Elasticsearch 文档、类型和索引介绍
一、概述
我们从数据的组织开始。为了理解 Elasticsearch 中的数据是如何组织的,从一下两个角度来观察。
- 逻辑设计–搜索应用所要注意的。用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里的一行。文档以类型来分组,类型包含若干文档,类似表格包含若干行。最终,一个或多个类型存在于同一索引中,索引是更大的容器,类似SQL世界中的数据库。
- 物理设计–在后台Elasticsearch是如何处理数据的。Elasticsearch将每个索引划分为分片,每份分片可以在集群中的不同服务器间迁移。通常应用程序无需关心这些,因为无论Elasticsearch是单台还是多台服务器,应用和Elasticsearch的交互基本保持不变。但是,开始管理集群的时候,就要留心了。原因是,物理设计的配置方式决定了集群的性能、可扩展性和可用性。
二、理解逻辑设计:文档、类型和索引
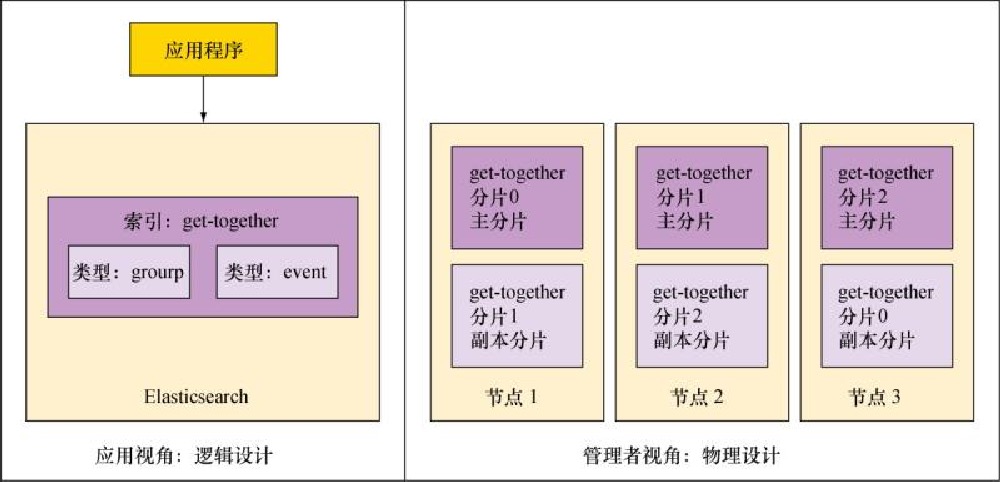
当索引Elasticsearch里的一篇文档时,你将其放入一个索引中的一个类型。可以通过下图理解这个想法,其中聚会索引get-together包含两种类型:活动(event)和分组(group)。这些类型包含若干文档,如标记为1的文档,标签1是该文档的ID。
提示:这个ID不必非要是一个整数。实际上它是个字符串,并没有限制。可以放置任何对应用有意义的字符。
这个索引-类型-ID的组合唯一确定了Elasticsearch中的某篇文档。当进行搜索的时候,可以查找特定的索引、特定的索引中的文档,也可以跨多个类型甚至是多个索引进行搜索。
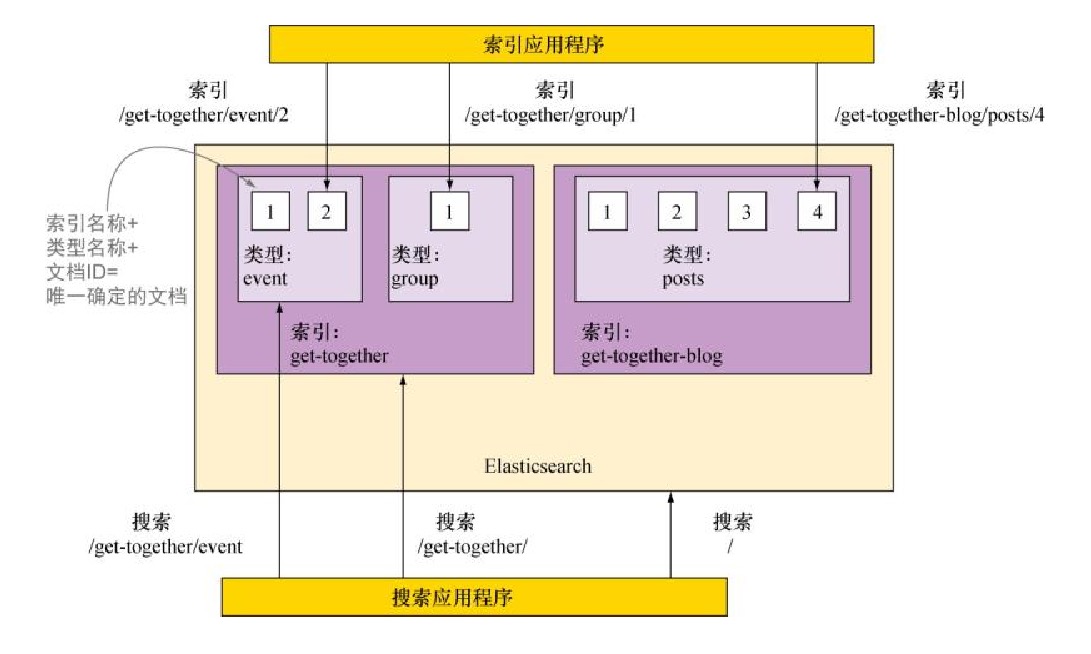
2.1文档
一篇文档通常是数据的 JSON 表示。在 Elasticsearch 中文档有几个重要的属性:
1、它是自我包含的。一篇文档同时包含字段(如name)和它们的取值(如Elasticsearch Denver)2、它可以是层次型的。想象一下,文档中还包含新的文档。一个字段的取值可以使简单的,例如,location字段的取值可以是字符串。
字段还可以包含其他字段和取值,例如,“位置”字段可以同时包含城市和街道地址。
3、它拥有灵活的结构。文档不依赖于预先定义的模式。例如,并非所有的活动需要“描述”这个字段,所以可以彻底忽略该字段。
但是,活动可能需要新的字段,如“位置”的维度和经度。
你可以假想有一张表格,拥有3列,即姓名(name)、组织者(organizer)和位置(location)。文档可以是包含若干取值的一行。但是这样的比较不够精准,它们还是有所差别。一个区别是,和行有所不同,文档可以是层次型的。例如,位置可以包含姓名和地理位置:
{ "name":"Elasticsearch Denver",
"organizer":"Lee",
"location":{
"name":"Denver,Colorado,USA",
"geolocation":"39.7392,-104.9847"
}
}
篇单独的文档也可以包含一组数值,例如:
{ "name":"Elasticsearch Denver",
"organizer":"Lee",
"members":["Lee","Mike"]
}
Elasticsearch中的文档是无模式的,也就是说并非所有的文档都需要拥有相同的字段,它们不是受限于同一个模式。例如,在所有信息完备之前就要使用组织者数据时,你可以彻底忽略位置数据。
尽管可以随意添加和忽略字段,但是每个字段的类型确实很重要:某些是字符串,某些是整数,等等。因为这一点,Elasticsearch保存字段和类型之间的映射以及其他设置。这种映射具体到每个索引的每种类型。这也是为什么在Elasticsearch的术语中,类型有时也称为映射类型。
2.2 类型
类型是文档的逻辑容器,类似于表格是行的容器。在不同的类型中,最好放入不同结构(模式)的文档。 每个类型中字段的定义称为映射。例如,name字段可以映射为string。 每种字段都是通过不同的方式进行处理。
NOTICE:如果一个字段不是JSON文档的根节点,在其中搜索时必须指定路径。举个例子,location中的geolocation字段被称为location.geolocation。
你可能会问到:如果 Elasticsearch 是无模式的,那么为什么每个文档属于一种类型,而且每个类型包含一个看上去很像模式的映射呢?
我们说“无模式”是因为文档并不受模式的限制。它们并不需要拥有映射中所定义的所有字段,也可能提出新的字段。这是如何运作的?首先,映射包含某个类型中当前索引的所有文档的所有字段。但是,不是所有的文档必须要有所有的字段。
同样,如果一篇新近索引的文档拥有一个映射中尚不存在的字段,Elasticsearch会自动地将新字段加入映射。
为了添加这个字段,Elasticsearch不得不确定它是什么类型,于是Elasticsearch会进行猜测。
例如,如果值是7,Elasticsearch会假设字段是长整型。
这种新字段的自动检测也有缺点,因为Elasticsearch可能猜得不对。例如,在索引了值7之后,你可能想再索引hello world,这时由于它是string而不是long,索引就会失败。对于线上环境,最安全的方式是在索引数据之前,就定义好所需的映射。
映射类型只是将文档进行逻辑划分。从物理角度来看,同一索引中的文档都是写入磁盘,而不考虑它们所属的映射类型。
2.3 索引
索引是映射类型的容器。一个Elasticsearch索引非常像关系型世界的数据库,是独立的大量文档集合。每个索引存储在磁盘上的同组文件中;索引存储了所有映射类型的字段,还有一些设置。
例如,每个索引有一个称为refresh_interval的设置,定义了新近索引的文档对于搜索可见的时间间隔。从性能的角度来看,刷新操作的代价是非常昂贵的,这也是为什么更新只是偶尔进行。默认是每秒更新一次,而不是每来一篇新的文档就更新一次。如果看到Elasticsearch被称为准实时的,就是指的这种刷新过程。
NOTICE:就像可以跨多个类型进行搜索一样,你可以跨多个索引进行搜索。这使得组织文档的方式更为灵活。
三、理解物理设计:节点和分片
为了有个全局的理解,我们先看一下在Elasticsearch索引创建的时候,究竟发生了什么?默认情况下,每个索引由5个主要分片组成,而每份主要分片又有一个副本,一共10份分片,如图下图所示。
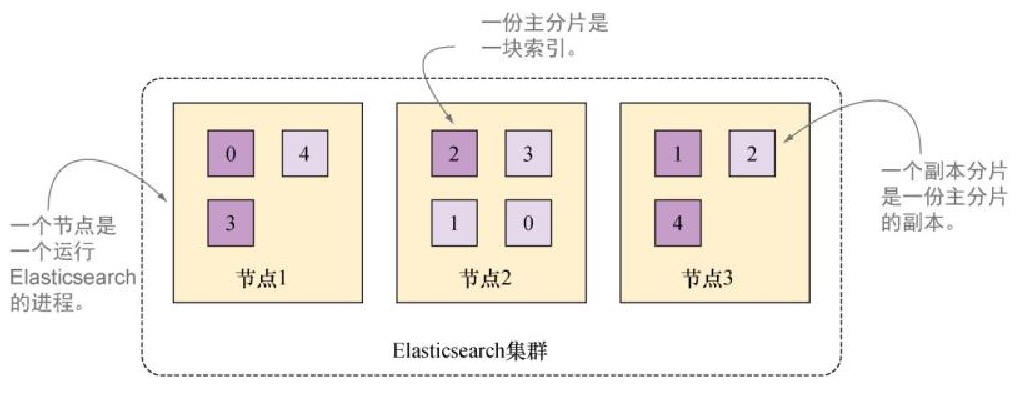
副本分片对于可靠性和搜索性能很有益处。技术上而言,一份分片是一个目录中的文件,Lucene用这些文件存储索引数据。分片也是Elasticsearch将数据从一个节点迁移到另一个节点的最小单位。
3.1 创建拥有一个或多个节点的集群
一个节点是一个Elasticsearch的实例。在服务器上启动Elasticsearch之后,你就拥有了一个节点。如果在另一台服务器上启动Elasticsearch,这就是另一个节点。甚至可以通过启动多个Elasticsearch进程,在同一台服务器上拥有多个节点。
多个节点可以加入同一个集群。本章稍后将讨论使用同样的集群名称启动节点,另外默认的设置也足以组建一个集群。
在多节点的集群上,同样的数据可以在多台服务器上传播。这有助于性能,因为Elasticsearch有了更多的资源。这同样有助于稳定性:如果每份分片至少有1个副本分片,那么任何一个节点都可以宕机,而Elasticsearch依然可以进行服务,返回所有数据。
对于使用Elasticsearch的应用程序,集群中有1个还是多个节点都是透明的。默认情况下,可以连接集群中的任一节点并访问完整的数据集,就好像集群只有单独的一个节点。
NOTICE:尽管集群对于性能和稳定性都有好处,但它也有缺点:必须确定节点之间能够足够快速地通信,并且不会产生大脑分裂(集群的2个部分不能彼此交流,都认为对方宕机了)。
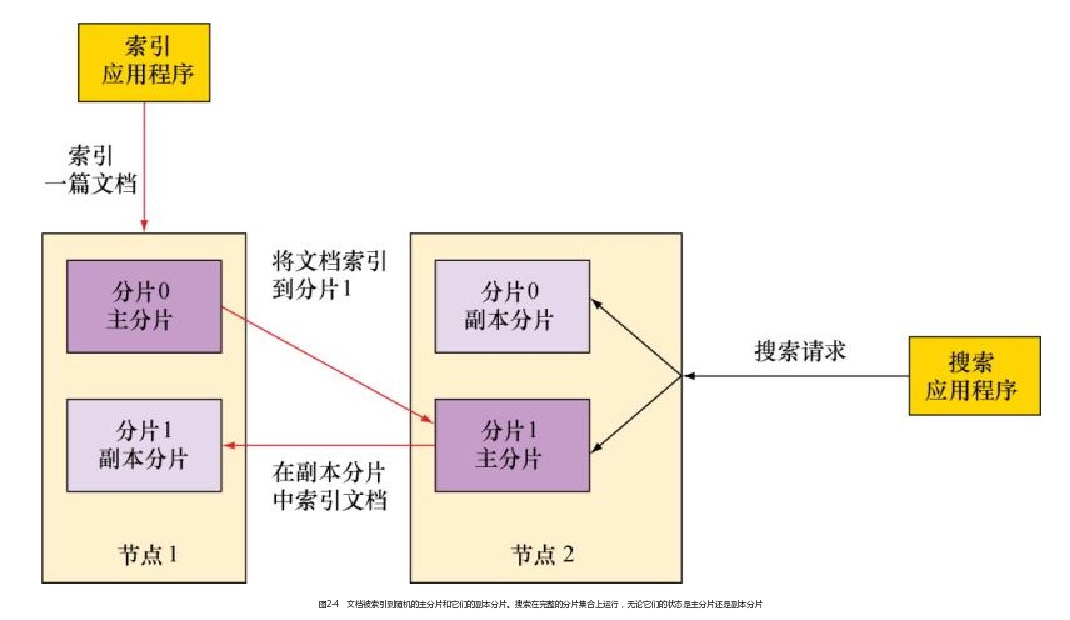
3.2 当索引一篇文档时发生了什么
默认情况下,当索引一篇文档的时候,系统首先根据文档ID的散列值选择一个主分片,并将文档发送到该主分片。这份主分片可能位于另一个节点,就像下图中节点2上的主分片,不过对于应用程序这一点是透明的。
然后文档被发送到该主分片的所有副本分片进行索引。这使得副本分片和主分片之间保持数据的同步。数据同步使得副本分片可以服务于搜索请求,并在原有主分片无法访问时自动升级为主分片。
3.3 搜索索引时发生了什么
当搜索一个索引时,Elasticsearch需要在该索引的完整分片集合中进行查找。这些分片可以是主分片,也可以是副本分片,原因是对应的主分片和副本分片通常包含一样的文档。Elasticsearch在索引的主分片和副本分片中进行搜索请求的负载均衡,使得副本分片对于搜索性能和容错都有所帮助。
3.4 理解主分片和副本分片
让我们从Elasticsearch所处理的最小单元:分片开始。一份分片是Lucene的索引:一个包含倒排索引的文件目录。倒排索引的结构使得Elasticsearch在不扫描所有文档的情况下,就能告诉你哪些文档包含特定的词条(单词)。
Elasticsearch索引和Lucene索引的对比
当讨论Elasticsearch的时候,你将看到“索引”这个词被频繁地使用。这就是术语的使用。Elasticsearch索引被分解为多块:分片。一份分片是一个Lucene的索引,所以一个Elasticsearch的索引由多个Lucene的索引组成。这是合理的,因为Elasticsearch使用Apache Lucene作为核心的程序库进行数据的索引和搜索。
在下图中,你将看到聚会(get-together)索引的首个主分片可能包含何种信息。该分片称为get-together0,它是一个Lucene索引、一个倒排索引。它默认存储原始文档的内容,再加上一些额外的信息,如词条字典和词频,这些都能帮助到搜索。
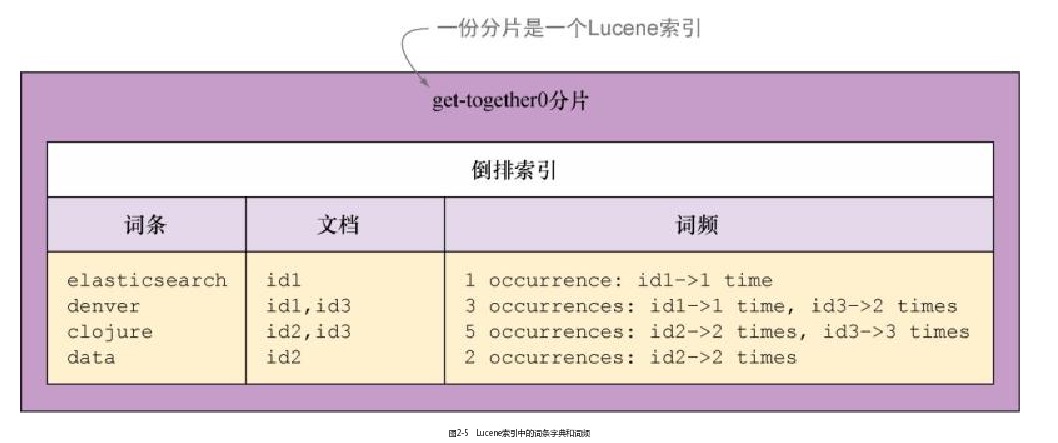
Lucene索引中的词条字典和词频词条字典将每个词条和包含该词条的文档映射起来。搜索的时候,Elasticsearch没有必要为了某个词条扫描所有的文档,而是根据这个字典快速地识别匹配的文档。
词频使得Elasticsearch可以快速地获取某篇文档中某个词条出现的次数。这对于计算结果的相关性得分非常重要。例如,如果搜索“denver”,包含多个“denver”的文档通常更为相关。Elasticsearch将给它们更高的得分,让它们出现在结果列表的更前面。
分片可以是主分片,也可以是副本分片,其中副本分片是主分片的完整副本。副本分片用于搜索,或者是在原有主分片丢失后成为新的主分片。
NOTICE:副本分片可以在运行的时候进行添加和移除,而主分片不可以。
以在任何时候改变每个分片的副本分片的数量,因为副本分片总是可以被创建和移除。这并不适用于索引划分为主分片的数量,在创建索引之前,你必须决定主分片的数量。请记住,过少的分片将限制可扩展性,但是过多的分片会影响性能。默认设置的5份是一个不错的开始。
3.5 在集群中分发分片
最简单的Elasticsearch集群只有一个节点:一台机器运行着一个Elasticsearch进程。在安装并启动了Elasticsearch之后,你就已经建立了一个拥有单节点的集群。
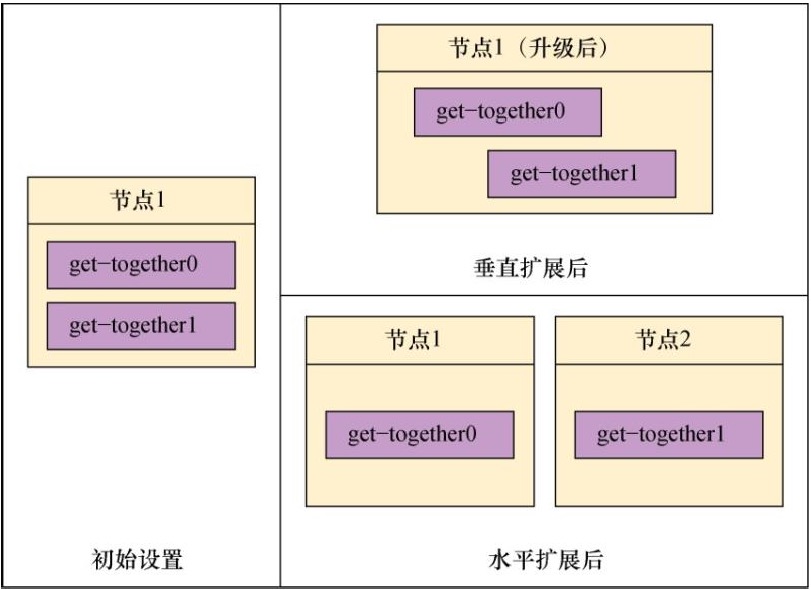
随着越来越多的节点被添加到同一个集群中,现有的分片将在所有的节点中进行负载均衡。因此,在那些分片上的索引和搜索请求都可以从额外增加的节点中获益。以这种方式进行扩展(在节点中加入更多节点)被称为水平扩展。此方式增加更多节点,然后请求被分发到这些节点上,工作负载就被分摊了。
水平扩展的另一个替代方案是垂直扩展,这种方式为Elasticsearch的节点增加更多硬件资源,可能是为虚拟机分配更多处理器,或是为物理机增加更多的内存。尽管垂直扩展几乎每次都能提升性能,它并非总是可行的或经济的。使用分片使得你可以进行水平的扩展。
假设你想扩展get-together索引,它有两个主分片,而没有副本分片。如下图所示,第一个选项是通过升级节点进行垂直扩展,如增加更多的内存、更多的CPU、更快的磁盘等。第二个选项是通过添加节点进行水平扩展,让数据在两个节点中分布。
3.6 分布式索引和搜索
你可能好奇在多个节点的多个分片上如何进行索引和搜索。
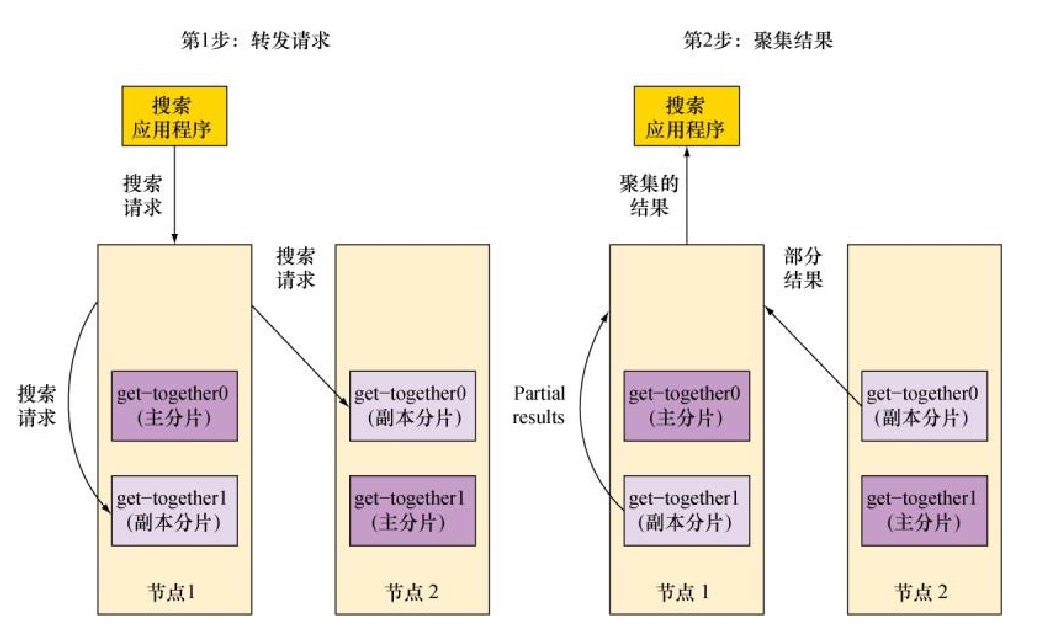
下图所示的索引。接受索引请求的Elasticsearch节点首先选择文档索引到哪个分片。默认地,文档在分片中均匀分布:对于每篇文档,分片是通过其ID字符串的散列决定的。每份分片拥有相同的散列范围,接收新文档的机会均等。一旦目标分片确定,接受请求的节点将文档转发到该分片所在的节点。随后,索引操作在所有目标分片的所有副本分片中进行。在所有可用副本分片完成文档的索引后,索引命令就会成功返回。
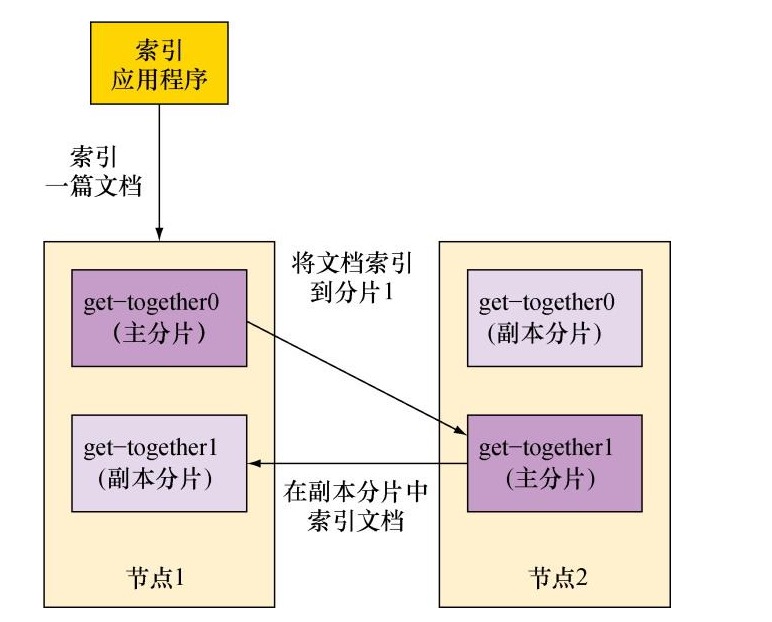
在搜索的时候,接受请求的节点将请求转发到一组包含所有数据的分片。Elasticsearch使用round-robin的轮询机制选择可用的分片(主分片或副本分片),并将搜索请求转发过去。如下图所示,Elasticsearch然后从这些分片收集结果,将其聚集到单一的回复,然后将回复返回给客户端应用程序。
四、索引新数据
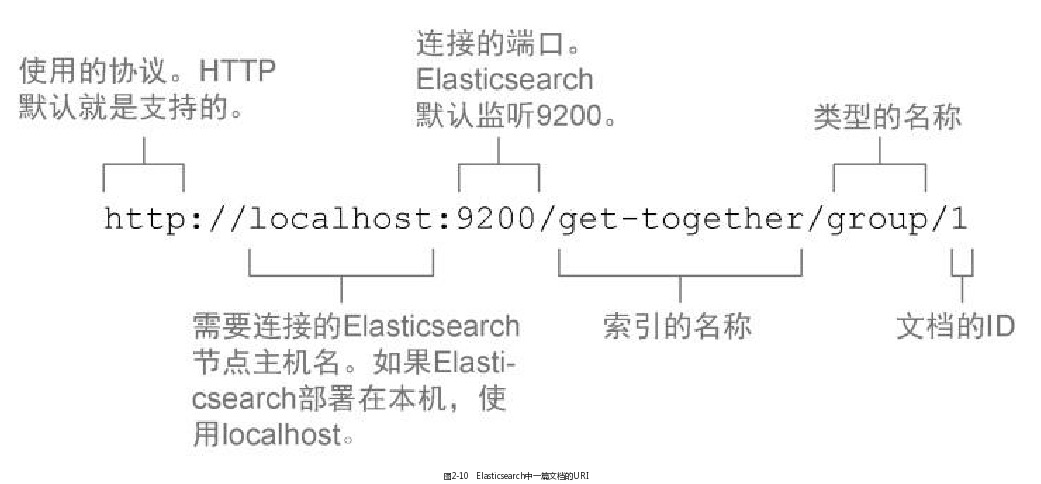
4.1 通过cURL索引一篇文档
% curl -XPUT 'localhost:9200/get-together/group/1?pretty' -d '{ "name":"Elasticsearch Denver",
"organizer":"Lee"
}
应该获得如下输出。
{ "_index":"get-together",
"_type":"group",
"_id":"1",
"_version":1,
"created":true
}
//回复中包含索引、类型和索引文档的ID。这种情况指定了ID,也有可能要依靠Elasticsearch来生成ID。
//这里还获得了文档的版本,它是从1开始并随着每次的更新而增加。
4.2 创建索引和映射类型
如果安装了Elasticsearch,并运行curl命令来索引文档,你可能好奇在这些因素下,为什么上述方法还能生效。
1、索引之前并不存在。并未发送任何命令来创建一个叫作get-together的索引。2、映射之前并未定义。没有定义任何称为group的映射类型来刻画文档中的字段。
这个curl命令之所以可以奏效,是因为Elasticsearch自动地添加了get-together索引,并且为group类型创建了一个新的映射。映射包含字符串字段的定义。默认情况下Elasticsearch处理所有这些,使得你无须任何事先的配置,就可以开始索引。
手动创建索引
//可以使用PUT请求来创建一个索引% curl -XPUT 'localhost:9200/new-index'
{"acknowledged":true}
创建索引本身比创建一篇文档要花费更多时间,所以你可能想让索引事先准备就绪。提前创建索引的另一个理由是想指定和Elasticsearch默认不同的设置,例如,你可能想确定分片的数量。
获取映射 之前提到,映射是随着新文档而自动创建的,而且Elasticsearch自动地将name和organizer字段识别为字符串。如果添加新文档的同时添加另一个新的字段,Elasticsearch也会猜测它的类型,并将其附加到映射。
为了查看当前的映射,发送一个HTTP GET“请求到该索引的_mapping端点。这将展示索引内所有类型的映射,但是可以通过在_mapping端点后指定类型的名字来获得某个具体的映射。
% curl 'localhost:9200/get-together/_mapping/group?pretty'五、搜索并获取数据
% curl "localhost:9200/get-together/group/_search?\q=elasticsearch ←——URL 指出在何处进行查询:在gettogether索引的group 类型中
&fields=name,location\ ←——URI 参数给出了搜索的细节:发现包含“elasticsearch”的文档,但是只返回排名靠前结果的name 和location 字段
&size=1\
&pretty"←——以可读性更好的格式输出JSON 应答
通常,一个查询在某个指定字段上运行,如q=name:elasticsearch,但是在这个例子中并没有指定任何字段,因为我们想在所有字段中搜索。实际上,Elasticsearch默认使用一个称为_all的字段,其中索引了所有字段的内容。
5.1 在哪里搜索
为了在多个类型中搜索,使用逗号分隔的列表。例如,为了同时在group和event类型中搜索,运行如下类似的命令:
% curl "localhost:9200/get-together/group,event/_search\?q=elasticsearch&pretty"
通过向索引ULR的_search端点发送请求,可以在某个索引的多个类型中搜索:
% curl 'localhost:9200/get-together/_search?q=sample&pretty'和类型类似,为了在多个索引中搜索,用逗号分隔它们:
% curl "localhost:9200/get-together,other-index/_search\?q=elasticsearch&pretty"
如果没有事先创建other-index,这个特定的请求将会失败。为了忽略这种问题,可以像添加pretty旗标那样添加ignore_unavailable旗标。为了在所有的索引中搜索,彻底省略索引的名称:
% curl 'localhost:9200/_search?q=elasticsearch&pretty'
5.2 回复的内容
{-----------------------------------------时间----------------------------------------------------------
"took":2, //花了多久处理请求,时间单位是毫秒
"timed_out":false, //表示搜索请求是否超时。默认情况下,搜索永远不会超时,但是可以通过timeout参数来设定限制(timeout=3s)
//如果搜索超时了,timed_out的值就是true,而且只能获得超时前所收集的结果。
-----------------------------------------分片----------------------------------------------------------
"_shards":{
"total":2, //查询了多少分片
"successful":2, //有多少成功的
"failed":0 //多少失败的
},
-----------------------------------------命中统计数据----------------------------------------------------------
"hits":{
"total":2, //匹配文档的总数
"max_score":0.9066504, //匹配文档的最高得分
-----------------------------------------结果文档-------------------------------------------------------
"hits":[{
"_index":"get-together", ←——结果数组
"_type":"group",
"_id":"3",
"_score":0.9066504,
"fields":{
"location":["San Francisco,California,USA"],
"name":["Elasticsearch San Francisco"]
}
}]
}
}
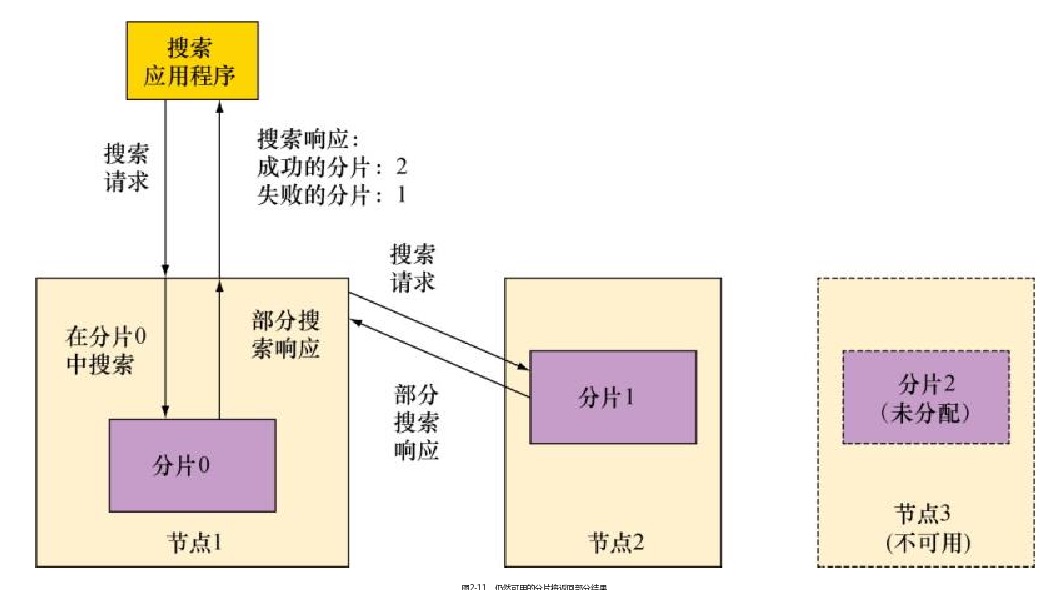
你可能好奇,当一个节点宕机而且一份分片无法回复搜索请求时,都会发生些什么?请看下图,展示了一个拥有3个节点的集群,每个节点只有一份分片且没有副本分片。如果某个节点宕机了,就会丢失某些数据。在这种情形下,Elasticsearch提供正常分片中的结果,并在failed字段中报告不可搜索的分片数量。
5.3 如何搜索
目前为止,你已经通过URI请求进行了搜索,之所以这么说是因为所有的搜索选项都是在URI里设置。对于在命令行上运行的简单搜索而言,URI请求非常棒,但是将其认作一种捷径更为妥当。
通常,要将查询放入组成请求的数据中。Elasticsearch允许使用JSON格式指定所有的搜索条件。当搜索变得越来越复杂的时候,JSON更容易读写,并且提供了更多的功能。
为了发送JSON查询来搜索所有关于Elasticsearch的分组(group),可以这样做:
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query":{
"query_string":{
"query":"elasticsearch"
}
}
}'
在自然语言中,它可以翻译为“运行一个类型为query_string的查询,字符串内容是elasticsearch”。可能看上去这样输入elasticsearch过于公式化,但这是因为JSON提供更多选项而不仅仅是URI请求。这里来探究一下每个字段。
设置查询的字符串选项
如果搜索“elasticsearch san Francisco”,Elasticsearch默认查询_all字段。如果想在分组的名称里查询,需要指定:
"default_field":"name"同样,Elasticsearch默认返回匹配了任一指定关键词的文档(默认的操作符是OR)。如果希望匹配所有的关键词,需要指定:
"default_operator":"AND"修改后的查询看上去是下面这样的:
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query":{
"query_string":{
"query":"elasticsearch san francisco",
"default_field":"name",
"default_operator":"AND"
}
}
}'
选择合适的查询类型 如果query_string查询类型看上去令人生畏,有个好消息是还有很多其他类型的查询例如,如果在name字段中只查找“elasticsearch”一个词,term查询可能更快捷、更直接。
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query":{
"term":{
"name":"elasticsearch"
}
}
}'
使用过滤器
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query":{
"filtered":{
"filter":{
"term":{
"name":"elasticsearch"
}
}
}
}
}'
应用聚集
% curl localhost:9200/get-together/group/_search?pretty -d '{ "aggregations":{
"organizers":{
"terms":{ "field":"organizer" }
}
}
}'
通过ID获取文档
% curl 'localhost:9200/get-together/group/1?pretty'回复包括所指定的索引、类型和ID。如果文档存在,你会发现found字段的值是true,此外还有其版本和源。如果文档不存在,found字段的值是false:
% curl 'localhost:9200/get-together/group/doesnt-exist?pretty'以上是 Elasticsearch 文档、类型和索引介绍 的全部内容, 来源链接: utcz.com/p/233418.html