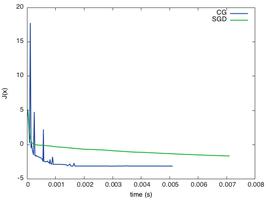
pytorch实现对输入超过三通道的数据进行训练
案例背景:视频识别
假设每次输入是8s的灰度视频,视频帧率为25fps,则视频由200帧图像序列构成.每帧是一副单通道的灰度图像,通过pythonb里面的np.stack(深度拼接)可将200帧拼接成200通道的深度数据.进而送到网络里面去训练.
如果输入图像200通道觉得多,可以对视频进行抽帧,针对具体场景可以随机抽帧或等间隔抽帧.比如这里等间隔抽取40帧.则最后输入视频相当于输入一个40通道的图像数据了.
pytorch对超过三通道数据的加载:
读取视频每一帧,转为array格式,然后依次将每一帧进行深度拼接,最后得到一个40通道的array格式的深度数据,保存到pickle里.
对每个视频都进行上述操作,保存到pickle里.
我这里将火的视频深度数据保存在一个.pkl文件中,一共2504个火的视频,即2504个火的深度数据.
将非火的视频深度数据保存在一个.pkl文件中,一共3985个非火的视频,即3985个非火的深度数据.
数据加载
import torch
from torch.utils import data
import os
from PIL import Image
import numpy as np
import pickle
class Fire_Unfire(data.Dataset):
def __init__(self,fire_path,unfire_path):
self.pickle_fire = open(fire_path,'rb')
self.pickle_unfire = open(unfire_path,'rb')
def __getitem__(self,index):
if index <2504:
fire = pickle.load(self.pickle_fire)#高*宽*通道
fire = fire.transpose(2,0,1)#通道*高*宽
data = torch.from_numpy(fire)
label = 1
return data,label
elif index>=2504 and index<6489:
unfire = pickle.load(self.pickle_unfire)
unfire = unfire.transpose(2,0,1)
data = torch.from_numpy(unfire)
label = 0
return data,label
def __len__(self):
return 6489
root_path = './datasets/train'
dataset = Fire_Unfire(root_path +'/fire_train.pkl',root_path +'/unfire_train.pkl')
#转换成pytorch网络输入的格式(批量大小,通道数,高,宽)
from torch.utils.data import DataLoader
fire_dataloader = DataLoader(dataset,batch_size=4,shuffle=True,drop_last = True)
模型训练
import torch
from torch.utils import data
from nets.mobilenet import mobilenet
from config.config import default_config
from torch.autograd import Variable as V
import numpy as np
import sys
import time
opt = default_config()
def train():
#模型定义
model = mobilenet().cuda()
if opt.pretrain_model:
model.load_state_dict(torch.load(opt.pretrain_model))
#损失函数
criterion = torch.nn.CrossEntropyLoss().cuda()
#学习率
lr = opt.lr
#优化器
optimizer = torch.optim.SGD(model.parameters(),lr = lr,weight_decay=opt.weight_decay)
pre_loss = 0.0
#训练
for epoch in range(opt.max_epoch):
#训练数据
train_data = Fire_Unfire(opt.root_path +'/fire_train.pkl',opt.root_path +'/unfire_train.pkl')
train_dataloader = data.DataLoader(train_data,batch_size=opt.batch_size,shuffle=True,drop_last = True)
loss_sum = 0.0
for i,(datas,labels) in enumerate(train_dataloader):
#print(i,datas.size(),labels)
#梯度清零
optimizer.zero_grad()
#输入
input = V(datas.cuda()).float()
#目标
target = V(labels.cuda()).long()
#输出
score = model(input).cuda()
#损失
loss = criterion(score,target)
loss_sum += loss
#反向传播
loss.backward()
#梯度更新
optimizer.step()
print('{}{}{}{}{}'.format('epoch:',epoch,',','loss:',loss))
torch.save(model.state_dict(),'models/mobilenet_%d.pth'%(epoch+370))
RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'target'
解决方案:target = target.long()
以上这篇pytorch实现对输入超过三通道的数据进行训练就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
以上是 pytorch实现对输入超过三通道的数据进行训练 的全部内容, 来源链接: utcz.com/z/336069.html