BeautifulSoup get id failed
试以
https://www.cnblogs.com/muche...
为例子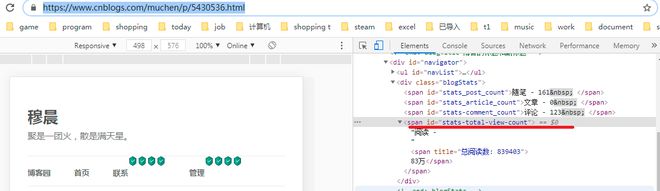
我想抓取总阅读量
结果总是是空的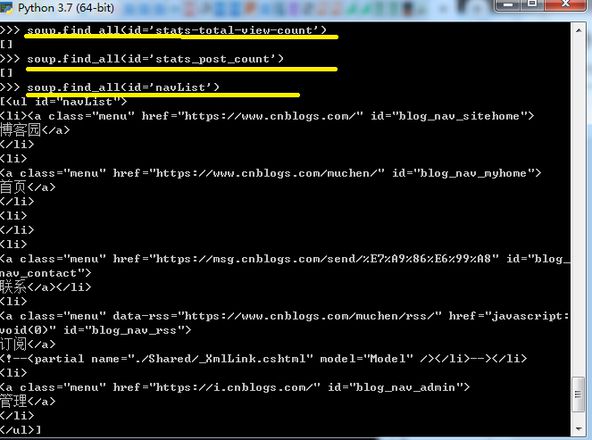
抓取不带破折号的就正常
python里面破折号还有区分?
谢谢。
回答:
差错的步骤首先需要检查你获取的数据是不是对的。你的代码里根本就没有阅读那些标签,可以打印出来看一下。我看了一下网页,那些数据都是通过接口单独获取并渲染的不是在html里面。
以上是 BeautifulSoup get id failed 的全部内容, 来源链接: utcz.com/p/937917.html