8.hbase写入流程和读取流程

1 hbase写入流程
hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 MemStore,hbase默认把数据先写到这两个地方,只有这两个地方的变化都写入并确认后,才认为写动作完成。
MemStore是内存中的缓冲区默认64m,HBase会把要写入的数据在这里积累,当填满后 才进行刷写到硬盘上,生成一个HFile。
WAL 使用来排除故障,大型分布式系统,节点故障很常见,设想如果MemStore没有写满刷写到硬件上,那么内存中的数据就会丢失,应对办法就是将数据在写动作完成前就写入WAL,每台节点维护一个WAL,直到WAL写入成功,写动作才算完成。
同时,如果节点宕机恢复,MemStore里的数据会被自动从WAL中恢复到内存中
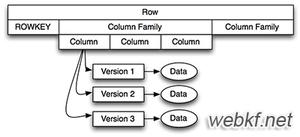
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。
事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。
StoreFile以HFile格式保存在HDFS上
2 hbase读取流程
如果想快速访问,通用的原则是,尽可能多的把数据有序,并且放到内存中,hbase实现了这两个要求,所以大多数情况下操作可以做到毫秒级。
Hbase读取工作必须要连接硬盘,所以hbase中设计了一个BlockCache缓存,用来保存从HFile中读入内存中最频繁的数据,避免硬盘读。
从Hbase中读取一行,首先检查MemStore等待修改的队列,然后检查BlockCache包含改行的Block是否最近被访问过,最后访问硬盘上对应的HFile。
3 delete的工作原理以及hbase合并的后台工作
delete并不是把数据真的删除了,而是添加了一个墓被标记,代表此数据被删除掉,直到hbase执行大合并,才会真的从hfile中删除数据
大合并和小合并 HFile
小合并,读取完整一行,可能需要很多HFile,把这些Hfile合并成一个HFile,提高了读取一行的速度
大合并,把一个列族的所有HFile合并成一个文件,便于浏览该列族所有内容
小合并是轻量级的,可以频繁操作(hbase自身控制),大合并是重量级的,不要经常使用,而且是HBase清理删除数据
以上是 8.hbase写入流程和读取流程 的全部内容, 来源链接: utcz.com/z/509600.html