Hbase入门详解
1、hbase概述
1.1 hbase是什么
hbase是基于hdfs进行数据的分布式存储,具有高可靠、高性能、列存储、可伸缩、实时读写的nosql数据库。
hbase可以存储海量的数据,并且后期查询性能很高,可以实现上亿条数据的查询秒级返回结果。
1.2 hbase表的特性
1、大
- hbase表可以存储海量的数据。
2、无模式
- mysql表中每一行列的字段是相同,而hbase表中每一行数据可以有截然不同的列。
3、面向列
- hbase表中的数据可以有很多个列,后期它就是按照不同的列去存储数据,写入到不同的文件中。
- 面向列族进行存储数据。
4、稀疏
- 在hbase表中为null的列并不占用实际的存储空间。
5、数据的多版本
- 对于hbase表中的数据在进行数据更新的时候,它并没有把之前的结果数据直接删除掉,而是保留数据的多个版本,每一个数据都给一个版本号,这个版本号就是按照我们插入数据的时间戳去确定。
6、数据类型单一
- 无论是什么类型的数据,最后都被转换成了字节数组存储在hbase表中
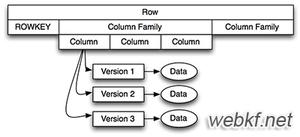
1.3 hbase表的逻辑视图
2、hbase的集群结构
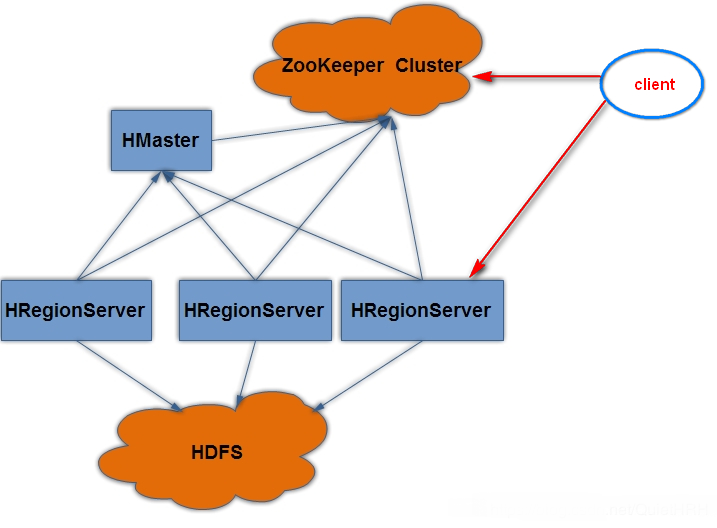
1、client
- 提供了对hbase表操作的一些java接口。
- client 维护着一些 cache 来加快对 hbase 的访问
- client 会将查询过的位置信息保存缓存起来,缓存不会主动失效
2、zookeeper
客户端操作hbase表数据需要一个zk集群
作用
1、zk保存了hbase集群的元数据信息
存储 Hbase 的 schema,包括有哪些 table,每个 table 有哪些 column family
2、zk保存所有hbase表的寻址入口
后期通过客户端接口去操作hbase数据的时候,需要连接上zk集群
存贮所有 Region 的寻址入口----root 表在哪台服务器上
3、通过引入了zk之后,实现了整个hbase集群高可用
4、zk保存了HMaster和HRegionServer它们的注册和心跳信息
后期哪一个HRegionServer挂掉之后,zk也会感知到,然后把这个信息通知给老大HMaster
3、HMaster
它是整个hbase集群老大
作用
1、它接受客户端创建表、删除表的请求。处理 schema 更新请求
2、它会给HRegionServer分配对应的region,进行数据的管理
3、它会把挂掉的HRegionServer所管理的region重新分配给其他的活着的HRegionServer
4、它会实现HRegionServer负载均衡,避免某一个HRegionServer管理的region过多。
4、HRegionServer
它是整合hbase集群的小弟
作用
1、负责管理HMaster老大给它分配的region
2、它会接受到客户端的读写请求
3、它会把在运行过程中,变得过大的region数据进行切分
5、Region
它是整个hbase表中分布式存储的最小单元
它的数据是基于hdfs进行存储
3、hbase集群安装部署
前提条件
- 先搭建好zk、hadoop集群
1、下载对应的安装包
- http://archive.apache.org/dist/hbase/1.2.1/hbase-1.2.1-bin.tar.gz
- hbase-1.2.1-bin.tar.gz
2、规划安装目录
- /export/servers
3、上传安装包到服务器中
4、解压安装包到指定的规划目录
- tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers
5、重命名解压目录
- mv hbase-1.2.1 hbase
6、修改配置文件
需要把hadoop安装目录下/etc/hadoop文件夹中
- core-site.xml
- hdfs-site.xml
需要把以上2个hadoop的配置文件拷贝到hbase安装目录下的conf文件夹中
1、vim hbase-env.sh
#配置java环境变量
export JAVA_HOME=/export/servers/jdk
#指定hbase集群由外部的zk集群去管理,不在使用自带的zk集群
export HBASE_MANAGES_ZK=false
2、vim hbase-site.xml
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
3、vim regionservers
#指定哪些节点是HRegionServer
node2
node3
4、vim backup-masters
#指定哪些节点是备用的Hmaster
node2
7、配置hbase环境变量
vim /etc/profile
export HBASE_HOME=/export/servers/hbase
export PATH=$PATH:$HBASE_HOME/bin
8、分发hbase目录和环境变量
scp -r hbase node2:/export/servers
scp -r hbase node3:/export/servers
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc
9、让所有hbase节点的环境变量生效
在所有节点上执行
- source /etc/profile
4、hbase集群的启动和停止
1、启动hbase集群
先启动zk和hadoop集群
然后通过hbase/bin
start-hbase.sh
- 你在哪里启动这个脚本,首先在当前机器启动一个HMaster进程(它就是活着的HMaster)
- 通过regionservers文件在对应的节点来启动HRegionServer
- 通过backup-masters文件在对应的节点来启动备用的HMaster
2、停止hbase集群
通过hbase/bin
stop-hbase.sh
hbase集群web管理界面
1、启动好hbase集群之后
访问地址
HMaster主机名:16010
5、hbase shell 命令行操作
hbase/bin/hbase shell 进入到hbase shell客户端命令操作
1、创建一个表
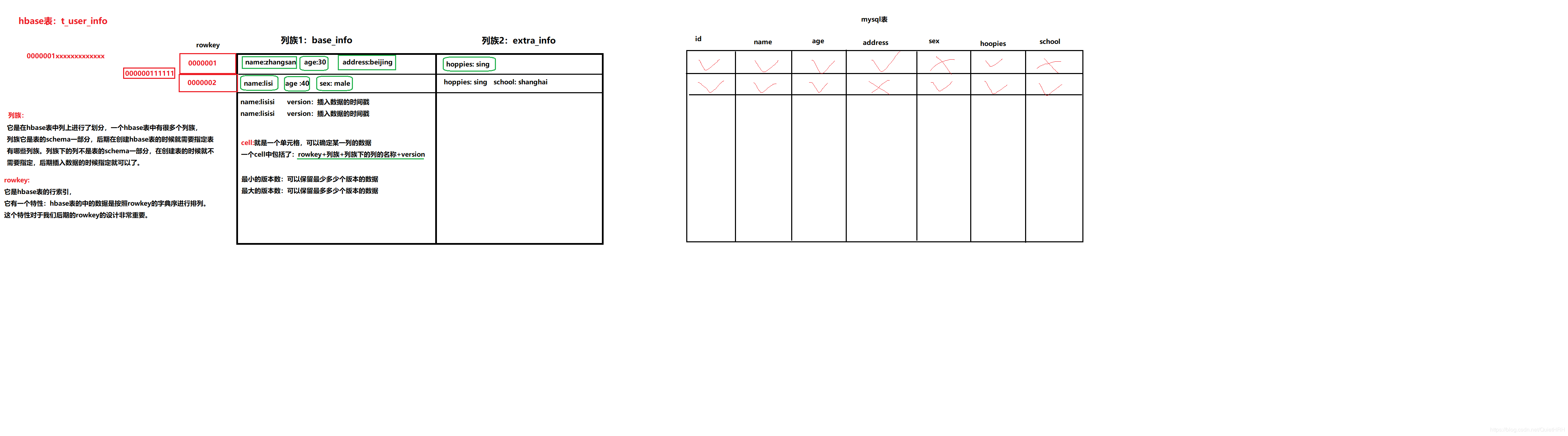
create 't_user_info','base_info','extra_info'
create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
2、查看有哪些表
list
类似于mysql表中sql:show tables
3、查看表的描述信息
describe 't_user_info'
4、修改表的属性
#修改列族的最大版本数
alter 't_user_info', NAME => 'base_info', VERSIONS => 3
5、添加数据到表中
put 't_user_info','00001','base_info:name','zhangsan'
put 't_user_info','00001','base_info:age','30'
put 't_user_info','00001','base_info:address','beijing'
put 't_user_info','00001','extra_info:school','shanghai'
put 't_user_info','00002','base_info:name','lisi'
6、查询表的数据
//按照条件查询
get 't_user_info','00001'
get 't_user_info','00001', {COLUMN => 'base_info'}
get 't_user_info','00001', {COLUMN => 'base_info:name'}
get 't_user_info','00001',{TIMERANGE => [1544243300660,1544243362660]}
get 't_user_info','00001',{COLUMN => 'base_info:age',VERSIONS =>3}
//全表查询
scan 't_user_info'
7、删除数据
delete 't_user_info','00001','base_info:name'
deleteall 't_user_info','00001'
8、删除表
disable 't_user_info'
drop 't_user_info'
6、hbase的内部原理
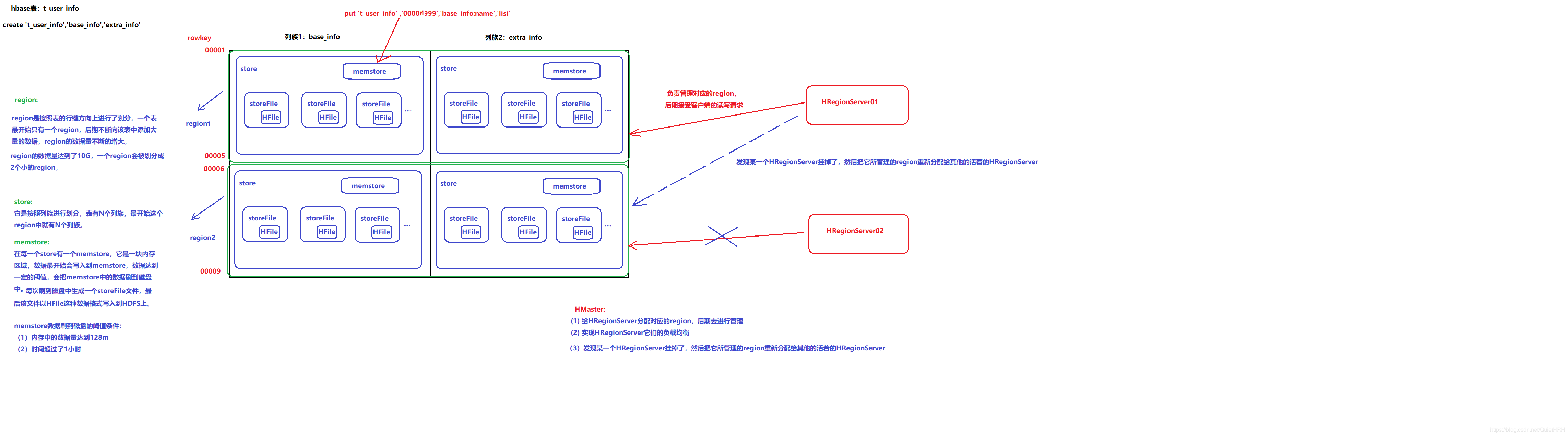
- Table 中的所有行都按照 row key 的字典序排列
- Table 在行的方向上分割为多个 Hregion
- region 按大小分割的(默认 10G),每个表一开始只有一个 region , region 不断增大,当增大到一个阀值的时候,Hregion 就会等分会两个新的 Hregion。当 table中的行不断增多,就会有越来越多Hregion。
- Hregion 是 Hbase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 Hregion可以分布在不同的 HRegion server 上。
- HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。HRegion 由一个或者多个 Store 组成,每个 store 保存一个 column family。每个 Strore 又由一个 memStore 和 0 至多个 StoreFile 组成。写操作先写入 memstore,当 memstore 中的数据量达到某个阈值(默认128M或1个小时),Hregionserver 启动flashcache 进程写入 storefile,每次写入形成单独一个 storefile。
- 当 storefile 的个数超过一定阈值后(默认参数 hbase.hstore.blockingStoreFiles=10),多个storeFile会进行合并,当该region的所有store的storefile大小之和,即所有store的大小超过 hbase.hregion.max.filesize=10G 时,这个 region 会被拆分会把当前的 region分割成两个,并由 Hmaster 分配给相应的 region 服务器,实现负载均衡。
- 每个 HRegionServer 中都有一个 HLog 对象,HLog 是一个实现 Write Ahead Log 的类,在每次用户操作写入 MemStore 的同时,也会写一份数据到 HLog 文件中, HLog 文件定期会滚动出新的,并删除旧的文件(已持久化到 StoreFile 中的数据)。当 HRegionServer 意外终止后,HMaster 会通过 Zookeeper 感知到,HMaster 首先会处理遗留的 HLog 文件,将其中不同 Region 的 Log 数据进行拆分,分别放到相应 region 的目录下,然后再将失效的 region 重新分配,领取到这些 region 的 HRegionServer 在 Load Region的过程中,会发现有历史 HLog 需要处理,因此会 Replay HLog 中的数据到 MemStore 中,然后 flush 到 StoreFiles,完成数据恢复。
7、hbase的寻址机制

寻找 RegionServer
- ZooKeeper–> -ROOT-(单 Region)–> .META.–> 用户表
-ROOT-表
- 表包含.META.表所在的 region 列表,该表只会有一个 Region;
- root region 永远不会被 split,保证了最多需要三次跳转,就能定位到任意 region 。
- Zookeeper 中记录了-ROOT-表的 location。
.META.表
- 表包含所有的用户空间 region 列表,以及 RegionServer 的服务器地址
- .META.表每行保存一个 region 的位置信息,row key 采用表名+表的最后一行编码而成。
- 为了加快访问,.META.表的全部 region 都保存在内存中。
联系 regionserver 查询目标数据
regionserver 定位到目标数据所在的 region,发出查询请求
region 先在 memstore 中查找,命中则返回
如果在 memstore 中找不到,则在 storefile 中扫描(可能会扫描到很多的 storefile----bloomfilter 布隆过滤器)布隆过滤器可以快速的返回查询的rowkey是否在这个storeFile中, 但也有误差, 如果返回没有,则一定没有,如果返回有, 则可能没有
8、Hbase高级应用
建表
BLOOMFILTER 默认是 Row 布隆过滤器
- 对 ROW,行键的哈希在每次插入行时将被添加到布隆。
- 对 ROWCOL,行键 + 列族 + 列族修饰的哈希将在每次插入行时添加到布隆
VSRSIONS 默认是 1 数据版本
- 如果我们认为我们的数据没有这么大的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为 1 能节约 2/3 的空间
COMPRESSION 默认值是 NONE 压缩
- GZIP / LZO / Zippy / Snappy
disable_all ‘toplist.*' disable_all 支持正则表达式,并列出当前匹配的表 drop_all也相同
hbase 表预分区----手动分区
一种可以加快批量写入速度的方法是通过预先创建一些空的 regions,这样当数据写入 HBase时,会按照 region 分区情况,在集群内做数据的负载均衡。减少数据达到 storefile 大小的时候自动分区的
时间消耗,并且还有以一个优势,就是合理设计 rowkey 能让各个 region 的并发请求平均分配(趋于均匀) 使 IO 效率达到最高,
行键设计
列族尽量少, 一般2-3个
rowkey
- 根据字典序的特性, 将需要批量查询的数据尽可能连续存放( 矛 )
- 尽可能将查询条件关键词拼装到 rowkey 中,查询频率最高的条件尽量往前靠
- rowkey建议越短越好,不要超过 16 个字节
尽量减少行键和列族的大小在 HBase 中,value 永远和它的 key 一起传输的
HFile中每个cell都会存储rowkey, rowkey过大会影响存储效率
MemStore 将缓存部分数据到内存,如果 rowkey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
建议将 rowkey 的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个 RegionServer,以实现负载均衡的几率。( 盾 )
rowkey矛盾
- HBase 中的行是按照 rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于 scan。然而糟糕的rowkey 设计是热点的源头。
热点解决
- 加盐 在rowkey前加随机字符串
- 哈希 哈希会使同一行永远用一个前缀加盐
- 反转 反转固定长度或者数字格式的 rowkey 牺牲了rowkey的有序性
- 时间戳反转
可以用 Long.Max_Value - timestamp 追加到 key 的末尾,例如 [key][reverse_timestamp] ,[key] 的最新值可以通过 scan [key]获得[key]的第一条记录,因为 HBase 中 rowkey 是有序的,第一条记录是最后录入的数据。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。如果你想了解更多相关内容请查看下面相关链接
以上是 Hbase入门详解 的全部内容, 来源链接: utcz.com/p/225656.html