Spring Cache的基本使用与实现原理详解
Spring Cache 概念
从Spring 3.1版本开始,提供了一种透明的方式来为现有的Spring 应用添加cache,使用起来就像@Transaction一样。在应用层面与后端存储之间,提供了一层抽象,这层抽象目的在于封装各种可插拔的后端存储( Ehcache Guava Redis),最小化因为缓存给现有业务代码带来的侵入。
Spring 的缓存技术还具备相当的灵活性。不仅能够使用 SpEL(Spring Expression Language)来定义缓存的 key 和各种 condition,还提供开箱即用的缓存暂时存储方案,也支持和主流的专业缓存比如 EHCache 集成。
其特点总结例如以下:
- 通过少量的配置 annotation 凝视就可以使得既有代码支持缓存
- 支持开箱即用 Out-Of-The-Box,即不用安装和部署额外第三方组件就可以使用缓存
- 支持 Spring Express Language,能使用对象的不论什么属性或者方法来定义缓存的 key 和 condition
- 支持 AspectJ,并通过事实上现不论什么方法的缓存支持
- 支持自己定义 key 和自己定义缓存管理者,具有相当的灵活性和扩展性
设计理念
正如Spring框架的其它服务一样,Spring cache 首先是提供了一层抽象,核心抽象主要体现在两个接口上
org.springframework.cache.Cache
org.springframework.cache.CacheManager
Cache代表缓存本身
CacheManager代表对缓存的处理和管理等。抽象的意义在于屏蔽实现细节的差异和提供扩展性,这一层Cache的抽象解耦了缓存的使用和缓存的后端存储,这样后续可以方便的更换后端存储。
使用Spring Cache分三步:
- 声明缓存
- 开启Spring的cache功能
- 配置后端的存储
声明缓存
@Cacheable("books")
public Book findBook(ISBN isbn) {...}
用法很简单,在方法上添加@cacheable等注解,表示缓存该方法的结果。
当方法有被调用时,先检查cache中有没有针对该方法相同参数的调用发生过,如果有,从cache中查询并返回结果。如果没有,则执行具体的方法逻辑,并把结果缓存到cache中。当然这一系列逻辑对于调用者来说都是透明的。其它的缓存操作的注解包含如下(详细说明可参见官方文档):
- @Cacheable triggers cache population
- @CacheEvict triggers cache eviction
- @CachePut updates the cache without interfering with the method execution
- @Caching regroups multiple cache operations to be applied on a method
- @CacheConfig shares some common cache-related settings at class-level
开启Spring Cache的支持
<cache:annotation-driven />
或者使用注解@EnableCaching的方式
配置缓存后端存储
Spring Cache提供了几种内置的后端存储的实现:下面都是CacheManager的具体实现。
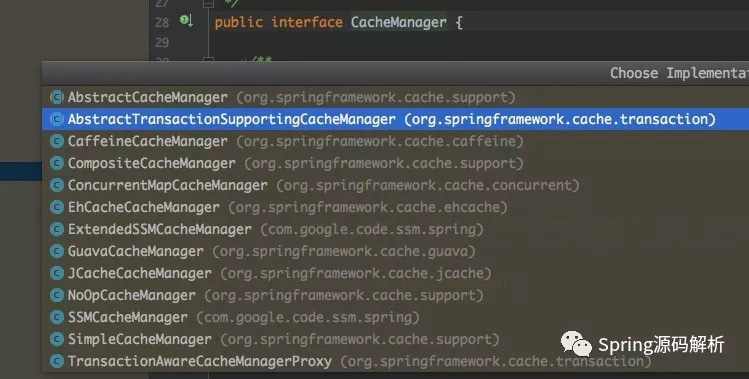
此外,Spring Data提供了两个缓存管理器:
- RedisCacheManager(来自于Spring Data Redis项目)
- GmfireCacheManager(来自于Spring Data GemFire项目
假如使用memcached或者redis等分布式缓存的话,可以自己实现Cache和CacheManager,然后在Context里声明即可。如果需要使用到多种不同的缓存实现,可以用组合模式把各种不同的CacheManager封装在一起。

缓存的key是如何生成
我们都知道缓存的存储方式一般是key value的方式,那么在Spring cache里,key是如何被设置的呢,在这里要引入KeyGenerator,它负责key的生成策略,默认的使用SimpleKeyGenerator
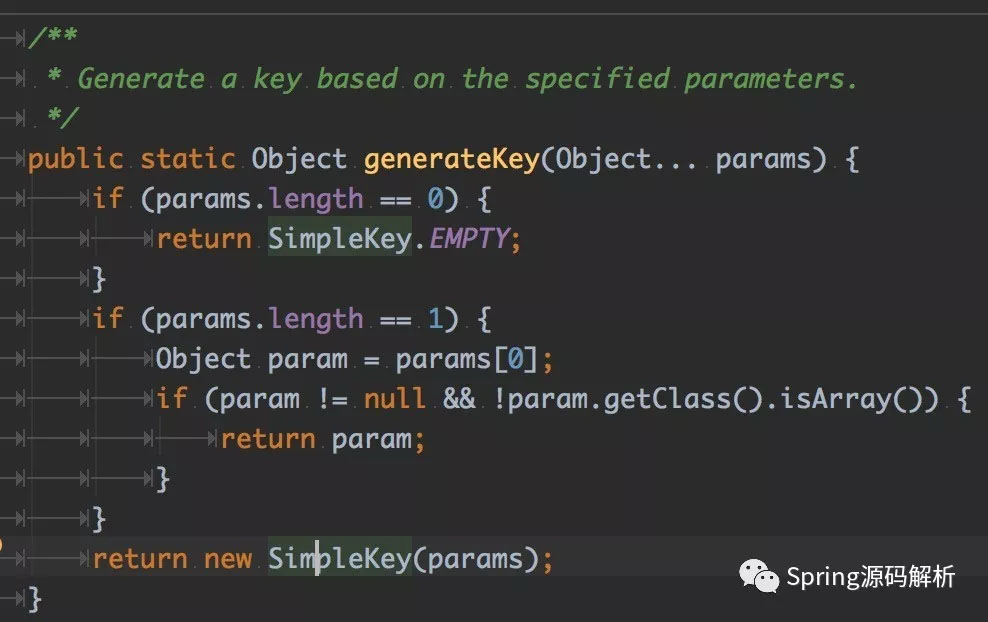

能看出来,其中就是有序参数数组的hash值。当然用户可以自定义key生成策略。
Spring Cache的实现
上面是Spring cache的大致使用方式,来看是Spring是如何实现的。
在学习Spring源码的时候,有两点可以记住:
- 大多数高级功能的实现都依赖Spring AOP
- 大多数功能的组装时机都依赖Sprin bean生命周期中的几个回调接口
记住了这些就比较容易理解Spring中的一些组件的实现及运行时机制
Spring cache也不例外,它是典型的Spring AOP实现,在Spring里,aop可以简单的理解为代理(AspectJ除外),我们声明了@Cacheable的方法的类,都会被代理,在代理中,实现缓存的查询与设置操作。
Cache 基础设施的创建
上一篇(Spring AOP 模块概述)谈到过,Spring AOP的创建过程,本质是实现了一个BeanPostProcessor,在创建bean的过程中创建proxy,并且为proxy绑定所有适用于该bean的advisor,最终暴露给容器。
Spring中AOP主几个关键的概念 advisor advice pointcut
advice = 切面拦截中插入的行为
pointcut = 切面的切入点
advisor = advice + pointcut
Spring cache也同样与其它aop有类似的过程
创建 cache proxy
- 由InfrastructureAdvisorAutoProxyCreator负责的,它实现BeanPostProcessor所以可以在bean实例化返回给容器前有机会创建代理,它又继承了AbstractAdvisorAutoProxyCreator,所以又具备了给代理类绑定advisor的能力。
- pointcut的职责是由CacheOperationSourcePointcut完成的,它主要是通过方法上的cache相关的注解来判断匹配是否需要切入
Cache的拦截行
Spring cache中生成cache代理对象使用的是CacheProxyFactoryBean工厂类。一般来说,在Spring中标准代理的创建都是基于ProxyFactoryBean,在这里,为了更方便的处理cache逻辑,Spring引入了CacheProxyFactoryBean来专门表示cache相关的代理,cache proxy能wrapper单例目标对象,并且代理目标对象实现的所有接口。
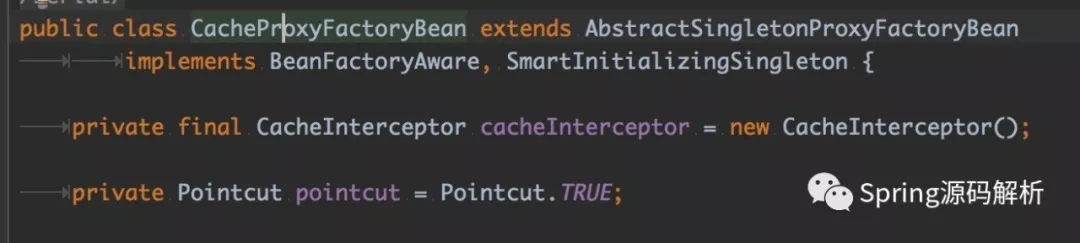
可以看到,在CacheProxyFactoryBean中,有个重要的属性是CacheInterceptor,这个类是一个MethodInterceptor的实现类,这个类的职责是在目标对象目标方法上执行具体缓存操作,这也就是上面提到的advice的职责。

继续往下跟,return 的execute方法是父类CacheAspectSupport中的方法

在这个方法里,我们最终找到的操作缓存的最终逻辑
- 判断缓存条件
- 获取key
- 获取cache
- 最终调用cache.get(key, Callable)方法,第二个参数是一个回调,用于处理没有命中缓存的情况:
if cached, return; otherwise create, cache and return
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
以上是 Spring Cache的基本使用与实现原理详解 的全部内容, 来源链接: utcz.com/p/216290.html