如果给一个数组集合,如何过滤出树里本id的所以父节点id?
let fileIds= ['0000','1111','2222','4444']let folderTrees = [
{
bookId: "123",
id: "m1", //目录id
level: "0", //级别
levelCode: "abc", //目录层级关系
name: "目录名称1", //目录名称
parentId: "0", //父级目录ID
priority: "1", //顺序
folderResTypes: [
{
//目录资源类型列表
id: "0000", //资源类型ID
name: "资源类型名称零", //资源类型名称
resInfos: [
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-1", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-2", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-3", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-4", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
],
},
],
childNodes: [
{
bookId: "1234",
id: "m2", //目录id
level: "0", //级别
levelCode: "abc", //目录层级关系
name: "目录名称1-1", //目录名称
parentId: "0", //父级目录ID
priority: "1", //顺序
folderResTypes: [
{
//目录资源类型列表
id: "2222", //资源类型ID
name: "资源类型名称一", //资源类型名称
resInfos: [
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称1-1", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称1-2", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称1-3", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
],
},
{
//目录资源类型列表
id: "1111", //资源类型ID
name: "资源类型名称二", //资源类型名称
resInfos: [
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称2-1", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称2-2", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称2-3", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
],
},
],
},
],
},
{
bookId: "12345",
id: "m3", //目录id
level: "0", //级别
levelCode: "abc", //目录层级关系
name: "目录名称2", //目录名称
parentId: "0", //父级目录ID
priority: "1", //顺序
folderResTypes: [
{
//目录资源类型列表
id: "4444", //资源类型ID
name: "资源类型名称二-1", //资源类型名称
resInfos: [
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称01-1", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称01-2", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称01-3", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
],
},
],
childNodes: [
{
bookId: "1234567",
id: "m4", //目录id
level: "0", //级别
levelCode: "abc", //目录层级关系
name: "目录名称00", //目录名称
parentId: "0", //父级目录ID
priority: "1", //顺序
folderResTypes: [
{
//目录资源类型列表
id: "3333", //资源类型ID
name: "资源类型名称零", //资源类型名称
resInfos: [
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-1", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-2", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-3", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
{
cover: "资源封面", //资源封面
fileTypeIcon: "文件类型图标", //文件类型图标
id: "id", //
lrcName: "音频字幕文件名", //音频字幕文件名
lrcPath: "音频字幕文件路径", //音频字幕文件路径
name: "资源名称0-4", //资源名称
path: "oss路径", //oss路径
playDuration: "播放时长 秒", //播放时长 秒
postfix: "后缀", //后缀
size: "文件大小 kb", //文件大小 kb
},
],
},
],
},
],
},
]
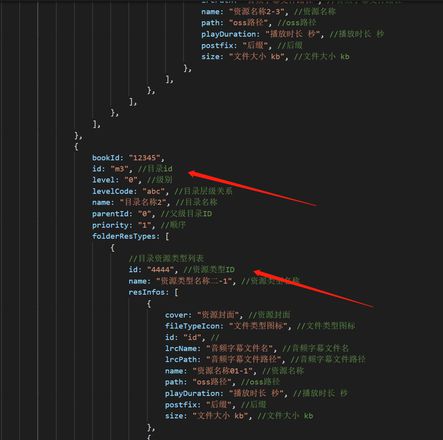
folderTrees 是树,每一层下里都用有folderResTypes字段,如何通过fileIds过滤出获取所以父节点的id。比如findarr(folderTrees ,[ids])函数,fileIds如果是['0000','3333'],那么就会返回出['m1','m3']
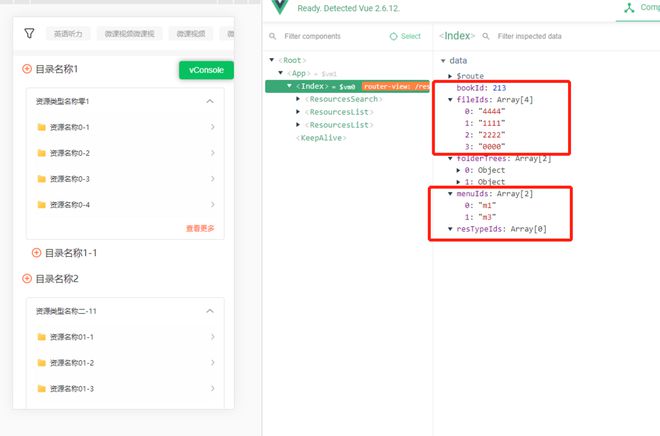
显示是我手动选出来的,现在需要做过进入页面字段打开目录和资源列表,所以需要做这个需求。我自己写递归,写过可能有问题,没实现。
回答:
当前元素的folderResTypes中含有目标id,则获取元素id,那么改元素的祖先元素的id要不要获取呢?下面是不获取版的
function getParentNodeId(list, ids){ let result = []
list.forEach(item => {
if((item.folderResTypes || []).find(type => ids.includes(type.id))){
result.push(item.id)
}
if(Array.isArray(item.childNodes)){
result = result.concat(getParentNodeId(item.childNodes, ids, result))
}
})
return result
}
getParentNodeId(folderTrees, ['0000','1111','2222','4444']) // ["m1", "m2", "m3"]
getParentNodeId(folderTrees, ['0000']) //["m1"]
getParentNodeId(folderTrees, ['1111']) //["m2"]
getParentNodeId(folderTrees, ['3333']) //["m4"]
回答:
这是同时在 childNodes 和 folderResTypes 中匹配 ID 的情况
function find(nodes, id, parents = []) { if (!Array.isArray(nodes)) { return; }
// 如果 nodes 列表中某项就是,就找到了
if (nodes.find(node => node.id === id)) { return parents; }
// 没找到的情况下,对 nodes 中的每个 node,
// 递归去 folderResTypes 和 childNoes 中去找
for (const node of nodes) {
const found = find(node.folderResTypes, id, [...parents, node.id])
?? find(node.childNodes, id, [...parents, node.id]);
if (found) { return found; }
}
}
let fileIds = ['0000', '1111', '2222', '4444', '9999', 'm4']
// ^^^^^^ 为了演示「找不到」加的
// ^^^^ 为了演示查找 childNodes 加的
const r = fileIds.map(id => find(folderTrees, id));
console.log(r);
// [
// [ 'm1' ],
// [ 'm1', 'm2' ],
// [ 'm1', 'm2' ],
// [ 'm3' ],
// undefined,
// [ 'm3' ]
// ]
不过,我觉得可能你想只在 folderResTypes 中查找,就改了一下
function find(nodes, id, parents = []) { if (!Array.isArray(nodes)) { return; }
// 先找 nodes 中每个 node 的 folderResTypes,
// 按理说,这下面不需要递归(猜 folderResTypes 是数据,下面不会有 childNodes)
for (const node of nodes) {
if (node.folderResTypes?.find(it => it.id === id)) {
return [...parents, node.id];
}
}
// 没找到,再遍历一次。这次用递归去找 childNodes
for (const node of nodes) {
const found = find(node.childNodes, id, [...parents, node.id]);
if (found) { return found; }
}
}
let fileIds = ['0000', '1111', '2222', '4444', '9999', 'm4']
const r = fileIds.map(id => find(folderTrees, id));
console.log(r);
// [
// [ 'm1' ],
// [ 'm1', 'm2' ],
// [ 'm1', 'm2' ],
// [ 'm3' ],
// undefined,
// undefined
// ]
以上是 如果给一个数组集合,如何过滤出树里本id的所以父节点id? 的全部内容, 来源链接: utcz.com/p/935587.html