
在python爬虫里, 如何提取一个页面内的多个图片链接?
最近在网上找了个教程学习python爬虫, 遇到一个问题, 如下:
- 页面 https://mmzztt.com/photo/62578
- 这个页面有很多张图片
- 这些图片的浏览形式是, 点击图片左侧-上一张, 点击右侧-下一张,似乎是用js控制.
- 不像常规页面那样, 所有图片都可以通过循环拼接截取得到完整的链接.
像这种情况, 如何提取一个页面内的多个图片链接呢?
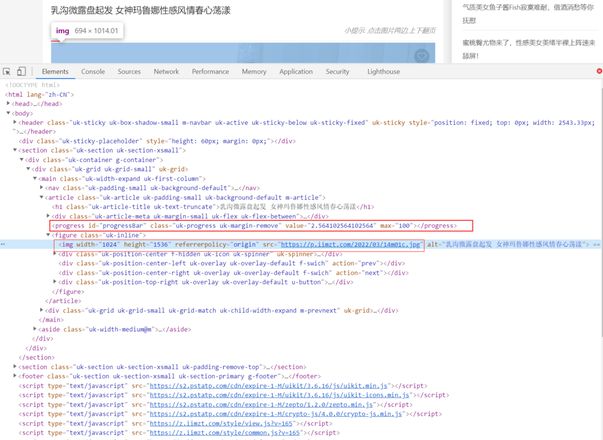
回答:
可以根据上一级路由入手,一次采集多张图片+翻页做到批量采集
回答:
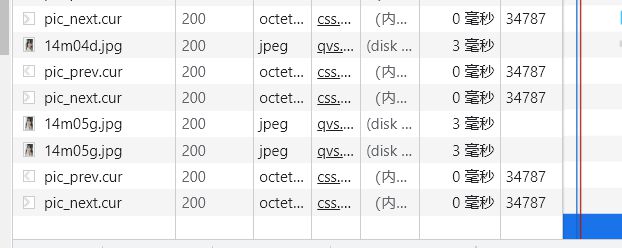
可以看得出来该网站使用js分次请求图片
并且请求的图片格式为"图集ID+m+图片ID+随机字母.jpg"
提一个比较麻烦的方法,根据网络请求获取到该图集的图集ID,然后循环从0开始,使用requests把每一个字母都试一遍,返回403(这个网站只返回403)就跳过,返回200就是正确的图片)
(还有老哥注意身体)
以上是 在python爬虫里, 如何提取一个页面内的多个图片链接? 的全部内容, 来源链接: utcz.com/p/938363.html





