Java SpringBoot在RequestBody中高效的使用枚举参数原理案例详解
在优雅的使用枚举参数(原理篇)中我们聊过,Spring对于不同的参数形式,会采用不同的处理类处理参数,这种形式,有些类似于策略模式。将针对不同参数形式的处理逻辑,拆分到不同处理类中,减少耦合和各种if-else逻辑。本文就来扒一扒,RequestBody参数中使用枚举参数的原理。
找入口
对 Spring 有一定基础的同学一定知道,请求入口是DispatcherServlet,所有的请求最终都会落到doDispatch方法中的ha.handle(processedRequest, response, mappedHandler.getHandler())逻辑。我们从这里出发,一层一层向里扒。
跟着代码深入,我们会找到org.springframework.web.method.support.InvocableHandlerMethod#invokeForRequest的逻辑:
public Object invokeForRequest(NativeWebRequest request, @Nullable ModelAndViewContainer mavContainer,
Object... providedArgs) throws Exception {
Object[] args = getMethodArgumentValues(request, mavContainer, providedArgs);
if (logger.isTraceEnabled()) {
logger.trace("Arguments: " + Arrays.toString(args));
}
return doInvoke(args);
}
可以看出,这里面通过getMethodArgumentValues方法处理参数,然后调用doInvoke方法获取返回值。getMethodArgumentValues方法内部又是通过HandlerMethodArgumentResolverComposite实例处理参数。这个类内部是一个HandlerMethodArgumentResolver实例列表,列表中是Spring处理参数逻辑的集合,跟随代码Debug,可以看到有27个元素。这些类也是可以定制扩展,实现自己的参数解析逻辑,这部分内容后续再做介绍。
选择Resolver
这个Resolver列表中,包含我们常用的几个处理类。Get请求的普通参数是通过RequestParamMethodArgumentResolver处理参数,包装类通过ModelAttributeMethodProcessor处理参数,RequestBody形式的参数,则是通过RequestResponseBodyMethodProcessor处理参数。这段就是Spring中策略模式的使用,通过实现org.springframework.web.method.support.HandlerMethodArgumentResolver#supportsParameter方法,判断输入参数是否可以解析。下面贴上RequestResponseBodyMethodProcessor的实现:
public boolean supportsParameter(MethodParameter parameter) {
return parameter.hasParameterAnnotation(RequestBody.class);
}
可以看到,RequestResponseBodyMethodProcessor是通过判断参数是否带有RequestBody注解来判断,当前参数是否可以解析。
解析参数
RequestResponseBodyMethodProcessor继承自AbstractMessageConverterMethodArgumentResolver,真正解析RequestBody参数的逻辑在org.springframework.web.servlet.mvc.method.annotation.AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters方法中。我们看下源码(因为源码比较长,文中仅留下核心逻辑。):
protected <T> Object readWithMessageConverters(HttpInputMessage inputMessage, MethodParameter parameter,
Type targetType) throws IOException, HttpMediaTypeNotSupportedException, HttpMessageNotReadableException {
MediaType contentType = inputMessage.getHeaders().getContentType();// 1
Class<?> contextClass = parameter.getContainingClass();// 2
Class<T> targetClass = (targetType instanceof Class ? (Class<T>) targetType : null);// 3
Object body = NO_VALUE;
EmptyBodyCheckingHttpInputMessage message = new EmptyBodyCheckingHttpInputMessage(inputMessage);// 4
for (HttpMessageConverter<?> converter : this.messageConverters) {// 5
Class<HttpMessageConverter<?>> converterType = (Class<HttpMessageConverter<?>>) converter.getClass();
GenericHttpMessageConverter<?> genericConverter =
(converter instanceof GenericHttpMessageConverter ? (GenericHttpMessageConverter<?>) converter : null);
if (genericConverter != null ? genericConverter.canRead(targetType, contextClass, contentType) :
(targetClass != null && converter.canRead(targetClass, contentType))) {
if (message.hasBody()) {
HttpInputMessage msgToUse =
getAdvice().beforeBodyRead(message, parameter, targetType, converterType);
body = (genericConverter != null ? genericConverter.read(targetType, contextClass, msgToUse) :
((HttpMessageConverter<T>) converter).read(targetClass, msgToUse));// 6
body = getAdvice().afterBodyRead(body, msgToUse, parameter, targetType, converterType);
}
else {
body = getAdvice().handleEmptyBody(null, message, parameter, targetType, converterType);
}
break;
}
}
return body;
}
跟着代码说明一下各部分用途:
- 获取请求content-type
- 获取参数容器类
- 获取目标参数类型
- 将请求参数转换为EmptyBodyCheckingHttpInputMessage类型
- 循环各种RequestBody参数解析器,这些解析器都是HttpMessageConverter接口的实现类。Spring对各种情况做了全量覆盖,总有一款适合的。文末给出HttpMessageConverter各个扩展类的类图。
- for循环体中就是选择一款适合的,进行解析
- 首先调用canRead方法判断是否可用
- 判断请求请求参数是否为空,为空则通过AOP的advice处理一下空请求体,然后返回
- 不为空,先通过AOP的advice做前置处理,然后调用read方法转换对象,在通过advice做后置处理
Spring的AOP不在本文范围内,所以一笔带过。后续有专题说明。
本例中,HttpMessageConverter使用的是MappingJackson2HttpMessageConverter,该类继承自AbstractJackson2HttpMessageConverter。看名称就知道,这个类是使用Jackson处理请求参数。其中read方法之后,会调用内部私有方法readJavaType,下面给出该方法的核心逻辑:
private Object readJavaType(JavaType javaType, HttpInputMessage inputMessage) throws IOException {
MediaType contentType = inputMessage.getHeaders().getContentType();// 1
Charset charset = getCharset(contentType);
ObjectMapper objectMapper = selectObjectMapper(javaType.getRawClass(), contentType);// 2
Assert.state(objectMapper != null, "No ObjectMapper for " + javaType);
boolean isUnicode = ENCODINGS.containsKey(charset.name()) ||
"UTF-16".equals(charset.name()) ||
"UTF-32".equals(charset.name());// 3
try {
if (isUnicode) {
return objectMapper.readValue(inputMessage.getBody(), javaType);// 4
} else {
Reader reader = new InputStreamReader(inputMessage.getBody(), charset);
return objectMapper.readValue(reader, javaType);
}
}
catch (InvalidDefinitionException ex) {
throw new HttpMessageConversionException("Type definition error: " + ex.getType(), ex);
}
catch (JsonProcessingException ex) {
throw new HttpMessageNotReadableException("JSON parse error: " + ex.getOriginalMessage(), ex, inputMessage);
}
}
跟着代码说明一下各部分用途:
- 获取请求的content-type,这个是Spring实现的扩展逻辑,根据不同的content-type可以选择不同的ObjectMapper实例。也就是第2步的逻辑
- 根据content-type和目标类型,选择ObjectMapper实例。本例中直接返回的是默认的,也就是通过Jackson2ObjectMapperBuilder.cbor().build()方法创建的。
- 检查请求是否是unicode字符,目前来说,大家用的都是UTF-8的
- 通过ObjectMapper将请求json转换为对象。其实这部分还有一段判断inputMessage是否是MappingJacksonInputMessage实例的,考虑到大家使用的版本,这部分就不说了。
至此,Spring的逻辑全部结束,似乎还是没有找到我们使用的JsonCreator注解或者JsonDeserialize的逻辑。不过也能想到,这两个都是Jackson的类,那必然应该是Jackson的逻辑。接下来,就扒一扒Jackson的转换逻辑了。
深入Jackson的ObjectMapper逻辑
牵扯Jackson的逻辑主要分布在AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters和ObjectMapper#readValue这两个方法中。先说一下ObjectMapper#readValue方法的逻辑,这里面会调用GenderIdCodeEnum#create方法,完成类型转换。
ObjectMapper#readValue方法直接调用了当前类中的_readMapAndClose方法,这个方法里面比较关键的是ctxt.readRootValue(p, valueType, _findRootDeserializer(ctxt, valueType), null),这个方法就是将输入json转换为对象。咱们再继续深入,可以找到Jackson内部是通过BeanDeserializer这个类转换对象的,比较重要的是deserializeFromObject方法,源码如下(删除一下不太重要的代码):
public Object deserializeFromObject(JsonParser p, DeserializationContext ctxt) throws IOException
{
// 这里根据上下文中目标类型,创建实例对象,其中 _valueInstantiator 是 StdValueInstantiator 实例。
final Object bean = _valueInstantiator.createUsingDefault(ctxt);
// [databind#631]: Assign current value, to be accessible by custom deserializers
p.setCurrentValue(bean);
if (p.hasTokenId(JsonTokenId.ID_FIELD_NAME)) {
String propName = p.currentName();
do {
p.nextToken();
// 根据字段名找到 属性对象,对于gender字段,类型是 MethodProperty。
SettableBeanProperty prop = _beanProperties.find(propName);
if (prop != null) { // normal case
try {
// 开始进行解码操作,并将解码结果写入到对象中
prop.deserializeAndSet(p, ctxt, bean);
} catch (Exception e) {
wrapAndThrow(e, bean, propName, ctxt);
}
continue;
}
handleUnknownVanilla(p, ctxt, bean, propName);
} while ((propName = p.nextFieldName()) != null);
}
return bean;
}
咱们看一下MethodProperty#deserializeAndSet的逻辑(只保留关键代码):
public void deserializeAndSet(JsonParser p, DeserializationContext ctxt,
Object instance) throws IOException
{
Object value;
// 调用 FactoryBasedEnumDeserializer 实例的解码方法
value = _valueDeserializer.deserialize(p, ctxt);
// 通过反射将值写入对象中
_setter.invoke(instance, value);
}
其中_valueDeserializer是FactoryBasedEnumDeserializer实例,快要接近目标了,看下这段逻辑:
public Object deserialize(JsonParser p, DeserializationContext ctxt) throws IOException
{
// 获取json中的值
Object value = _deser.deserialize(p, ctxt);
// 调用 GenderIdCodeEnum#create 方法
return _factory.callOnWith(_valueClass, value);
}
_factory是AnnotatedMethod实例,主要是对JsonCreator注解定义的方法的包装,然后callOnWith中调用java.lang.reflect.Method#invoke反射方法,执行GenderIdCodeEnum#create。
至此,我们终于串起来所有逻辑。
文末总结
本文通过一个示例串起来@JsonCreator注解起作用的逻辑,JsonDeserializer接口的逻辑与之类型,可以耐心debug一番。下面给出主要类的类图:
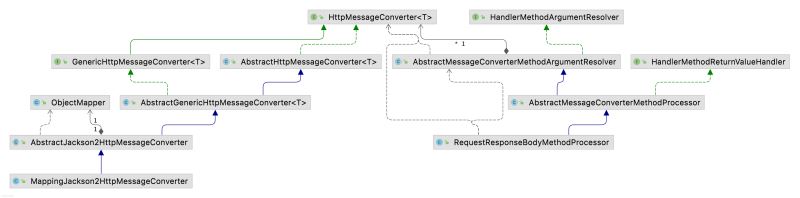

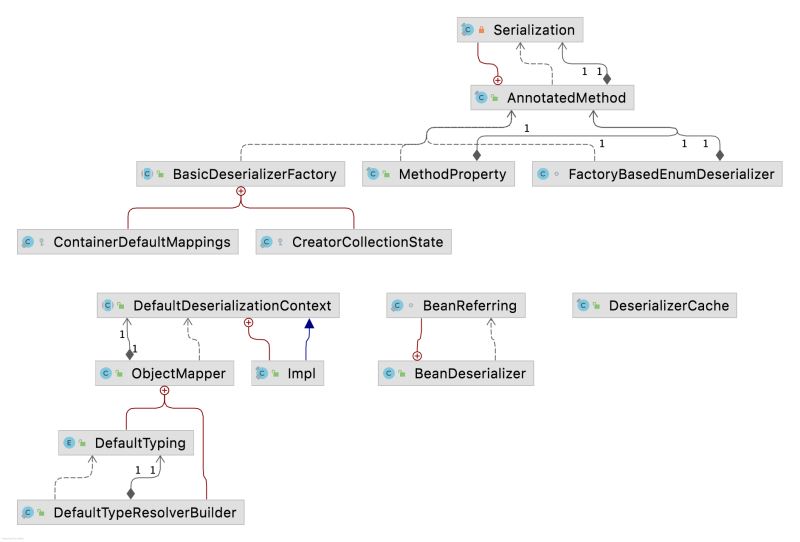
推荐阅读
- SpringBoot 实战:一招实现结果的优雅响应
- SpringBoot 实战:如何优雅的处理异常
- SpringBoot 实战:通过 BeanPostProcessor 动态注入 ID 生成器
- SpringBoot 实战:自定义 Filter 优雅获取请求参数和响应结果
- SpringBoot 实战:优雅的使用枚举参数
- SpringBoot 实战:优雅的使用枚举参数(原理篇)
- SpringBoot 实战:在 RequestBody 中优雅的使用枚举参数
- SpringBoot 实战:在 RequestBody 中优雅的使用枚举参数(原理篇)
到此这篇关于Java SpringBoot在RequestBody中高效的使用枚举参数原理案例详解的文章就介绍到这了,更多相关Java SpringBoot在RequestBody中高效的使用枚举参数内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Java SpringBoot在RequestBody中高效的使用枚举参数原理案例详解 的全部内容, 来源链接: utcz.com/p/248535.html