PyTorch中如何从数据集中连续读入两张3通道图片,并将它们合并为一张6通道图片作为一个训练样本?
我是一个刚开始深度学习与python的大二学生,正在完成老师布置的第一个大作业:一个基于ResNet-34的叶片分类系统,老师给我提供了一个包含了多类图片的数据集,组织方式如下所示,
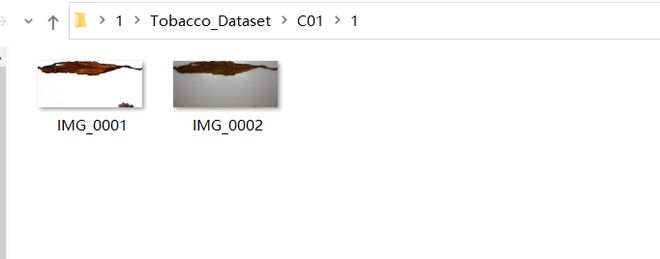
每个类别的文件夹下有一些图像对,对应同一片叶子在不同光线下的两张图片。
而我在训练的时候为了读取数据方便,把同一类别的图片都拿出来了,如图所示:
通过这样的方式我成功用搭建的模型完成了训练,但是准确率很低,仅有50%左右,老师说我一张一张训练的方式不对,这样把同一片叶子看做了两个不同的样本,导致精确度低,我应该每次读入两张图片(同一片叶子的图像对),将这两张图片合并成一张六通道的图作为一个样本训练才行。
现在我一筹莫展,一是不知道怎么样一次读入两张图片,而是不知道怎么把它们合成六通道图片来训练,因此过来向大家求助,我要怎样修改我的代码,是否要修改我的resnet网络结构?
我的训练代码如图所示,真诚希望能获得您的帮助。
import osimport sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
import time
from torchvision import transforms, datasets
from tqdm import tqdm
from visdom import Visdom
from model import resnet34
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "tobacco_data") # tobacco data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
tobacco_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in tobacco_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 14)
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
viz = Visdom() #监听窗口初始化
viz.line([0.],[0.],win='train_loss',opts=dict(title='train loss'))
viz.line([[0.0,0.0]],[0.],win='test',opts=dict(title='test loss&acc.',legend=['loss','acc.']))
global_step = 0
epochs = 540
best_acc = 0.0
save_path = './resNet34.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
viz.line([[running_loss,val_accurate]],[global_step], win='test', update='append')
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
回答:
倒感觉是你的训练集图片太少了,要是合成一张告诉训练模型 那搞出来的训练模型不就只能识别出一个光线下的,应该是加大不同光线下的同类图片给训练模型。
或者你们的题目只是作业:考深度学习与图片处理,要是验证图片光线是两张图片的中合那有点验证了我的猜想
以上是 PyTorch中如何从数据集中连续读入两张3通道图片,并将它们合并为一张6通道图片作为一个训练样本? 的全部内容, 来源链接: utcz.com/p/938440.html