Elasticsearch 全文搜索分析
一、介绍
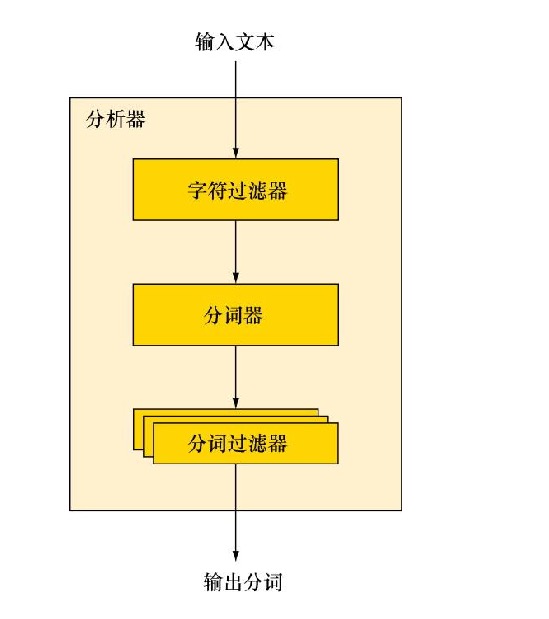
分析机制用于进行全文本的分词,以建立供搜索使用的反向索引。
分析的过程如下:
- 首先,标记化一个文本块为适用于倒排索引的单独的词 term;
- 然后,标准化这些词为标准形式,提供它们的可搜索性或者查全率。
字符过滤器
character filter:字符过滤器的工作是在标记化之前处理字符串,字符过滤器能够去除HTML标记,或者转换 & 为 and 等工作。
分词器
tokenizer:文档被标记化为独立的词,一个简单的分词器可以根据空格或者逗号将单词分开(这个在中文中不适用)。
标记过滤
token filter:分词后每个独立的词都通过标记过滤,标记过期能够修改词(譬如将大写转换为小写,将时态进行转换),去掉词(譬如去掉“a”, “and”, “the”等连词和冠词),或者增加词(譬如同义词)。
ElasticSearch附带了一些预装的分析器,可以直接使用。
标准分析器:
这是ElasticSearch默认使用的分析器。对于文本分析,它对于任何语言都是最佳选择(如果没有特殊需求的话)。标准分析器根据Unicode Consortium定义的单词边界来切分文本,然后去掉大部分的标点符号,最后把所有词转换为小写。
简单分析器:将非单个字母的文本切分,然后把每个词转换为小写。
空格分析器:依据空格切分文本,不转换大小写。
语言分析器:适用于很多语言,能够考虑到特定语言的特性。
例如,english分析器自带一套英语停用词库,这些词被移除之后,英语单词的主体含义依旧能被理解。
二、在索引创建时增加分析器
PUT http://localhost:9200/shuidi/{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"index":{//其他索引级别的设置
"analysis":{//索引的分析设置
-----------------------------定制化分析器------------------------------------------
"analyser":{//在分析器对象中设置定制分析器
"myCustomAnalyzer":{//定制名为myCustomAnalyzer的分析器
"type":"custom",//定制化类型
"tokenizer":"myCustomTokenizer",//使用myCustomTokenizer对文本进行分词
"filter":["myCustomFilter1","myCustomFilter2"],//指定文本需要经过两个过滤器
"char_filter":["myCustomCharFilter"],//设置定制的字符串过滤器myCustomCharFilter,这会在其他分析步骤之前运行
}
},
-----------------------------分词器------------------------------------------
"tokenizer":{
"myCustomTokenizer":{//设置定制分词器的类型为letter
"type":"letter"
}
},
-----------------------------定制过滤器------------------------------------------
"filter":{
"myCustomFilter1":{
"type":"lowercase"
},
"myCustomFilter2":{
"type":"kstem"
}
},
-----------------------------字符过滤器------------------------------------------
"char_filter":{
"myCustomCharFilter":{//定制的字符过滤器,将字符翻译为其他映射
"type":"mapping",
"mappings":["ph=>f","u=>you"]
}
}
}
},
"mappings":{}
}
}
三、在配置文件中添加分析器(elasticsearch.yml)
除了在索引创建时设置分析器,另一种设置定制分析器的方法是向 Elasticsearch 的配置文件中添加分析器。但是使用这种方法的时候需要折中考虑。如果在索引创建的时候设置分析器,那么无须重启Elasticsearch就能修改分析器。可是,如果在 Elasticsearch 的配置中指定分析器,那么需要重启 Elasticsearch 才能让分析器的修改生效。
从另一方面来看,如果在配置中指定,创建索引时所需要发送的数据会更少。尽管在索引创建时进行设置,通常会获得更大的灵活性,但是如果你从未打算修改分析器,那么可以直接将它们放入配置文件中。
index: analysis:
analyzer:
myCustomAnalyzer:
type:custom
tokenizer:myCustomTokenizer
filter:[myCustomFilter1,myCustomFilter2]
char_filter:myCustomCharFilter
tokenizer:
myCustomTokenizer:
type:letter
filter:
myCustomFilter1:
type:lowercase
myCustomFilter2:
type:kstem
char_filter:
myCustomCharFilter:
type:mapping
mappings:["ph=>f","u=>you"]
四、在映射中指定某个字段的分析器
"mappings": { "company": {
"properties": {
"companyName": {
"type": "text",
"analyzer": "ik_max_word"
},
"description":{
"type":"string",
"analyzer":"myCustomAnalyzer"//为description 字段指定myCustomAnalyzer 的分析器
},
------------------------------------------------------------------
//如果想让某个字段完全不被分析处理,需要指定index字段为not_analyzed。
//这将使得文本作为单个分词来处理,不会受到任何修改(不会转为小写或者进行其他任何改变)。
"name":{
"type":"string",
"index":"not_analyzed"//指定不要分析name字段
}
五、使用 API 来分析文本
localhost:9200/_analyze?analyzer=standard六、使用词条向量 API 来学习索引词条
当考虑合适的分析器时,前一节的 _analyze 端点是个很好的方法。但是对于特定文档中的词条,如果想学习更多内容,就存在一个比遍历所有单独字段更有效的方法。可以使用_termvector的端点来获取词条的更多信息。使用这个端点就可以了解词条,了解它们在文档中、索引中出现的频率,以及出现在文档中的位置。
localhost:9200:/get-together/group/1/_termvector?pretty=true七、分析器、分词器和分词过滤器
本节将讨论 Elasticsearch 所提供的内置分析器、分词器和分词过滤器。Elasticsearch 提供了许多这样的模块,如小写转换、提取词干、特定语言、同义词等。因此,可以有充足的灵活性,以不同的方式来组合它们,获得想要的分词。
内置的分析器
一个分析器包括一个可选的字符过滤器、一个单个分词器、0 个或多个分词过滤器。
- 标准分析器:当没有指定分析器的时候,标准分析器(standard analyzer)是文本的默认分析器。
- 简单分析器:(simple analyzer)它只使用了小写转换分词器
- 空白分析器:空白分析器(whitespace analyzer)什么事情都不做,只是根据空白将文本切分为若干分词
- 停用词分析器:停用词分析器(stop analyzer)和简单分析器的行为很相像,只是在分词流中额外地过滤了停用词。
- 关键词分析器:关键词分析器(keyword analyzer)将整个字段当作一个单独的分词。 请记住,最好是将index设置指定为not_analyzed,而不是在映射中使用关键词分析器。
- 模式分析器:模式分析器(pattern analyzer)允许你指定一个分词切分的模式。 但是,由于可能无论如何都要指定模式,通常更有意义的做法是使用定制分析器,组合现有的模式分词器和所需的分词过滤器。
- 语言和多语言分析器:Elasticsearch支持许多能直接使用的特定语言分析器。
- 雪球分析器:雪球分析器(snowball analyzer)除了使用标准的分词器和分词过滤器(和标准分析器一样), 也使用了小写分词过滤器和停用词过滤器。它还使用了雪球词干器对文本进行词干提取。
内置的分词器
- 标准分词器:标准分词器(standard tokenizer)是一个基于语法的分词器,对于大多数欧洲语言来说是不错的。 它还处理了Unicode文本的切分,不过分词默认的最大长度是255。它也移除了逗号和句号这样的标点符号。
- 关键词分词器:关键词分词器(keyword tokenizer)是一种简单的分词器,将整个文本作为单个的分词, 提供给分词过滤器。只想应用分词过滤器,而不做任何分词操作时,它可能非常有用。
- 字母分词器:字母分词器(letter tokenizer)根据非字母的符号,将文本切分成分词。 例如,对于句子“Hi,there.”分词是Hi和there,因为逗号、空格和句号都不是字母 4、小写分词器:小写分词器(lowercase tokenizer)结合了常规的字母分词器和小写分词过滤器(如你所想,它将整个分词转化为小写)的行为。
- 空白分词器:空白分词器(whitespace tokenizer)通过空白来分隔不同的分词,空白包括空格、制表符、换行等。
- 模式分词器:模式分词器(pattern tokenizer)允许指定一个任意的模式,将文本切分为分词。被指定的模式应该匹配间隔符号。
- UAX URL电子邮件分词器:在处理英语单词的时候,标准分词器是非常好的选择。 但是,当下存在不少以网站地址和电子邮件地址结束的文本。标准分析器可能在你未注意的地方对其进行了切分。
- 路径层次分词器:路径层次分词器(path hierarchy tokenizer)允许以特定的方式索引文件系统的路径, 这样在搜索时,共享同样路径的文件将被作为结果返回。
内置的分词过滤器
- 标准分词过滤器:不要认为标准分词过滤器(standard token filter)进行了什么复杂的计算,实际上它什么事情也没做!
- 小写分词过滤器:小写分词过滤器(lowercase token filter)只是做了这件事:将任何经过的分词转换为小写。
- 长度分词过滤器:长度分词过滤器(length token filter)将长度超出最短和最长限制范围的单词过滤掉。 举个例子,如果将min设置为2,并将max设置为8,任何小于2个字符和任何大于8个字符的分词将会被移除。
- 停用词分词过滤器:停用词分词过滤器(stop token filter)将停用词从分词流中移除。
- 截断分词过滤器、修剪分词过滤器和限制分词数量过滤器: 截断分词过滤器(truncate token filter)允许你通过定制配置中的length参数,截断超过一定长度的分词。默认截断多于10个字符的部分。 修剪分词过滤器(trim token filter)删除一个分词中的所有空白部分。例如,分词”foo”将被转变为分词foo。 限制分词数量分词过滤器(limit token count token filter)限制了某个字段可包含分词的最大数量。
- 颠倒分词过滤器:颠倒分词过滤器(reverse token filter)允许处理一个分词流,并颠倒每个分词。
- 唯一分词过滤器:唯一分词过滤器(unique token filter)只保留唯一的分词,它保留第一个匹配分词的元数据,而将其后出现的重复删除
- ASCII折叠分词过滤器:ASCII折叠分词过滤器(ASCII folding token filter) 将不是普通ASCII字符的Unicode字符转化为ASCII中等同的字符,前提是这种等同存在。
- 同义词分词过滤器:同义词分词过滤器(synonym token filter)在分词流中的同样位移处,使用关键词的同义词取代原始分词。
以上是 Elasticsearch 全文搜索分析 的全部内容, 来源链接: utcz.com/p/233433.html