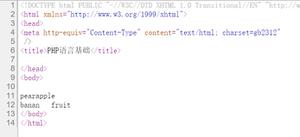
docx4j深入学习整理

引用官网上的一段话:docx4j是一个开源(ASLv2)Java库,用于创建和处理Microsoft Open XML(Word docx,Powerpoint pptx和Excel xlsx)文件。
docx4j的官网:https://www.docx4java.org/trac/docx4j
docx4j示例代码gitHub地址:https://github.com/plutext/docx4j
二、理解docx文件
1.认识Open XML
docx4j主要是针对docx文件进行操作,操作的对象的Microsoft Open XML文件。
什么是Microsoft Open XML?
还是老规矩,不懂就上官网:http://officeopenxml.com/anatomyofOOXML
Office Open XML,也称为OpenXML或OOXML,是Office文档的基础XML的格式,应用于word,execl,ppt,图表等。该规范由Microsoft开发,被ISO和IEC采纳。现在是所有Microsoft Office文档(.docx,.xlsx和.pptx)的默认格式。
2.docx文件的结构
docx我们可以理解为一个前端项目的压缩包,里面有样式文件,dom格式的xml文件,我们解压一个docx的文件看一下它的目录结构:
我们先看根目录下的[Content_Types] .xml文件,这个是整个docx文件的内容组件的配置文件,整个压缩包中用到的文件都在里面配置,可以简单理解为,我们写前端时html文件的head部分关于js,css引用的部分,但这样理解有点不明确,想象一下,jsp文件include各部分的总页面,有点类似。
_rels这个目录是配置定义各部分间的关系,了解就行,
看里面的核心word目录,可以看到,这个目录结构跟我们前端项目的html、css结构很相似,
media目录下放多媒体元素,图片之类的,了解就行
theme目录,顾名思义,word的主题,了解就行
word目录下最重要的是里面的document.xml文件
其他的word部分文件,settings.xml和styles.xml是docx文件都有的配置和样式文件,footTable是字体表,footnotes是词汇表,其他的还有foot开头的脚表,head开头的是页眉文件之类的文件
3.docx的核心OpenXML文件格式
我们主要看document.xml文件,这个文件是整个docx的骨架,类似于前端页面的html文件,是最基础、也是最重要的文件。
理解document.xml的文本结构,这个文本结构类似html格式
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><w:document>
<w:body>
<w:p></w:p>
<w:tbl></w:tbl>
<w:sectPr></w:sectPr>
</w:body>
</w:document>
(写到这突然有点不想写了.....,下面就随便记录哈了)
三、使用docx4j
1.使用的jar
maven导入
<dependency> <groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.2</version>
</dependency>
2.工具类
package com.zb.hello.util;import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.xml.bind.JAXBElement;
import javax.xml.bind.JAXBException;
import org.docx4j.XmlUtils;
import org.docx4j.dml.wordprocessingDrawing.Inline;
import org.docx4j.jaxb.XPathBinderAssociationIsPartialException;
import org.docx4j.openpackaging.exceptions.Docx4JException;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.BinaryPartAbstractImage;
import org.docx4j.wml.ContentAccessor;
import org.docx4j.wml.Drawing;
import org.docx4j.wml.ObjectFactory;
import org.docx4j.wml.P;
import org.docx4j.wml.R;
import org.docx4j.wml.Tbl;
import org.docx4j.wml.Tc;
import org.docx4j.wml.Text;
import org.docx4j.wml.Tr;
public class Docx4jUtil {
public static Builder Builder;
public static Builder of(String path) throws FileNotFoundException, Docx4JException {
return new Builder(path);
}
public static class Builder {
private WordprocessingMLPackage template = null;
private Iterator<Text> texts = null;
// 占位符参数map
private Map<String, String> params = new HashMap<>();
private Builder(String path) throws FileNotFoundException, Docx4JException {
if (path != null && !path.isEmpty()) {
this.template = WordprocessingMLPackage.load(new FileInputStream(new File(path)));
this.texts = getAllPlaceholderElementFromObject(template.getMainDocumentPart()).iterator();
}
}
/**
* 增加文本占位符参数(一个)
*
* @param key 键
* @param value 值
* @return Builder对象
*/
public Builder addParam(String key, String value) {
Builder builder = this;
if (key != null && !key.isEmpty()) {
/*while (texts.hasNext()) {
Text text = texts.next();
String temp = text.getValue();
if (temp.equals("${" + key + "}")) {
text.setValue(value);
texts.remove();
return builder;
}
}*/
params.put(key, value);
}
return builder;
}
/**
* 增加参数(多个)
*
* @param params 多个参数的map
* @return Builder对象
*/
public Builder addParams(Map<String, String> params) {
this.params = params;
return this;
}
/**
* 增加一个表格
*
* @param tablePlaceholder 寻找表格的占位符
* @param placeholderRows 模板行所占行数
* @param list 替换模板占位符的数据
* @return Builder对象
* @throws JAXBException JAXBException
* @throws Docx4JException Docx4JException
*/
public Builder addTable(String tablePlaceholder, int placeholderRows, List<Map<String, String>> list)
throws Docx4JException, JAXBException {
List<Object> tables = getAllElementFromObject(template.getMainDocumentPart(), Tbl.class);
Tbl tempTable = getTemplateTable(tables, tablePlaceholder);
if (tempTable != null && list != null && !list.isEmpty()) {
List<Object> trs = getAllElementFromObject(tempTable, Tr.class);
int rows = trs.size();
if (rows > placeholderRows) {
List<Tr> tempTrs = new ArrayList<>();
for (int i = rows - placeholderRows; i < rows; i++) {
tempTrs.add((Tr) trs.get(i));
}
for (Map<String, String> trData : list) {
for (Tr tempTr : tempTrs) {
addRowToTable(tempTable, tempTr, trData);
}
}
for (Tr tempTr : tempTrs) {
tempTable.getContent().remove(tempTr);
}
}
}
return this;
}
private void loadImg(Tbl tempTable, byte[] decodeBuffer, int maxWidth) {
Inline inline = createInlineImage(template, decodeBuffer, maxWidth);
P paragraph = addInlineImageToParagraph(inline);
List<Object> rows = getAllElementFromObject(tempTable, Tr.class);
Tr tr = (Tr) rows.get(0);
List<Object> cells = getAllElementFromObject(tr, Tc.class);
Tc tc = (Tc) cells.get(0);
tc.getContent().clear();
tc.getContent().add(paragraph);
}
/**
* 通过站位符确定加载图片的位置,图片的位置为表格
*
* @param placeholder 占位符
* @param decodeBuffer 图片的字节流
* @return 当前对象
* @throws Docx4JException Docx4JException
* @throws JAXBException JAXBException
*/
public Builder addImg(String placeholder, byte[] decodeBuffer) throws Docx4JException, JAXBException {
addImg(placeholder, decodeBuffer, 0);
return this;
}
/**
* 通过站位符确定加载图片的位置,图片的位置为表格
*
* @param placeholder 占位符
* @param decodeBuffer 图片的字节流
* @param maxWidth 图片的最多宽度,不传默认写入图片原始宽度
* @return 当前对象
* @throws Docx4JException Docx4JException
* @throws JAXBException JAXBException
*/
public Builder addImg(String placeholder, byte[] decodeBuffer, int maxWidth) throws Docx4JException, JAXBException {
List<Object> tables = getAllElementFromObject(template.getMainDocumentPart(), Tbl.class);
Tbl tempTable = getTemplateTable(tables, placeholder);
loadImg(tempTable, decodeBuffer, maxWidth);
return this;
}
/**
* 通过int的位置数组确定加载图片的位置,图片的位置为表格(以主界面为基准)
*
* @param wz int型数组,长度必须为3 ,第一个值为第几个表格,第二个值为第几行,第三个参数为第几个单元格
* @param decodeBuffer 图片的字节流
* @param maxWidth 图片的最多宽度,不传默认写入图片原始宽度
* @return 当前对象
*/
public Builder addImg(int[] wz, byte[] decodeBuffer, int maxWidth) {
Tc tc = getTcByWz(wz);
Tbl tempTable = (Tbl) getAllElementFromObject(tc, Tbl.class).get(0);
loadImg(tempTable, decodeBuffer, maxWidth);
return this;
}
/**
* 通过int的位置数组确定加载图片的位置,图片的位置为表格(以主界面为基准)
*
* @param wz int型数组,长度必须为3 ,第一个值为第几个表格,第二个值为第几行,第三个参数为第几个单元格
* @param decodeBuffer 图片的字节流
* @return 当前对象
*/
public Builder addImg(int[] wz, byte[] decodeBuffer) {
addImg(wz, decodeBuffer, 0);
return this;
}
/**
* 添加段落
*
* @param list 数据集合
* @param wz 模板段落所在的位置,长度为三(第几个表格,第几行,第几个单元格)
* @return Builder对象
*/
public Builder addParagrash(List<Map<String, String>> list, int[] wz) {
Tc tc = getTcByWz(wz);
List<Object> paraList = getAllElementFromObject(tc, P.class);
tc.getContent().clear();
for (Map<String, String> item : list) {
paraList.forEach((tempPara) -> {
P workingPara = (P) XmlUtils.deepCopy(tempPara);
repaleTexts(workingPara, item);
tc.getContent().add(workingPara);
});
}
return this;
}
/**
* 移除含有占位符的Tr
* @param placeholder 占位符
* @return Builder对象
*/
public Builder removeTrByPlaceholder(String placeholder) {
//这种方式获取是正常的,但是get()方法操作的时候不能正常替换文本了。
//List<Object> trs = template.getMainDocumentPart().getJAXBNodesViaXPath("//w:tr", true);
List<Object> trs = getAllElementFromObject(template.getMainDocumentPart(), Tr.class);
Tr tr = (Tr) getTemplateObj(trs,placeholder,false);
if(tr != null){
Tbl tbl = (Tbl) tr.getParent();
tbl.getContent().remove(tr);
}
return this;
}
/**
* 移除含有占位符的Tr
* @param placeholders 占位符的集合
* @return Builder对象
*/
public Builder removeTrByPlaceholder(List<String> placeholders) {
/* List<Object> trs = template.getMainDocumentPart().getJAXBNodesViaXPath("//w:tr", true);*/
List<Object> trs = getAllElementFromObject(template.getMainDocumentPart(), Tr.class);
List<Object> list = getTemplateObjs(trs,placeholders);
for (Object o:list) {
Tr tr = (Tr) o;
if(tr != null){
Tbl tbl = (Tbl) tr.getParent();
tbl.getContent().remove(tr);
}
}
return this;
}
/**
* 获取文件字节流
*
* @return 文件字节流
* @throws Docx4JException docx异常
*/
public byte[] get() throws Docx4JException {
if (!params.isEmpty()) {
while (texts.hasNext()) {
Text text = texts.next();
String temp = text.getValue();
for (Entry<String, String> param : params.entrySet()) {
if (temp.equals("${" + param.getKey() + "}")) {
text.setValue(param.getValue());
}
}
}
}
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
template.save(outputStream);
return outputStream.toByteArray();
}
/**
* 获取指定单元格
*
* @param temp 模板段落所在的位置,长度为三(第几个表格,第几行,第几个单元格)
* @return tc
*/
private Tc getTcByWz(int[] temp) {
List<Object> tables = getAllElementFromObject(template.getMainDocumentPart(), Tbl.class);
Tbl wzTable = (Tbl) tables.get(temp[0]);
Tr tr = (Tr) getAllElementFromObject(wzTable, Tr.class).get(temp[1]);
return (Tc) getAllElementFromObject(tr, Tc.class).get(temp[2]);
}
}
/**
* 创建包含图片的一个内联对象
*
* @param wordMLPackage WordprocessingMLPackage
* @param bytes 图片字节流
* @param maxWidth 最大宽度
* @return 图片的内联对象
*/
private static Inline createInlineImage(WordprocessingMLPackage wordMLPackage, byte[] bytes, int maxWidth) {
Inline inline = null;
try {
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage.createImagePart(wordMLPackage, bytes);
int docPrId = 1;
int cNvPrId = 2;
if (maxWidth > 0) {
inline = imagePart.createImageInline("Filename hint", "Alternative text", docPrId, cNvPrId, false, maxWidth);
} else {
inline = imagePart.createImageInline("Filename hint", "Alternative text", docPrId, cNvPrId, false);
}
} catch (Exception e) {
e.printStackTrace();
}
return inline;
}
/**
* 创建一个对象工厂并用它创建一个段落和一个可运行块R. 然后将可运行块添加到段落中. 接下来创建一个图画并将其添加到可运行块R中. 最后我们将内联
* 对象添加到图画中并返回段落对象.
*
* @param inline 包含图片的内联对象.
* @return 包含图片的段落
*/
private static P addInlineImageToParagraph(Inline inline) {
// 添加内联对象到一个段落中
ObjectFactory factory = new ObjectFactory();
P paragraph = factory.createP();
R run = factory.createR();
paragraph.getContent().add(run);
Drawing drawing = factory.createDrawing();
run.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
return paragraph;
}
// 发现docx文档包含占位符的文本节点
private static List<Text> getAllPlaceholderElementFromObject(Object obj) {
List<Text> result = new ArrayList<>();
Class<Text> toSearch = Text.class;
Text textPlaceholder;
if (obj instanceof JAXBElement) {
obj = ((JAXBElement<?>) obj).getValue();
}
if (obj.getClass().equals(toSearch)) {
textPlaceholder = (Text) obj;
if (isPlaceholder(textPlaceholder.getValue())) {
result.add((Text) obj);
}
} else if (obj instanceof ContentAccessor) {
List<?> children = ((ContentAccessor) obj).getContent();
for (Object child : children) {
result.addAll(getAllPlaceholderElementFromObject(child));
}
}
return result;
}
// 发现docx文档中的节点
private static List<Object> getAllElementFromObject(Object obj, Class<?> toSearch) {
List<Object> result = new ArrayList<>();
if (obj instanceof JAXBElement) {
obj = ((JAXBElement<?>) obj).getValue();
}
if (obj.getClass().equals(toSearch)) {
result.add(obj);
} else if (obj instanceof ContentAccessor) {
List<?> children = ((ContentAccessor) obj).getContent();
for (Object child : children) {
result.addAll(getAllElementFromObject(child, toSearch));
}
}
return result;
}
// 这个方法只是查看表格是否含有我们的占位符,如果有则返回表格
private static Tbl getTemplateTable(List<Object> tables, String templateKey) {
return (Tbl) getTemplateObj(tables,templateKey,false);
}
/**
* 这个方法只是查看dom是否含有我们的占位符,如果有则返回dom
*
* @param objects 需要查找的dom元素
* @param placeholder 占位符
* @param f 是否全部查找,为ture时全部查找,返回的是list,为false时一找到元素就返回,只是单个元素
* @return 找到的元素
*/
private static Object getTemplateObj(List<Object> objects, String placeholder, boolean f) {
List<Object> objectList = new ArrayList<>();
for (Object o : objects) {
List<?> textElements = getAllElementFromObject(o, Text.class);
for (Object text : textElements) {
Text textElement = (Text) text;
if (textElement.getValue() != null && textElement.getValue().equals("${" + placeholder + "}")) {
if (!f) {
return o;
} else {
objectList.add(o);
}
}
}
}
return objectList.isEmpty()?null:objectList;
}
/**
* 这个方法只是查看dom是否含有我们的占位符,如果有则返回dom
* @param objects 需要查找的dom元素的集合
* @param placeholders 占位符集合
* @return 找到的元素的集合
*/
private static List<Object> getTemplateObjs(List<Object> objects, List<String> placeholders) {
List<Object> objectList = new ArrayList<>();
for (Object o : objects) {
List<?> textElements = getAllElementFromObject(o, Text.class);
for (Object text : textElements) {
Text textElement = (Text) text;
if (textElement.getValue() != null && placeholders.contains(getPlaceholderStr(textElement.getValue()))) {
objectList.add(o);
}
}
}
return objectList;
}
/**
* 复制模板行
*
* @param reviewtable 表格
* @param templateRow 模板行
* @param replacements 填充模板行的数据
*/
private static void addRowToTable(Tbl reviewtable, Tr templateRow, Map<String, String> replacements) {
Tr workingRow = XmlUtils.deepCopy(templateRow);
repaleTexts(workingRow, replacements);
reviewtable.getContent().add(workingRow);
}
/**
* 把工作对象中的全部占位符都替换掉
*
* @param working 工作对象
* @param replacements map数据对象
*/
private static void repaleTexts(Object working, Map<String, String> replacements) {
List<?> textElements = getAllElementFromObject(working, Text.class);
for (Object object : textElements) {
Text text = (Text) object;
String keyStr = getPlaceholderStr(text.getValue());
if (keyStr != null && !keyStr.isEmpty()) {
String replacementValue = replacements.get(keyStr);
if (replacementValue != null) {
text.setValue(replacementValue);
} else {
text.setValue("--");
}
}
}
}
/**
* 判断字符串是否有${}占位符
*
* @param str 需要判断的字符串
* @return 是否字符串是否有${}占位符
*/
private static boolean isPlaceholder(String str) {
if (str != null && !str.isEmpty()) {
Pattern pattern = Pattern.compile("([$]\{\w+\})");
Matcher m = pattern.matcher(str);
return m.find();
}
return false;
}
/**
* 得到占位符${}中的文本
*
* @param str 需要判断的字符串
* @return 占位符${}中的文本
*/
private static String getPlaceholderStr(String str) {
if (str != null && !str.isEmpty()) {
Pattern p = Pattern.compile("\$\{(.*?)\}");
Matcher m = p.matcher(str);
if (m.find()) {
return m.group(1);//m.group(0)包括这两个字符
}
}
return null;
}
}
3.导出word文件使用
public byte[] downloadWord() throws Docx4JException, JAXBException, FileNotFoundException { //模板文件路径
String path = this.getClass().getClassLoader().getResource("template/test.docx").getPath();
//模板中要生成表格的数据
List<Map<String, String>> list = new ArrayList<>();
for (int i = 0; i < 3; i++) {
Map<String, String> m = new HashMap<>();
m.put("name", "姓名"+i);
m.put("sex", "性别"+i);
m.put("age", "年龄"+i);
m.put("bz", "备注"+i);
m.put("xx", "详细"+i);
list.add(m);
}
list.stream();
//模板中要插入图片的数据
byte[] img = null;
try (InputStream input = new FileInputStream(this.getClass().getClassLoader().getResource("template/timg.jpg").getPath())){
img = new byte[input.available()];
input.read(img);
} catch (Exception e) {
e.printStackTrace();
}
//要插入的map数据
Map<String, String> m = new HashMap<>();
m.put("today", LocalDate.now().toString());
m.put("active", "游泳");
//处理好数据后就是超级简单的调用
return Docx4jUtil.of(path)
.addParam("title", "测试文档标题")
.addParam("user", "测试人")
.addParams(m)
.addTable("name", 2, list)
.addImg("img", img)
.get();
}
四、扩展
1.word转html
使用poi的maven
<!-- word转html的poi --> <dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>xdocreport</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi-version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi-version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi-version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>${poi-version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.18</version>
</dependency>
2.工具类
package com.zb.hello.util;import fr.opensagres.poi.xwpf.converter.xhtml.Base64EmbedImgManager;
import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLConverter;
import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLOptions;
import org.apache.commons.codec.binary.Base64;
import org.apache.poi.hwpf.HWPFDocumentCore;
import org.apache.poi.hwpf.converter.PicturesManager;
import org.apache.poi.hwpf.converter.WordToHtmlConverter;
import org.apache.poi.hwpf.converter.WordToHtmlUtils;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.w3c.dom.Document;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class WordHtmlUtil {
//doc转换html
public static String docToHtml(File file) throws IOException, ParserConfigurationException, TransformerException {
HWPFDocumentCore wordDocument = WordToHtmlUtils.loadDoc(new FileInputStream(file));
WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter(
DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument()
);
PicturesManager pictureRunMapper = (bytes, pictureType, s, v, v1) -> "data:image/png;base64,"+Base64.encodeBase64String(bytes);
wordToHtmlConverter.setPicturesManager(pictureRunMapper);
wordToHtmlConverter.processDocument(wordDocument);
Document htmlDocument = wordToHtmlConverter.getDocument();
ByteArrayOutputStream out = new ByteArrayOutputStream();
DOMSource domSource = new DOMSource(htmlDocument);
StreamResult streamResult = new StreamResult(out);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer serializer = transformerFactory.newTransformer();
serializer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
serializer.setOutputProperty(OutputKeys.INDENT, "yes");
serializer.setOutputProperty(OutputKeys.METHOD, "html");
serializer.transform(domSource, streamResult);
out.close();
return new String(out.toByteArray());
}
//docx转换html
public static String docxToHtml(File file) throws IOException {
XWPFDocument docxDocument = new XWPFDocument(new FileInputStream(file));
XHTMLOptions options = XHTMLOptions.create();
//图片转base64
options.setImageManager(new Base64EmbedImgManager());
// 转换htm11
ByteArrayOutputStream htmlStream = new ByteArrayOutputStream();
XHTMLConverter.getInstance().convert(docxDocument, htmlStream, options);
htmlStream.close();
return new String(htmlStream.toByteArray());
}
}
以上是 docx4j深入学习整理 的全部内容, 来源链接: utcz.com/z/514161.html