下面的多线程爬虫程序错在哪里?

程序目的是采用多线程的方式,爬取斗图啦前100页的所有表情包。
我采用的是多线程的方式,
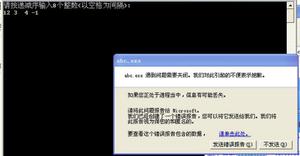
第一次运行的时候,程序能爬,但只爬取5页的表情包,程序就结束了。再次运行的时候,程序一直在运行,不停下来。这个代码如下,希望有大佬,好心人,帮我看看程序出错在哪?
from urllib import requestfrom queue import Queue
from lxml import etree
import threading
import requests
import time
import re
import os
# 生产者模型
class Producer(threading.Thread):
headers ={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
# 实例方法,接受参数值
def __init__(self,page_queue,img_queue,*args,**kwargs):
super(Producer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty(): # 退出循环调节为装url的队列全空
break
url = self.page_queue.get() # 拿到url,进行解析
self.parse_page(url)
def parse_page(self,url):
response = requests.get(url,headers=self.headers,timeout=30)
text = response.text
html = etree.HTML(text)
imgs = html.xpath('//div[@class="page-content text-center"]//img[@class!="gif"]')
for img in imgs:
img_url = img.get('data-original')
alt = img.get('alt')
alt = re.sub(r'[\??\.。!\*\!/:]','',alt)
suffix = os.path.splitext(img_url)[1]
filename = alt + suffix
# 将得到信息传递给中间这,然后在给消费者
self.img_queue.put((img_url,filename)) # 文件信息给队列
# 消费者模型
class Consumer(threading.Thread):
def __init__(self,page_queue,img_queue,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
with open('F:/imgs/{}'.format(filename),'wb') as f:
f.write(requests.get(img_url).content)
print("{}".format(filename))
def main():
page_queue = Queue(100) #存储文件信息,包括url和文件名
img_queue = Queue(500) # 存储图片的队列
# 打印前100页的url,存入队列中
for i in range(1,10):
url = 'http://www.doutula.com/photo/list/?page={}'.format(i)
page_queue.put(url) # 添加url到队列中
# 开启5个生产者
for x in range(5):
t = Producer(page_queue,img_queue)
t.start()
# 开启4个消费者
for x in range(4):
t = Consumer(page_queue,img_queue)
t.start()
if __name__ == '__main__':
main()
问题出现的环境背景及自己尝试过哪些方法
相关代码
// 请把代码文本粘贴到下方(请勿用图片代替代码)
你期待的结果是什么?实际看到的错误信息又是什么?
以上是 下面的多线程爬虫程序错在哪里? 的全部内容, 来源链接: utcz.com/p/937615.html