有一个比较大的文件,怎样用chardet快速判断编码方式?
有一个csv文件,比较大几百兆,读起来比较耗时间。知道这个文件有可能是GBK方式编码,也有可能是utf-8编码,编码方式不能确定。怎样用读取一小部分文件,用chardet判断是哪种编码方式,再用pd.read_csv(xxx,encoding='utf-8')或者pd.read_csv(xxx,encoding='GBK')读取。
主要的诉求是:不要读完整的文件,
with open(os.path.join(data_dir,reach_data_f),'rb') as f: t=chardet.detect(f.read())
代码方式可行,但是速度太慢,怎样优化?谢谢
读取1024字节有问题,
with open(os.path.join(data_dir,qdjf_data_f),'rb') as f: t=chardet.detect(f.read(1024))
正确的结果应该是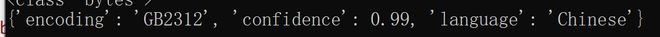
回答:
不检测编码直接
try: pd.read_csv(xxx,encoding='utf-8')
except:
pd.read_csv(xxx,encoding='GBK')
以上是 有一个比较大的文件,怎样用chardet快速判断编码方式? 的全部内容, 来源链接: utcz.com/p/938439.html