什么是数据离散化?
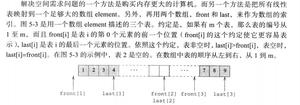
数据离散化技术可用于通过将属性的范围划分为多个区间来减少给定连续属性的值数量。区间标签可用于恢复实际数据值。它可以用少量的区间标签恢复一个连续属性的多个值,从而减少和简化原始信息。
这导致了挖掘结果的简洁、易于使用、知识级别的表示。离散化技术可以根据离散化的实现方式进行分类,例如它是否使用类数据或它进行的方向(即,自上而下与自下而上)。如果离散化过程使用类数据,那么可以说它是有监督的离散化。因此,它是无监督的。
如果该过程首先发现一个或几个点(称为分割点或切割点)以分割整个属性范围,然后在结果区间上递归地继续此过程,则称为自顶向下离散化或分割。
在自下而上的离散化或合并中,它可以首先将所有连续值视为潜在的分裂点,通过合并邻域值以形成区间来移除一些,然后将此过程递归应用于结果区间。离散化可以在属性上递归实现,以支持属性值的分层或多分辨率分区,称为概念层次结构。
概念层次结构对于在多个抽象级别进行挖掘很有用。给定数值属性的概念层次表示属性的离散化。概念层次结构可用于通过收集和恢复低级概念(包括属性年龄的数值)和高级概念(包括青年、中年或高级)来减少数据。尽管这种数据泛化隐藏了细节,但泛化数据可能更有意义且更易于执行。
这在多个挖掘任务之间提供了对数据挖掘结果的一致描述,这是一个常见的要求。此外,在简化的数据集上进行挖掘需要更少的输入/输出操作,并且比在更高的、非一般化的数据集上进行挖掘更有能力。由于这些优点,离散化技术和概念层次结构通常在数据挖掘之前作为预处理步骤使用,而不是在挖掘过程中使用。
几种离散化方法可用于自动生成或动态优化数值属性的概念层次结构。此外,分类属性的许多层次结构在数据库设计中是隐含的,可以在模式定义级别自动表示。
以上是 什么是数据离散化? 的全部内容, 来源链接: utcz.com/z/361975.html