Diff 算法原理
React 的 Reconciliation 算法原理
React 的渲染机制 Reconciliation 过程
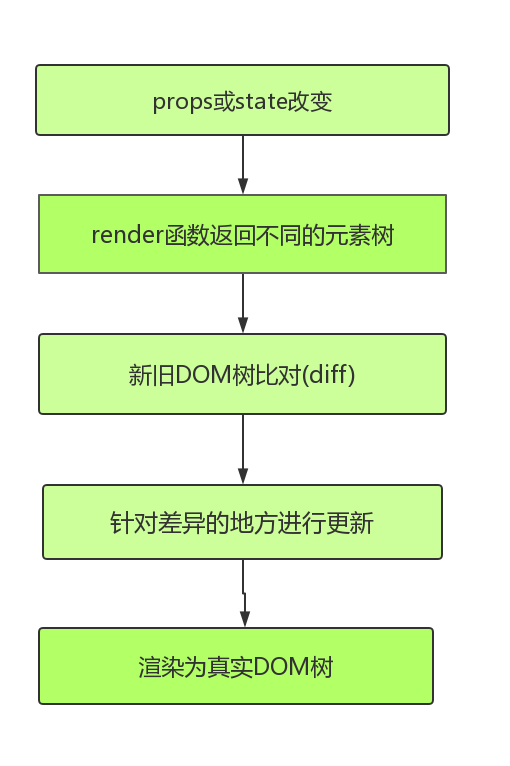
React 采用的是虚拟 DOM (即 VDOM ),每次属性 (props) 和状态 (state) 发生变化的时候,render 函数返回不同的元素树,React 会检测当前返回的元素树和上次渲染的元素树之前的差异,然后针对差异的地方进行更新操作,最后渲染为真实 DOM,这就是整个 Reconciliation 过程,其核心就是进行新旧 DOM 树对比的 diff 算法。
diff 算法
在某一时间节点调用 React 的
render()方法,会创建一棵由 React 元素组成的树。在下一次 state 或 props 更新时,相同的render()方法会返回一棵不同的树。React 需要基于这两棵树之间的差别来判断如何有效率的更新 UI 以保证当前 UI 与最新的树保持同步。
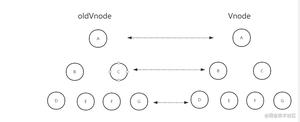
在上图第三部分,新旧DOM树比对所用的算法即 Diff算法
设计思想
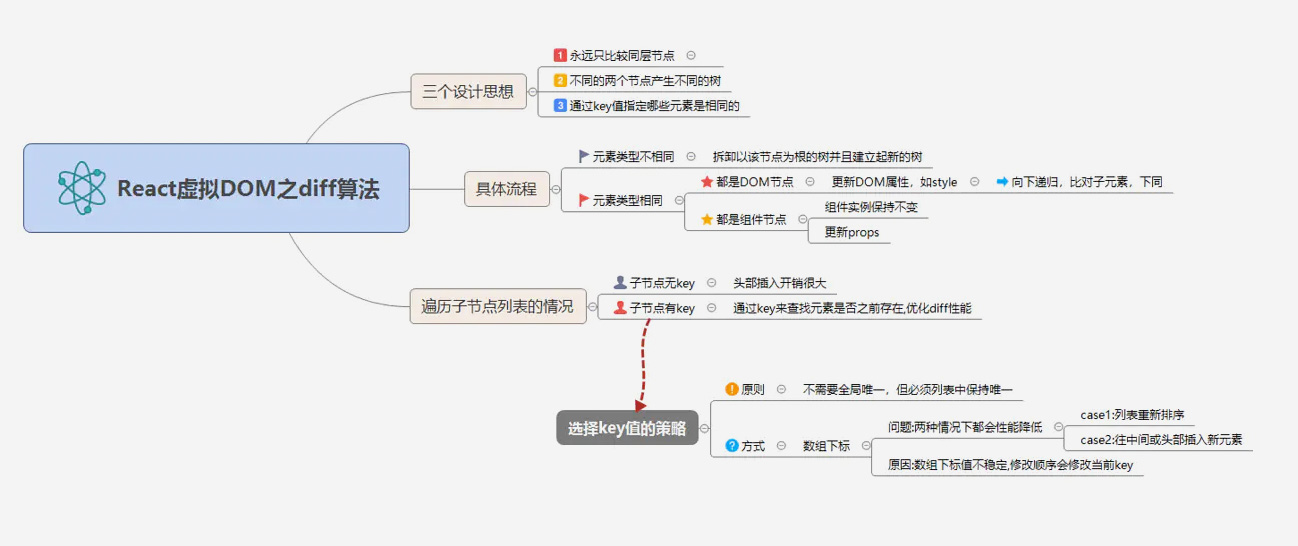
首先是设计思想,其实从一个树参照另一棵树进行更新,如果利用循环递归的方式对每一个节点进行比较,那算法的复杂度可以到达是 O (n^3), 通俗点来说 1000 个节点的树,要比对 10 亿次,还不包括比对类型、属性等等节点的细节,即使目前性能最高的 CPU 也很难再一秒内算出结果。
但是 React 说它的 diff 就是能达到 O (n) 级别。
React diff策略
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。【永远只比较同层节点,不会跨层级比较节点。】
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 key 进行区分。
基于以上三个前提策略,React 分别对 tree diff、component diff 以及 element diff 进行算法优化,事实也证明这三个前提策略是合理且准确的,它保证了整体界面构建的性能。
执行流程(规则)
1、元素类型不相同时
直接将
原 VDOM 树上该节点以及该节点下所有的后代节点全部删除,然后替换为新 VDOM 树上同一位置的节点
当根节点为不同类型的元素时,React 会拆卸原有的树并且建立起新的树。当拆卸一棵树时,对应的 DOM 节点也会被销毁。组件实例将执行 componentWillUnmount() 方法。当建立一棵新的树时,对应的 DOM 节点会被创建以及插入到 DOM 中。组件实例将执行 componentWillMount() 方法,紧接着 componentDidMount() 方法。所有跟之前的树所关联的 state 也会被销毁。
2. 元素类型相同时
a. 都是 DOM 节点
React 会保留 DOM 节点,仅比对及更新有改变的属性。
<div className="old" title="老节点" /><div className="new" title="新节点" />
通过比对这两个元素,React 知道需要修改 DOM 元素上的 className 属性和 title 属性。
处理完该节点后,React 继续对子节点进行递归。
b. 都是组件元素
- 对于同一类型的组件,根据Virtual DOM是否变化也分两种,可以用shouldComponentUpdate()判断Virtual DOM是否发生了变化,若没有变化就不需要再进行diff,这样可以节省大量时间,若变化了,就按原策略进行比较
- 对于非同一类的组件,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
当一个组件更新时,组件实例保持不变,这样 state 在跨越不同的渲染时保持一致。React 将更新该组件实例的 props 以跟最新的元素保持一致,并且调用该实例的 componentWillReceiveProps() 和 componentWillUpdate() 方法。
处理完该节点后,依然继续对子节点进行递归。
特殊情况讨论:遍历子元素列表
引入 key 值
首先,我们往列表末尾插入一个元素:
<ul> <li>1</li>
<li>2</li>
</ul>
插入后为:
<ul> <li>1</li>
<li>2</li>
<li>3</li>
</ul>
React 会先匹配两个对应的树,最后插入第三个元素,没有任何问题。
但是如果在头部插入呢?
<ul> <li>3</li>
<li>1</li>
<li>2</li>
</ul>
此时前两个元素和原来都不一样,第三个元素被当作新增的节点,明明只需要更新 1 个节点,现在更新了 3 个。这样的情况效率是非常低的。
于是,React 引入了 key 值的概念。
<ul> <li key="first">1</li>
<li key="second">2</li>
</ul>
插入之后变为:
<ul> <li key="third">3</li>
<li key="first">1</li>
<li key="second">2</li>
</ul>
现在 React 通过 key 得知 1 和 2 原来是存在的,现在只是换了位置,因此不需要更新整个节点了,只需要移动位置即可,大大提升效率。
选取 key 值的问题
key 选取的原一般是 不需要全局唯一,但必须列表中保持唯一。
有很多人喜欢用数组元素的下标作为 key 值,在元素顺序不改变的情况是没有问题的,但一旦顺序发生改变,diff 效率就有可能骤然下降。
举个例子,现在在五个元素中插入 F
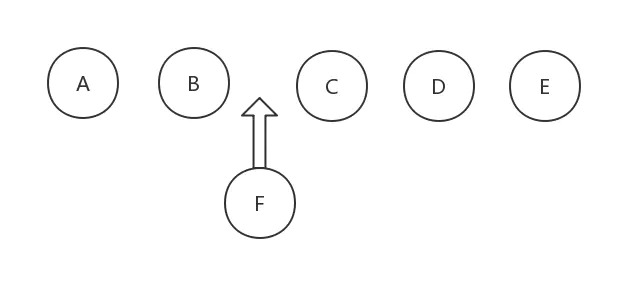
现在由于 F 的插入,后面的 C、D、E 索引值都改变,即 key 值改变,因此后面的节点都得更新。而且,数组乱序或者在头部插入都会导致同样的更新问题。
因此,不用数组索引做 key 值的根本原因在于:数组下标值不稳定,修改顺序会修改当前 key
当我们利用 key 值以后,上面的问题便迎刃而解,后面的 C、D、E 只需要向后挪动一个位置即可,真正需要更新的就只有新增的节点了。
以上是 Diff 算法原理 的全部内容, 来源链接: utcz.com/p/232947.html