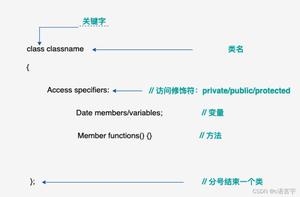
C++ 再识类和对象
类的6个默认成员函数
一个类中如果什么成员都没有,那么这个类称为空类。空类中是什么都没有吗?其实不然,任何一个类,再我们不写的情况下,都会自动生成下面6个默认成员函数:
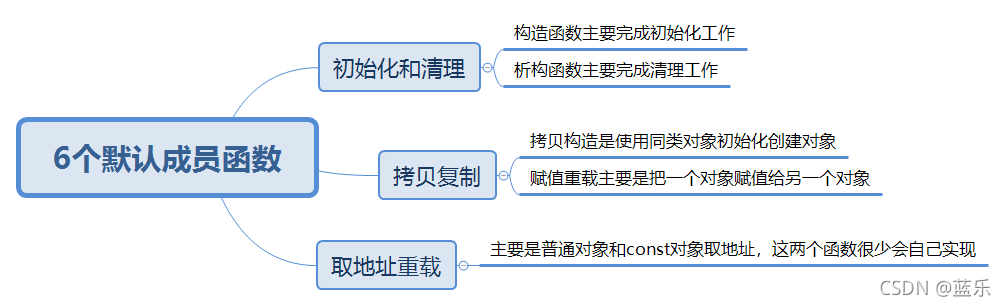
本篇文章将对这几个默认成员函数进行简单介绍。
构造函数
1.概念
我们先来看一下下面这个日期类:
class Date
{
public:
void SetDate(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
d1.SetDate();
d1.Print();
return 0;
}
对于Date类,每次创建对象时可以调用SetData函数来设置对象的日期,但是如果每次创建对象时都需要调用该函数来设置日期信息,未免有些麻烦,那么能否再对象创建的同时就进行初始化呢?
这里就需要用到类的默认成员函数–构造函数了。
构造函数是一个特殊的成员函数,名字与类名相同,创建类类型对象时由编译器自动调用,保证每个数据成员都有 一个合适的初始值,并且在对象的生命周期内只调用一次。
2.特性
需要注意,构造函数虽然名为构造函数,但是其作用并非为成员变量开辟空间,而是初始化对象。其特征如下:
函数名与类名相同。
没有返回值。
编译器会再对象实例化时自动调用构造函数。
构造函数可以重载。
需要注意的是在类实例化对象的时候,如果变量后面带上了(),而括号内没有参数,那么这就成了函数声明,该函数无参,且返回值为类名。
class Date
{
public:
Date()//无参的构造函数
{
_year = 0;
_month = 1;
_day = 1;
}
//带参的构造函数
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;//调用无参的构造函数
Date d2(0, 1, 1);//调用带参的构造函数
Date d3();//无参,返回值为Date的函数声明
return 0;
}
隐式构造函数
如果类中没有显式定义构造函数,那么c++编译器将会自动生成一个无参的默认构造函数,而如果用户显式定义了构造函数,那么编译器将不再生成构造函数。
需要注意的是编译器自己生成的构造函数在初始化对象时做了一个偏心的处理:即对于内置类型,编译器不会处理;而对于自定义类型,编译器会自定义类型调用它自己的默认构造函数。内置类型指的是语法已经定义好的类型,如:int,double,long等等;自定义类型是使用struct/class/union定义的类型。
这是什么意思呢?我们通过下面这个代码来理解:
class C
{
public:
C()
{
cout << "C()" << endl;
}
private:
int _c;
};
class Date
{
public:
//若用户显式定义了构造函数,那么编译器将不再生成
/*Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}*/
private:
//内置类型
int _year;
int _month;
int _day;
//自定义类型
C c1;
};
int main()
{
Date d1;//调用无参的构造函数
return 0;
}

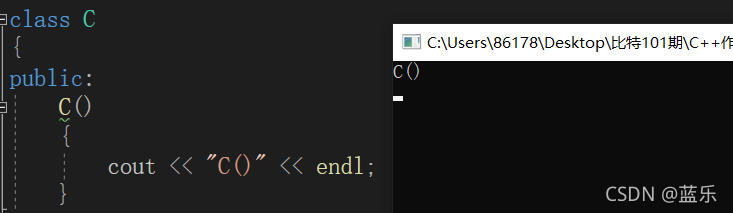
通过调试可以发现,d1自身的内置类型变量仍为随机值,编译器调用的构造函数并没有处理,而对于自定义类型,可以看到编译器调用了自定义类型中的默认函数,但是实际上如果调用编译器自己生成的默认构造函数,最终的结果就是所有的内置类型变量仍然为随机值,这么看下来好像编译器自己生成的构造函数好像没什么用?
实则不然,比如我们曾做过用栈实现队列的题,这道题的思路是用两个栈来回倒保证队列的先进先出,而这里面的两个结构栈和用栈实现的队列的代码为:
class Stack//栈
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
private:
int* _a;
int _top;
int _capacity;
};
struct MyQueue//用两个栈实现队列
{
Stack s1;
Stack s2;
};
可以看到在用MyQueue这个类实例化对象时,编译器调用Stack中的构造函数分别对成员变量s1和s2初始化,因此,我们无需再对其进行初始化了,这相对来说方便了许多。
无参和全缺省的函数均为默认构造函数
无参的构造函数和全缺省的构造函数都被称为默认构造函数,但是需要注意的是:无参的构造函数和全缺省的构造函数二者只能存在一个,这是因为,如果二者都存在的话,那么在实例化对象不带参数时,编译器无法区分是调用哪一个函数。
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;//错误,编译器无法识别要调用哪一个构造函数
return 0;
}
在实际过程中,我们更倾向于使用全缺省的构造函数,因为它包含了无参的构造函数的情况。
成员变量的命名风格
可以注意到的是在定义类的时候成员变量前都加了一个_,这是为了防止下面这种情况:
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
year = year;
month = month;
day = day;
}
void Print()
{
cout << year << "/" << month << "/" << day << endl;
}
private:
int year;
int month;
int day;
};
int main()
{
Date d1;
d1.Print();
return 0;
}
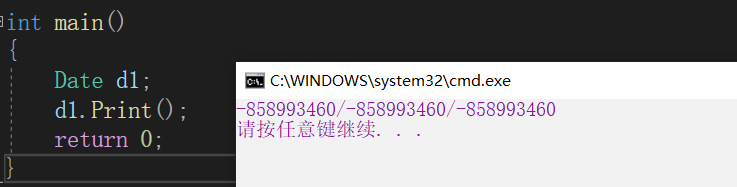
可以看到,d1调用了构造函数后,其成员变量认为随机值。这是因为在year = year这句代码中,两个year变量均为函数形参,实际上编译器在处理这种变量时,会遵循局部优先原则,即编译器在函数形参中找到了year变量,就不会继续扩大搜索范围去寻找成员变量中的year变量,而在Print函数中,编译器由于在形参中未找到year变量,因此继续扩大搜索范围,在成员变量中找到了year并使用之。
因此,在声明成员变量的命名时需要遵循一定的规范,常见的有:(1)在变量名前加_,如_year (2)在变量名后加_,如year_ (3)驼峰法,如mYear,m表示member。
另外,上述情况可以通过使用this指针进行解决,即将代码改为this->year = year;但在实际使用过程中,最好还是注重成员变量的命名
补充
由于早期c++语法设计的缺陷,编译器默认生成的构造函数并不会对内置类型变量初始化,因此在c++11后,语法委员会在成员变量声明处打了一个补丁,运行,变量声明的同时加上缺省值,比如:
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
private:
//注意,此处仅为缺省值,仍为变量声明,而非初始化(定义)
int _year = 0;
int _month = 1;
int _day = 1;
};
析构函数
1.概念
与构造函数相比,析构函数相对简单一些。析构函数的作用与构造函数的相反,析构函数并不是完成对象的销毁,因为局部对象的销毁工作是由编译器来完成的。一个词来概括析构函数的作用就是清理,即对象在销毁的时候会自动调用析构函数,完成类当中的一些资源清理工作。
2.特性
析构函数是一种特殊的成员函数,其特征如下:
析构函数名是类名前加上~号
析构函数无参数无返回值
一个类有且只有一个析构函数
若析构函数为显式定义,那么系统会自动生成默认的析构函数。
与构造函数一样,系统的默认析构函数对于内置类型变量不会处理,对于自定义变量会调用其自身的析构函数。
其次,对于Date类这样的类,由于其内部没有什么资源需要处理,因此不需要析构函数;对于Stack这样的类,其内部由资源需要处理,比如对malloc出来的空间进行释放,因此需要实现析构函数。
还是之前的代码,在用两个栈实现队列中,在Stack类中实现了构造函数和析构函数,那么用MyQueue实例化my变量后无法自己实现初始化和空间的释放:
class Stack
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
~Stack()
{
free(_a);
_a = NULL;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
struct MyQueue
{
Stack s1;
Stack s2;
};
int main()
{
//我们无需自己对mq进行初始化和清理空间
//编译会自动调用构造函数和析构函数
MyQueue mq;
return 0;
}
c++编译器在对象生命周期结束时自动调用析构函数
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
~Date()
{
cout << "~Date()" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
return 0;//编译器在执行这句代码的同时会调用类中的析构函数
}
拷贝构造函数
1.概念
拷贝构造函数,顾名思义,其作用就是创建一个和被拷贝对象一模一样的对象。
拷贝构造函数只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),在用已存在的类类型对象创建新对象时由编译器自动调用。
2.特性
拷贝构造函数也是特殊的成员函数,其特征是:
拷贝构造函数是构造函数的一个重载形式
参数只有一个且为引用传参
拷贝构造函数的参数只有一个且必须为引用传参,使用传值方式会引发无穷递归调用。
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
Date(Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
Date d2(d1);
return 0;
}
那么为什么说传值会导致无穷递归调用呢?首先我们需要理解到调用函数传值给形参也是一种拷贝,比如说:

同样的,对于拷贝构造函数,若形参为传值调用,那么在上述代码中将d2赋值给形参d时也会调用拷贝构造函数,而每一次调用拷贝构造函数都会经过依次赋值操作,从而导致无穷递归调用:
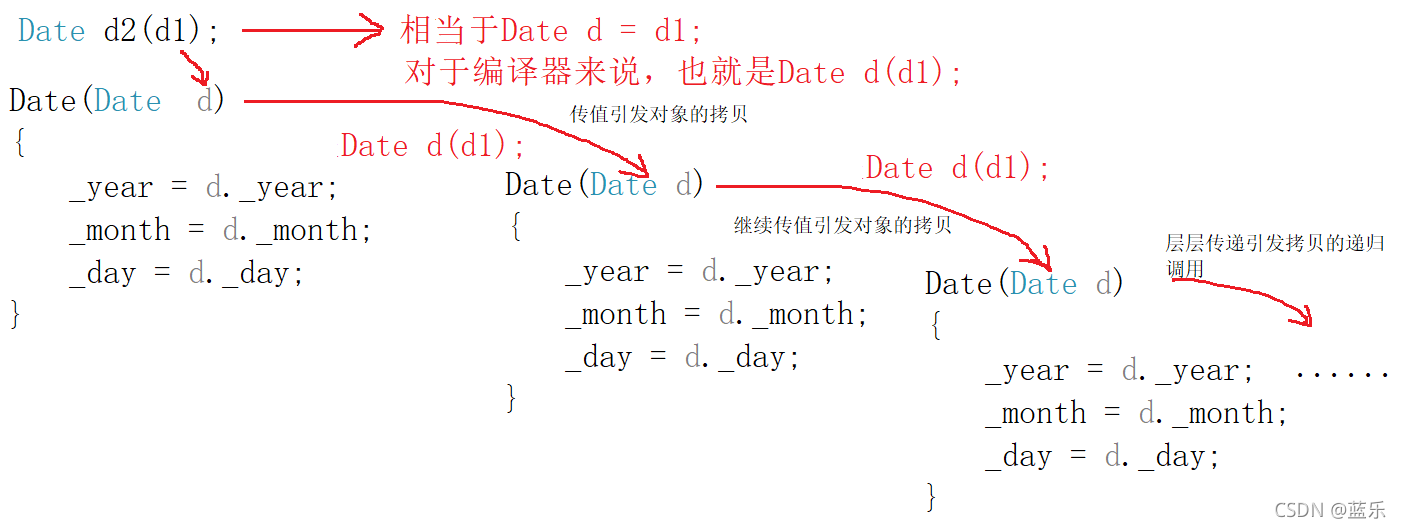
而传引用就能够很好的解决这个问题,其次,传指针也可以达到目的,不过一般传引用的话可以增强代码可读性。
若未显式定义,系统会生成默认的拷贝构造函数
与构造函数一样,如果我们自己没有实现拷贝构造函数,那么编译器会生成默认的拷贝构造函数;但是与构造函数不同的是,默认的拷贝构造函数对于内置类型和自定义类型变量都会处理:
(1)对于内置类型,默认的拷贝构造函数会对对象进行浅拷贝,即按照内存存储中的字节序对对象进行拷贝,也叫值拷贝。
(2)对于自定义类型,默认的拷贝构造函数会调用自定义类型中自己的拷贝构造函数。
class A
{
public:
A()
{
_a = 0;
}
A(const A& a)
{
cout << "A(const A& a)" << endl;
}
private:
int _a;
};
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
//调用默认的拷贝构造函数
/*Date(Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}*/
private:
int _year;
int _month;
int _day;
A aa;
};
int main()
{
Date d1;
Date d2(d1);
return 0;
}
浅拷贝的注意事项
通过上面我们知道了默认的拷贝构造函数能够实现浅拷贝,也就是说,对于Date这样的类,我们无需自己实现拷贝构造函数只用默认的拷贝构造函数就能够实现拷贝目的,那么是否用编译器自己的函数就够了呢?
其实不然,比如我们熟知的Stack类,如果直接调用系统默认的拷贝构造函数:
class Stack
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
~Stack()
{
free(_a);
_a = NULL;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
Stack s1(8);
Stack s2(s1);
return 0;
}
上述代码,我们运行后发现,程序崩溃了,这是为什么呢?这是因为系统默认的拷贝构造函数拷贝出了一份与s1一模一样的s2:

而我们知道当对象的生命周期结束时,系统会自动调用析构函数对类空间进行清理,由于s2是后压栈的,因此会先清理,这时s2._a所指的空间已经free还给操作系统了,但是s1还会再次调用析构函数,将已经释放的s1._a所指向的空间再一次释放(注意,s2._a释放完后s1._a仍指向原空间,此时s1._a为野指针),这个操作最终会导致程序崩溃。
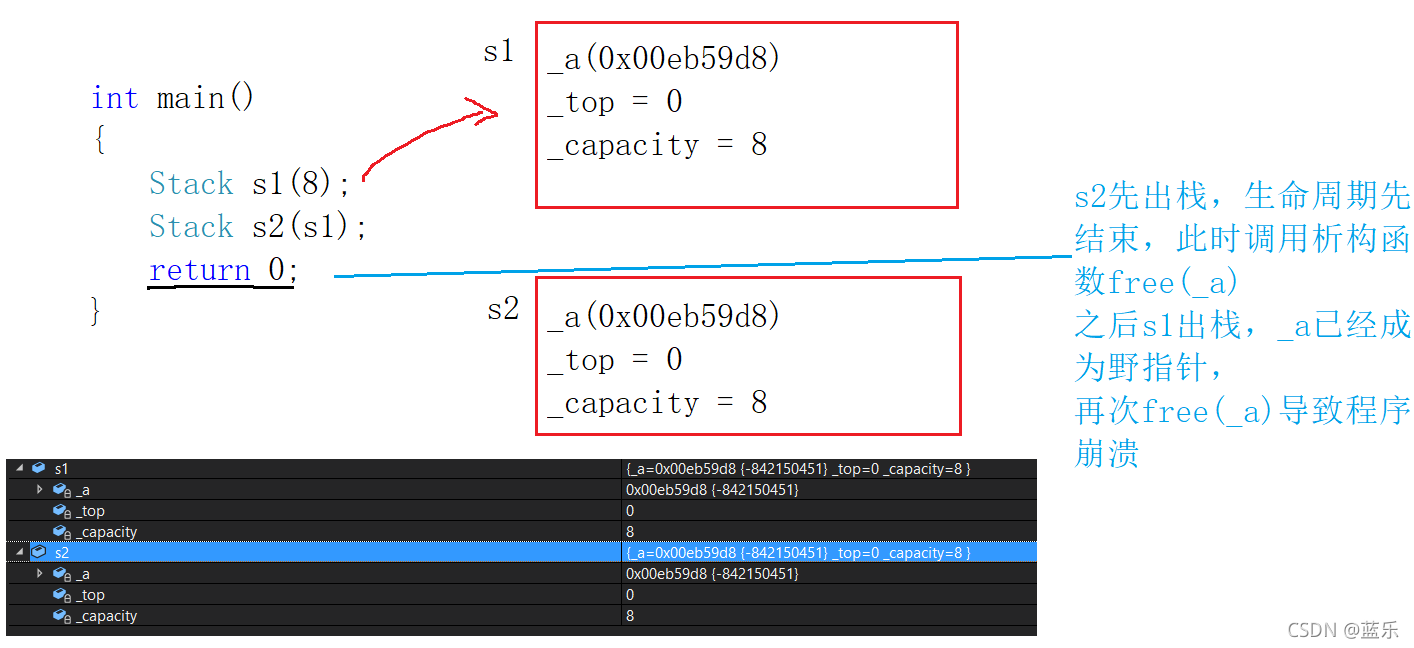
可见编译器默认的拷贝构造函数并不能解决所有的问题,浅拷贝会导致一些错误,那么要如何解决浅拷贝的带来的问题呢?这就要我们之后介绍的深拷贝来解决了。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!
以上是 C++ 再识类和对象 的全部内容, 来源链接: utcz.com/p/247432.html