
如何在Ubuntu 18.04中使用Keras,Tensorflow和Python 3实现图像搜索引擎
本文概述
图片搜索引擎会分析图片并提出一些基本问题, 例如图片上是否有一张脸或多于一张?图像上出现哪种颜色?频率如何?分辨率是多少?然后, 搜索者可以根据此信息缩小搜索范围。当然, 这是一个非常大的主题, 我们不会深入解释, 但是我们将向你介绍如何使用一些工具来实现自己的图像搜索引擎, 这些工具已经准备就绪, 可以根据需要完全正常工作, 如果没有, , 你当然可以对其进行修改, 使其与你自己的需求相匹配。
在本文中, 我们将向你简要说明如何在Ubuntu 18.04中使用Keras和Tensorflow和Python快速实现自己的图像搜索引擎。
要求
你将需要在系统和Pip 3上安装Python 3, 你可以使用以下命令分别在Ubuntu系统上安装它们:
sudo apt-get install python3和点:
sudo apt-get install python3-pip话虽如此, 让我们开始吧!
1.克隆SIS项目并安装依赖项
为了使用上述技术实现你自己的本地图像搜索引擎, 我们将依靠一个开源项目SIS。简单图像搜索引擎是@ matsui528由Scratch编写的图像搜索引擎, 他是日本东京大学工业科学研究所的助理教授。
首先, 在终端中使用以下命令使用Git克隆项目的源代码(如果你没有git, 请使用sudo apt-get install git进行安装):
git clone https://github.com/matsui528/sis.git该项目最初非常轻巧, 因为它仅包含62行(python)+ 24行(html)。克隆源代码后, 使用以下命令切换到sis目录:
cd sis并继续使用Pip安装项目的依赖项。你可以通过以下方式从项目提供的列表中安装它们:
pip3 install -r requirements.txt这将安装5个依赖项:
- 枕头:枕头是Alex Clark和Contributors友好的PIL叉子。 PIL是Fredrik Lundh和贡献者提供的Python Imaging Library。
- h5py:h5py软件包是HDF5二进制数据格式的Pythonic接口。它使你可以存储大量的数值数据, 并轻松地从NumPy中操纵该数据。
- tensorflow:帮助你开发和训练ML模型的核心开源库。直接在浏览器中运行Colab笔记本即可快速入门。
- Keras:Keras是一个高级神经网络API, 用Python编写, 并且能够在TensorFlow, CNTK或Theano之上运行。它的开发着眼于实现快速实验。
- Flask:Flask是基于Werkzeug, Jinja 2和良好意图的Python微框架。它将用于显示搜索引擎的图形结果, 因此, 当你上传文件时, 它将被分析, 并返回与你的搜索匹配的图像。
有关此项目的更多信息, 请访问Github上的官方资源库。
2.存储你的图像
现在已经下载了项目并安装了所有依赖项, 我们可以继续进行一些手动工作。在项目结构内部, 你将需要存储”图像数据库”的图像(与查询图像相比)。
在目录/ sis / static / img内存储所有你希望用作参考的图像, 并且用户可以搜索这些图像。所有图像都必须为JPEG格式:
这一步完全取决于你, 你将决定项目将能够提供的信息和图像种类。有了它们后, 我们将能够在下一步中提取信息。
3.生成每个图像的PKL文件
该脚本从图像中提取深层功能。给定一组数据库图像, 使用具有ImageNet预训练权重的VGG16网络为每个图像提取4096D fc6功能。要生成pkl文件, 请使用python在sis的根目录上运行offline.py脚本:
python3 offline.py由于其深度和完全连接的节点数, VGG16已超过533MB。首次运行脚本后, 将下载该文件。
运行脚本后, 你将找到带有图片信息的新二进制文件。 FeatureExtractor类(Keras模型)提取的信息将使用pickle序列化为/ sis / static / feature目录中的PKL二进制文件:
Tensorflow将使用它们来匹配你在后台逻辑上的图像查询。
4.使用Web界面进行测试
现在, 如在依赖项安装过程中提到的那样, 该项目带有一个基于使用Flask构建的Web界面的现成示例。该界面(基本上是一个简单的HTML页面, 具有单个文件输入和一些标题), 可让你将文件上传到同一页面, 并作为结果返回与搜索相关的图像。你可以启动运行server.py脚本的服务器:
python3 server.py这将在http://0.0.0.0:5000上启动演示, 你可以对其进行测试(只要你的数据库中已经有一些图像):
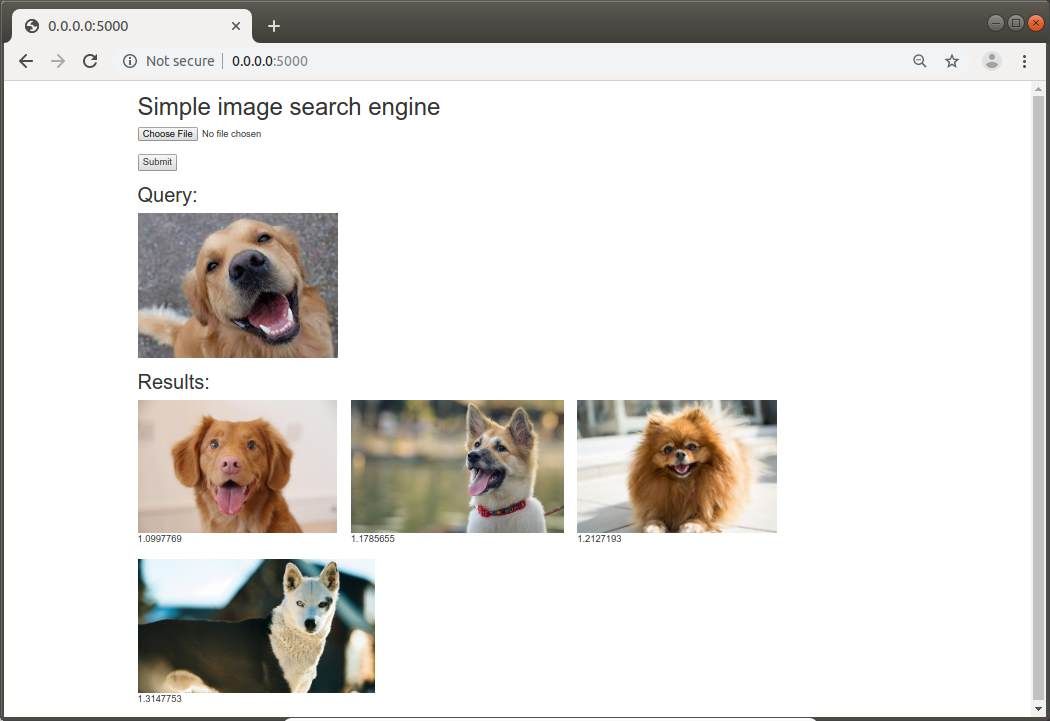
如在示例中所见, 背景中的逻辑对具有不确定性值的图像进行分类, 其值越接近1且值越小, 则匹配度越高。
自定义逻辑
当然, 由于项目是开源的, 因此你可以修改项目的工作方式。你也可以简单地创建一个Python脚本, 该脚本仅打印终端中所需的数据, 与查询匹配的项目的顺序等等。例如, 创建具有以下内容的以下文件custom.py:
# Our Code World custom implementation# Read article at:
# https://ourcodeworld.com/articles/read/981/how-to-implement-an-image-search-engine-using-keras-tensorflow-with-python-3-in-ubuntu-18-04
import os
import numpy as np
from PIL import Image
from feature_extractor import FeatureExtractor
import glob
import pickle
import json
if __name__=="__main__":
fe = FeatureExtractor()
features = []
img_paths = []
# Append every generated PKL file into an array and the image version as well
for feature_path in glob.glob("static/feature/*"):
features.append(pickle.load(open(feature_path, 'rb')))
img_paths.append('static/img/' + os.path.splitext(os.path.basename(feature_path))[0] + '.jpg')
# Define the query image, in our case it will be a hamburguer
img = Image.open("/home/ourcodeworld/Desktop/hamburguer_query.jpg") # PIL image
# Search for matches
query = fe.extract(img)
dists = np.linalg.norm(features - query, axis=1) # Do search
ids = np.argsort(dists)[:30] # Top 30 results
scores = [(dists[id], img_paths[id]) for id in ids]
# Store results in a dictionary
results = []
for item in scores:
results.append({
"filename" : item[1], "uncertainty": str(item[0])
})
# Create a JSON file with the results
with open('data.json', 'w') as outputfile:
json.dump(results, outputfile, ensure_ascii=False, indent=4)
并运行:
python3 custom.py这将创建一个JSON文件, 其中包含与查询匹配的图像的有序列表, 在我们的示例中, 我们使用汉堡包进行搜索, 如你所见, 第一个项目是汉堡包的图像:
[ {
"filename": "static/img/hamburguer_4.jpg", "uncertainty": "0.95612574"
}, {
"filename": "static/img/hamburguer_2.jpg", "uncertainty": "1.0821809"
}, {
"filename": "static/img/hamburguer_3.jpg", "uncertainty": "1.099425"
}, {
"filename": "static/img/hamburguer.jpg", "uncertainty": "1.1565413"
}, {
"filename": "static/img/hot_dog2.jpg", "uncertainty": "1.1644002"
}, {
"filename": "static/img/hot_dog_5.jpg", "uncertainty": "1.2176604"
}, {
"filename": "static/img/portrait-if-a-spitz-pomeranian_t20_v3o29E-5ae9bbdca18d9e0037d95983.jpg", "uncertainty": "1.262754"
}, {
"filename": "static/img/smiley_dog.jpg", "uncertainty": "1.3276863"
}, {
"filename": "static/img/golden-retriever-puppy.jpg", "uncertainty": "1.3307321"
}, {
"filename": "static/img/husky-winter-dogsled_h.jpg", "uncertainty": "1.3511014"
}
]
此实现非常有用, 因为你还可以过滤不确定性大于1.0的图像。了解此自定义示例将帮助你在自己的项目中实现此逻辑, 并创建例如某种API。
特别感谢和资源
没有以下来源的宝贵信息和资源, 本文将是不可能的:
- VGG16 –用于分类和检测的卷积网络
你也可以阅读它们, 以补充本文中所有已学到的知识。
编码愉快!
以上是 如何在Ubuntu 18.04中使用Keras,Tensorflow和Python 3实现图像搜索引擎 的全部内容, 来源链接: utcz.com/p/204209.html







