新手请教, python status code 302 不能够抓取登录後的网页内容
大家好, 我写了一段python代码, 想用来爬取登录後的网页内容.
我尝试过爬一些网站是可以成功抓取的, 但是我自己公司的网站, 却不能够抓取, 然后我看了chrome里面的后台提交信息, 发现那个status_code是302, 大概是重定向的意思, 请问我抓取不了是跟这个有关系吗? 谢谢!
不好意思, 因为这个网站是我公司的网, 所以我就把它屏蔽掉了.
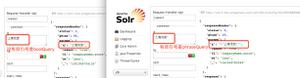
第一张图片是我第一个抓取到的login内容
第二张图片是我第二个抓取到的内容, 不肯定作用是什么

")
import requestsrequests.packages.urllib3.disable_warnings();
session = requests.Session();
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
}
data = {
'ctl00$phContentMain$txtLoginID': 'myLoginName',
'ctl00$phContentMain$txtPassword': 'myPassword'
}
login_url ='https://www.myWebSite.com/HPD/Login.aspx';
session.post(login_url,data=data,headers=headers,verify=False);
url2 = 'https://www.myWebSite.com/HPD/default.aspx';
response = session.get(url2);
print(response.text);
回答:
原来是因为这个网页是aspx的缘故, form data会比平常的多
而且网页中有一个hidden的数据, 需要从网页中获取然后在放在data里面提交才可以登录
回答:
session.post(login_url,data=data,headers=headers,verify=False);改为:`
session.post(login_url,data=data,headers=headers,verify=False,allow_redirects=False);
以上是 新手请教, python status code 302 不能够抓取登录後的网页内容 的全部内容, 来源链接: utcz.com/p/937766.html