据写入就会有很多的 segment
index buffer 被占满也会触发 refresh,默认值为 JVM的 10%
<img src="/Users/duanlsh/Library/Application Support/typora-user-images/image-20200327015811530.png" alt="image-20200327015811530" style="zoom:50%;" />
transaction log
segment 写入磁盘的过程比较耗时,所以,先把segment写入缓存,以开放查询;
为啦防止数据丢失,所以同时会写入到 Transaction log 中,transaction log会有入盘操作,每个分片都有一个 transaction log
这样,如果断电的情况下,如果启动先从transaction log中加载到数据,保证数据完整性
<img src="/Users/duanlsh/Library/Application Support/typora-user-images/image-20200327020120587.png" alt="image-20200327020120587" style="zoom:50%;" />
Flush
flush 默认30分钟调用一次,首先调用 refresh 清空 index buffer;
调用 fsync, 将缓存中的 segment 写入到磁盘,保证所有数据 进入到 transaction log中;
清空 transaction log 中的数据;
当 transaction log 满的时候也会调用flush, transaction默认为 512MB大小;
<img src="/Users/duanlsh/Library/Application Support/typora-user-images/image-20200327020850670.png" alt="image-20200327020850670" style="zoom:50%;" />
merge
segment有很多,会定期进行合并;减少 segment的数量和 删除的文件;
强制merge 通过 POST my_index/_forcemerge 进行操作
对文本进行排序
对文本排序需要设置 字段为 fielddata 为true 默认为 docvalues ,更改为 field data
<img src="/Users/duanlsh/Library/Application Support/typora-user-images/image-20200328014528877.png" alt="image-20200328014528877" style="zoom:50%;" />
PUT /kibana_sample_data_ecommerce/_mapping{
"properties":{
"customer_full_name" : {
"type" : "text",
"fielddata": true,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
es 分页获取数据
深度分页 from size
es数据是保存到多个分片上的,多个机器上的,当查询 from 990 size 10 的时候,会在每个分片上获取 1000个文档,然后通过 coordinating Node 聚合所有结果,最后再通过排序获取前 1000个文档,页数越深,占用的内存也越大,es默认限制是10000个文档,可以通过 index.max.result.window 来设置
POST /kibana_sample_data_ecommerce/_search{
"from": 1,
"size": 2,
"query": {
"match_all": {}
}
}
search_after 他必须的from为0开始
search_after 为 返回的结果信息里面的 sort信息,以此来实现分页效果;可以避免深度分页问题;
但是如果新添加数据,仍然可以搜索的到
//第一次请求:POST /kibana_sample_data_ecommerce/_search
{
"size": 2,
"query": {
"match_all": {}
},
"sort": [
{
"order_date": {
"order": "desc"
},
"_id":{
"order": "desc"
}
}
]
}
返回结果
...
"sort" : [
1581808954000,
"gTTfym8BtdKew7ex1Zsk"
]
//第二次请求
POST /kibana_sample_data_ecommerce/_search
{
"from": 1,
"size": 2,
"query": {
"match_all": {}
},
"search_after":[
1581808954000,
"gTTfym8BtdKew7ex1Zsk"
],
"sort": [
{
"order_date": {
"order": "desc"
},
"_id":{
"order": "desc"
}
}
]
}
scroll api 的用法
他是通过创建快照的方式进行查询;
也就是在生成快照的时候的数据,为最终能查找到的数据,如果中间新增啦数据,是无法查找到的;
查找方式为每次查找数据,都要输入上次查找的id
他的数量是按照第一次查询的数量计算的;
//设置croll保存5分钟POST /kibana_sample_data_ecommerce/_search?scroll=5m
{
"size": 1,
"query": {
"match_all":{}
}
}
//吧上面结果的scrollId 获取 再次查询,有效为1分钟
POST _search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAADZUWSThxQkp4VUZTZy1ZZzE0OGI1OW02Zw=="
}
from size search after scroll
不适合深度分页
可以深度分页,但是只能从0开始往后查询
随机返回效率高
适合 前几页数据查询
适合深度分页查询
适合全部文件获取下载
es并发控制
es 并发采用的是乐观锁;
es 使用 if_seq_no和if_primary_term来更新数据的时候,当前的数据的 对应的值必须的和传递的值相同,否则不能更新
es 也可以通过 version和version_type 为锁来控制对应的值信息
DELETE productsGET products/_search
//此处会返回对应的 seq_no 和 primary_term 的值,就是下面对应的值信息
PUT products/_doc/1
{
"title": "iphone",
"count": 100
}
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{
"title":"iphone1",
"count": 100
}
//此处的version必须的大于当前1文档的version否则冲突这个就是es的并发处理乐观锁PUT products/_doc/1?version=6&version_type=external
{
"title":"iphone2",
"count": 1
}
es的聚合分析 min max avg stats terms range histogram
sql es
select count(brand) from table
metric
group by
bucket
聚合计算 是不能操作text类型的数据的;
terms aggregation 不能对text进行 分桶,可以更改为
filedata类型 可以参考 docvalue和field data 的不区别, keyword 默认支持分桶aggs 包含 min max avg stats terms range histogram
先分组,然后获取分组内的 top信息用的是 top_hits
获取总分组的数量使用的是 cardinality
DELETE employeesGET employees/_mapping
PUT employees
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"gender": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"salary": {
"type": "integer"
},
"job": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above":22
}
}
}
}
}
}
POST employees/_bulk
{"index":{"_id": "1"}}
{"name":"Emma","age":"32","job":"Product Manager", "gender": "female","salary": "35000"}
{"index":{"_id": "2"}}
{"name":"Underwood","age":"41","job":"Dev Manager", "gender": "male","salary": "50000"}
{"index":{"_id": "3"}}
{"name":"Tran","age":"25","job":"Web Designer", "gender": "male","salary": "18000"}
{"index":{"_id": "4"}}
{"name":"Rivera","age":"26","job":"Web Designer", "gender": "female","salary": "22000"}
{"index":{"_id": "5"}}
{"name":"Rose","age":"25","job":"QA", "gender": "female","salary": "18000"}
{"index":{"_id": "6"}}
{"name":"Lucy","age":"31","job":"QA", "gender": "female","salary": "25000"}
{"index":{"_id": "7"}}
{"name":"Byrd","age":"27","job":"QA", "gender": "male","salary": "20000"}
{"index":{"_id": "8"}}
{"name":"Foster","age":"27","job":"Java Programmer", "gender": "male","salary": "20000"}
{"index":{"_id": "9"}}
{"name":"Gregory","age":"32","job":"Java Programmer", "gender": "male","salary": "22000"}
{"index":{"_id": "10"}}
{"name":"Bryant","age":"20","job":"Java Programmer", "gender": "male","salary": "9000"}
{"index":{"_id": "11"}}
{"name":"Jenny","age":"36","job":"Java Programmer", "gender": "female","salary": "38000"}
{"index":{"_id": "12"}}
{"name":"Mcdonald","age":"31","job":"Java Programmer", "gender": "male","salary": "32000"}
{"index":{"_id": "13"}}
{"name":"Jonthna","age":"30","job":"Java Programmer", "gender": "female","salary": "30000"}
{"index":{"_id": "14"}}
{"name":"Marsha","age":"32","job":"Javascript Programmer", "gender": "male","salary": "25000"}
{"index":{"_id": "15"}}
{"name":"King","age":"33","job":"Java Programmer", "gender": "male","salary": "28000"}
{"index":{"_id": "16"}}
{"name":"Mccarthy","age":"21","job":"Javascript Programmer", "gender": "male","salary": "16000"}
{"index":{"_id": "17"}}
{"name":"Goodwid","age":"25","job":"Javascript Programmer", "gender": "male","salary": "16000"}
{"index":{"_id": "18"}}
{"name":"Catherine","age":"29","job":"Javascript Programmer", "gender": "female","salary": "20000"}
{"index":{"_id": "19"}}
{"name":"Boone","age":"30","job":"DBA", "gender": "male","salary": "30000"}
{"index":{"_id": "20"}}
{"name":"Kathy","age":"29","job":"DBA", "gender": "female","salary": "20000"}
POST employees/_search
{
"size": 0,
"aggs": {
"min_salary": {
"min": {
"field": "salary"
}
}
}
}
POST employees/_search
{
"size": 0,
"aggs": {
"max_salary": {
"max": {
"field": "salary"
}
}
}
}
POST employees/_search
{
"size": 0,
"aggs": {
"min_salay": {
"min": {
"field": "salary"
}
},
"max_salay": {
"max": {
"field": "salary"
}
},
"avg_salay": {
"avg": {
"field": "salary"
}
}
}
}
POST employees/_search
{
"size": 20,
"aggs": {
"stats_salay":{
"stats": {
"field": "salary"
}
}
}
}
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
}
}
//分桶返回的类别总数量
POST employees/_search
{
"size": 0,
"aggs": {
"cardinate": {
"cardinality": {
"field": "job.keyword"
}
}
}
}
POST employees/_search
{
"size": 0,
"aggs": {
"gender": {
"terms": {
"field": "age",
"size": 20
}
}
}
}
### 根据不同的工种 年龄最大的3员工信息
POST employees/_search
{
"size": 0,
"aggs": {
"result": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"old_employees": {
"top_hits": {
"size": 3
, "sort": [
{"age": {"order": "desc"}}
]
}
}
}
}
}
}
#### range 分桶,指定key
POST employees/_search
{
"size": 0,
"aggs": {
"range_result": {
"range": {
"field": "salary",
"ranges": [
{
"from": 0,
"to": 10000
},
{
"key": "1w-2w",
"from": 10000,
"to": 20000
},
{
"key": ">2w",
"from": 20000
}
]
}
}
}
}
#### histogram 分桶 按照5000进行分桶统计
POST employees/_search
{
"size": 0,
"aggs": {
"result1": {
"histogram": {
"field": "salary",
"interval": 5000,
"extended_bounds": {
"min": 0,
"max": 100000
}
}
}
}
}
pipeline 聚合分析
pipeline 表示的是 可以对 聚合的结果进行二次聚合
#### 获取term_job 分桶下的每一个值的平均值中的最小值#### term_job 表示的外部聚合 avg_salary 表示的是外部聚合的内部聚合
POST employees/_search
{
"size": 0,
"aggs": {
"term_job": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"avg_salary":{
"avg": {
"field": "salary"
}
}
}
},
"result":{
"min_bucket": {
"buckets_path": "term_job>avg_salary"
}
}
}
}
聚合的作用范围和排序
1使用query进行查询,当进行聚合的时候,是对query的结果进行聚合操作的; eg1
2、可以再 aggs中使用 filter 进行过滤,同时进行agg聚合,当前是在 fillter结果中进行聚合操作,如果在filter的父级进行aggs操作的话,是操作的全部数据 eg2
3、postfield 是对 聚合结果进行筛选,查看匹配对应结果的数据 eg3
4、global 相当于是1和2的整合,当使用global的时候,进行query查询不会对结果统计有影响 eg4
5、聚合排序的时候 可以按照字段key和count进行排序 eg5
6、聚合排序的时候,可以按照另一个聚合结果进行排序 eg6
eg1
POST employees/_search{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"result": {
"terms": {
"field": "job.keyword"
}
}
}
}
eg2
#### 分为两种,一种是过滤结果的统计,一个是整个内容的统计,query 查询结果只能 过滤结果的统计POST employees/_search
{
"size": 0,
"aggs": {
"old_persion": {
"filter": {
"range": {
"age": {
"gte": 40
}
}
},
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
}
},
"all_jobs":{
"terms": {
"field": "job.keyword"
}
}
}
}
eg3
POST employees/_search{
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
},
"post_filter": {
"match":{
"job.keyword": "Web Designer"
}
}
}
eg4
##### global 相当于上面的对所有内容统计的部分处理;此处不是用的filter方式,而是用的global的方式进行处理; 他是忽略掉啦 query的查询条件;POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 40
}
}
},
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
},
"all":{
"global": {},
"aggs": {
"all_result": {
"terms": {
"field": "job.keyword"
}
}
}
}
}
}
eg5
#### 排序顺序 _key 表示的是按照key执行 _count 按照数量执行排序,顺序是按照后面写的字段优先排序,然后再按照前面写的字段排序,当前就是 先按照 _count 再按照 _key 排序POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"NAME": {
"terms": {
"field": "job.keyword",
"order": {
"_key": "desc",
"_count": "asc"
}
}
}
}
}
eg6
#### 按照聚合结果进行排序POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"order": {
"test1": "asc"
}
},
"aggs": {
"test1": {
"avg": {
"field": "salary"
}
}
}
}
}
}
分布式系统近似统计算法
TODO 再验证
<img src="/Users/duanlsh/Library/Application Support/typora-user-images/image-20200401013056443.png" alt="image-20200401013056443" style="zoom:50%;" />
nested 对象
nested 对象信息 表示的是数据查询中包含对象的信息
eg1 查询中 搜索
KeanuHopper是可以查询到结果的,因为es分析的时候,相当于解析成啦actors.first_name=["Keanu",Dennis]和actors.last_name=["Reeves","Hopper"]通过以前学的知识可知,只要包含查询值,则会命中,所以可以选中;eg2 查询搜索
KeanuHopper是不可以命中的,因为使用啦 nested 表示的是一个对象,他解析成的是 两个文档,Keanu Reeves和Dennis Hopper只有包含着两个钟的一个才会命中
eg1
DELETE my_moviePUT my_movie
{
"mappings" : {
"properties" : {
"actors" : {
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "text"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
POST my_movie/_doc/1
{
"title": "speed",
"actors": [
{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}
POST my_movie/_search
{
"query": {
"bool": {
"must": [
{"match": {
"actors.first_name": "Keanu"
}},
{"match": {
"actors.last_name": "Hopper"
}}
]
}
}
}
eg2
DELETE my_moviePUT my_movie
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested",
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "text"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
POST my_movie/_doc/1
{
"title": "speed",
"actors": [
{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}
POST my_movie/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{"match": {
"actors.first_name": "Keanu"
}},
{"match": {
"actors.last_name": "Hopper"
}}
]
}
}
}
}
]
}
}
}
文档的父子关系文档
建立父子文档关系
DELETE my_blogsPUT my_blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation":{
"type": "join",
"relations": {
"blog": "comment"
}
},
"content":{
"type": "text"
},
"title":{
"type": "keyword"
}
}
}
}
PUT my_blogs/_doc/blog1
{
"title": "Learning Elasticsearch",
"content": "learning ELK @ geektime",
"blog_comments_relation": {
"name": "blog"
}
}
PUT my_blogs/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation":{
"name": "blog"
}
}
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment": "I am learning ELK",
"username": "Jack",
"blog_comments_relation": {
"name":"comment",
"parent": "blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment": "I like Hadoop!!!!!",
"username": "Jack",
"blog_comments_relation": {
"name":"comment",
"parent": "blog2"
}
}
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop",
"username": "Bob",
"blog_comments_relation": {
"name":"comment",
"parent": "blog2"
}
}
POST my_blogs/_search
{
}
GET my_blogs/_doc/blog2
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
#### 返回子文档信息
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
"content": "Learning hadoop"
}
}
}
}
}
#### 返回父文档信息
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
"username": "Bob"
}
}
}
}
}
索引重建
当索引类型发生变更,需要重建索引
索引主分片发生变化 需要重建索引
update by query 在现有的索引上重建
reindex 在其他索引上重建
DELETE blogsPUT blogs/_doc/1
{
"content":"Hadoop is cool",
"keyword": "hadoop"
}
GET blogs/_mapping
PUT blogs/_mapping
{
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer": "english"
}
}
}
}
}
PUT blogs/_doc/2
{
"content": "Elasticsearch rocks",
"keyword": "elasticsearch"
}
POST blogs/_search
{
"query": {
"match": {
"content.english": "hadoop"
}
}
}
##### 添加索引部分内容的时候,直接 _update_by_query
POST blogs/_update_by_query
{}
PUT blogs/_mapping
{
"properties": {
"keyword" : {
"type" : "keyword"
}
}
}
DELETE blogs_fix
#### 更改类型的时候 重建索引
PUT blog_fix
{
"mappings": {
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
},
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"keyword" : {
"type" : "keyword"
}
}
}
}
GET blog_fix/_mapping
###### 重建索引,把原来的索引导入进新索引
POST _reindex
{
"source": {
#### 原来索引名
"index": "blogs",
#### 获取匹配的索引
"query": {
"match": {
"content": "elasticsearch"
}
},
"size": 1
},
"dest": {
#### 目标索引
"index": "blog_fix",
#### 如果当前索引的数据存在,则抛异常,不存在的数据添加进去
#### 如果不加这个则 全部覆盖, 但是如果原来已经存在的,添加进来的数据不存在,则直接保留
"op_type": "create"
}
}
GET blog_fix/_doc/1
PUT blog_fix/_doc/3
{
"content": "Elasticsearch rocks copy1",
"keyword": "elasticsearch copy1"
}
DELETE blog_fix/_doc/1
POST blog_fix/_search
{
"size": 0,
"aggs": {
"blog_keyword": {
"terms": {
"field": "keyword",
"size": 10
}
}
}
}
POST blog_fix/_search
{}
IngestPipeline
相当于是一个管道,可以对添加进去的数据进行 管道过滤处理,比如说新增字段 es,hadoop 可以通过分割管道,在新增的时候指定分割管道,则添加的数据自动转换成 对应的数据; 也可以对原来的数据 指定管道的方式重建索引
### pipleline 的用法DELETE tech_blogs
PUT tech_blogs/_doc/1
{
"title": "Introducing big data...",
"tags": "hadoop,elasticsearch,spark",
"content": "You know, for big data"
}
GET tech_blogs/_doc/1
#### 测试pipleline对字段的 测试效果
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
// 对字段进行分割
"split": {
"field": "tags",
"separator": ","
}
},
{
// 添加字段
"set": {
"field": "view",
"value": "0"
}
}
]
},
"docs": [
{
"_source" : {
"tags" : "hadoop,elasticsearch,spark"
}
}
]
}
//定义一个pipleine
PUT _ingest/pipeline/blog_pipleline
{
"processors": [
{
"split": {
"field": "tags",
"separator": ","
},
"set": {
"field": "view",
"value": "0"
}
}
]
}
GET _ingest/pipeline/blog_pipleline
// 这样会对文案自动使用上blog_pipleline 对应的信息
POST _ingest/pipeline/blog_pipleline/_simulate
{
"docs": [
{
"_source" : {
"tags" : "hadoop,elasticsearch,spark"
}
}
]
}
POST tech_blogs/_doc/2?pipeline=blog_pipleline
{
"title": "Introducing cloud computering",
"tags": "openstacks, k8s",
"content": "You know, for cloud"
}
POST tech_blogs/_doc/3
{
"title": "Introducing cloud computering",
"tags": "openstacks, k8s",
"content": "You know, for cloud"
}
POST tech_blogs/_search
{}
//执行的时候虽然已经使用 blog_pipleline 的数据会报错,但是也会修改成功
POST tech_blogs/_update_by_query?pipeline=blog_pipleline
{}
// 可以通过这样的方法整体更改
POST tech_blogs/_update_by_query?pipeline=blog_pipleline
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "views"
}
}
]
}
}
}
以上是 elasticsearch第三讲 的全部内容, 来源链接: utcz.com/z/515057.html