为什么用jsoup抓取网页,返回的html不全

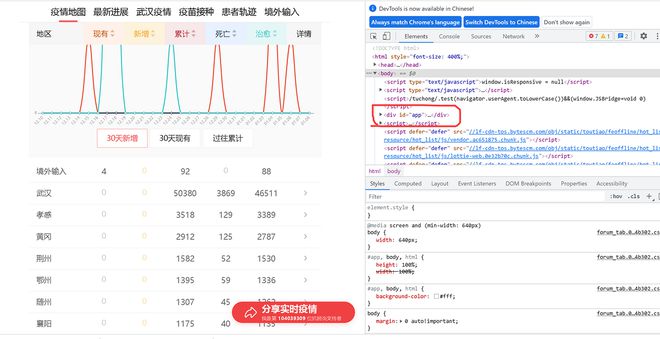
想问下为什么java用jsuop包解析网页的html代码中<div id = "app">...</div>中间部分缺失。代码如下:
import org.jsoup.Jsoup;import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class test {
public static void main(String[] args) throws IOException {
//获取请求
//前提 需要联网
String url = "https://i.snssdk.com/ugc/hotboard_fe/hot_list/template/hot_list/forum_tab.html";
//解析网页(Jsoup返回Document就是浏览器Document对象)
Document document = Jsoup.connect(url).timeout(5000000).maxBodySize(0).get();
System.out.println(document.html());
// System.out.println(document.html());
Element element = document.getElementById("app");
Elements elements = element.getElementsByTag("div");
// Elements elements = document.getElementsByClass("area-chart-table-row");
for (Element e1 : elements) {
System.out.println(e1);
}
// System.out.println(element);
//获取所有的li标签
// Elements elements = element.getElementsByTag("div");
//获取元素的内容
// for (Element e1 : elements) {
// String img = e1.getElementsByTag("img").eq(0).attr("source-data-lazy-img");
// String price = e1.getElementsByClass("area-chart-header-item confirmed-province").eq(0).text();
// String title = e1.getElementsByClass("p-name").eq(0).text();
// System.out.println("============================================");
// System.out.println(img);
// System.out.println(price);
// System.out.println(title);
// }
}
}
解析的网页地址为https://i.snssdk.com/ugc/hotb...
回答:
这是js渲染的,你右键查看源码,是真正的html代码,那个div是不含内容的。
浏览器加载js后,js渲染的html。
这种抓数据反而简单,直接抓接口就行,连解析都不需要。
回答:
React单页面应用;是在浏览器中渲染出来的;<div id = "app">...</div>中间的内容是在浏览器中渲染出来的,直接通过url获取的html缺少浏览器渲染
以上是 为什么用jsoup抓取网页,返回的html不全 的全部内容, 来源链接: utcz.com/p/944164.html