【JS】【转】vue模板编译原理
写在开头
写过 Vue 的同学肯定体验过, .vue 这种单文件组件有多么方便。但是我们也知道,Vue 底层是通过虚拟 DOM 来进行渲染的,那么 .vue 文件的模板到底是怎么转换成虚拟 DOM 的呢?这一块对我来说一直是个黑盒,之前也没有深入研究过,今天打算一探究竟。

<center>Virtual Dom</center>
Vue 3 发布之后,本来想着直接看看 Vue 3 的模板编译,但是我打开 Vue 3 源码的时候,发现我好像连 Vue 2 是怎么编译模板的都不知道。从小鲁迅就告诉我们,不能一口吃成一个胖子,那我只能回头看看 Vue 2 的模板编译源码,至于 Vue 3 就留到正式发布的时候再看。
Vue 的版本
很多人使用 Vue 的时候,都是直接通过 vue-cli 生成的模板代码,并不知道 Vue 其实提供了两个构建版本。
vue.js:完整版本,包含了模板编译的能力;vue.runtime.js:运行时版本,不提供模板编译能力,需要通过 vue-loader 进行提前编译。

<center>Vue 不同构建版本</center>

<center>完整版与运行时版区别</center>
简单来说,就是如果你用了 vue-loader ,就可以使用 vue.runtime.min.js,将模板编译的过程交过 vue-loader,如果你是在浏览器中直接通过 script 标签引入 Vue,需要使用 vue.min.js,运行的时候编译模板。
编译入口
了解了 Vue 的版本,我们看看 Vue 完整版的入口文件(src/platforms/web/entry-runtime-with-compiler.js)。
// 省略了部分代码,只保留了关键部分import { compileToFunctions } from './compiler/index'
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function (el) {
const options = this.$options
// 如果没有 render 方法,则进行 template 编译
if (!options.render) {
let template = options.template
if (template) {
// 调用 compileToFunctions,编译 template,得到 render 方法
const { render, staticRenderFns } = compileToFunctions(
template,
{
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments,
},
this
)
// 这里的 render 方法就是生成生成虚拟 DOM 的方法
options.render = render
}
}
return mount.call(this, el, hydrating)
}
再看看 ./compiler/index 文件的 compileToFunctions 方法从何而来。
import { baseOptions } from './options'import { createCompiler } from 'compiler/index'
// 通过 createCompiler 方法生成编译函数
const { compile, compileToFunctions } = createCompiler(baseOptions)
export { compile, compileToFunctions }
后续的主要逻辑都在 compiler 模块中,这一块有些绕,因为本文不是做源码分析,就不贴整段源码了。简单看看这一段的逻辑是怎么样的。
export function createCompiler(baseOptions) {const baseCompile = (template, options) => {
// 解析 html,转化为 ast
const ast = parse(template.trim(), options)
// 优化 ast,标记静态节点
optimize(ast, options)
// 将 ast 转化为可执行代码
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns,
}
}
const compile = (template, options) => {
const tips = []
const errors = []
// 收集编译过程中的错误信息
options.warn = (msg, tip) => {
;(tip ? tips : errors).push(msg)
}
// 编译
const compiled = baseCompile(template, options)
compiled.errors = errors
compiled.tips = tips
return compiled
}
const createCompileToFunctionFn = () => {
// 编译缓存
const cache = Object.create(null)
return (template, options, vm) => {
// 已编译模板直接走缓存
if (cache[template]) {
return cache[template]
}
const compiled = compile(template, options)
return (cache[key] = compiled)
}
}
return {
compile,
compileToFunctions: createCompileToFunctionFn(compile),
}
}
主流程
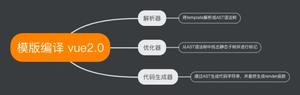
可以看到主要的编译逻辑基本都在 baseCompile 方法内,主要分为三个步骤:
- 模板编译,将模板代码转化为 AST;
- 优化 AST,方便后续虚拟 DOM 更新;
- 生成代码,将 AST 转化为可执行的代码;
const baseCompile = (template, options) => {// 解析 html,转化为 ast
const ast = parse(template.trim(), options)
// 优化 ast,标记静态节点
optimize(ast, options)
// 将 ast 转化为可执行代码
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns,
}
}
parse
AST
首先看到 parse 方法,该方法的主要作用就是解析 HTML,并转化为 AST(抽象语法树),接触过 ESLint、Babel 的同学肯定对 AST 不陌生,我们可以先看看经过 parse 之后的 AST 长什么样。
下面是一段普普通通的 Vue 模板:
new Vue({el: '#app',
template: `<div> <h2 v-if="message">{{message}}</h2> <button @click="showName">showName</button> </div>`,
data: {
name: 'shenfq',
message: 'Hello Vue!',
},
methods: {
showName() {
alert(this.name)
},
},
})
经过 parse 之后的 AST:
<center>Template AST</center>
AST 为一个树形结构的对象,每一层表示一个节点,第一层就是 div(tag: "div")。div 的子节点都在 children 属性中,分别是 h2 标签、空行、button 标签。我们还可以注意到有一个用来标记节点类型的属性:type,这里 div 的 type 为 1,表示是一个元素节点,type 一共有三种类型:
- 元素节点;
- 表达式;
- 文本;
在h2和button标签之间的空行就是 type 为 3 的文本节点,而 h2 标签下就是一个表达式节点。

<center>节点类型</center>
解析 HTML
parse 的整体逻辑较为复杂,我们可以先简化一下代码,看看 parse 的流程。
import { parseHTML } from './html-parser'export function parse(template, options) {
let root
parseHTML(template, {
// some options...
start() {}, // 解析到标签位置开始的回调
end() {}, // 解析到标签位置结束的回调
chars() {}, // 解析到文本时的回调
comment() {}, // 解析到注释时的回调
})
return root
}
可以看到 parse 主要通过 parseHTML 进行工作,这个 parseHTML 本身来自于开源库:simple html parser,只不过经过了 Vue 团队的一些修改,修复了相关 issue。

HTML parser
下面我们一起来理一理 parseHTML 的逻辑。
export function parseHTML(html, options) {let index = 0
let last, lastTag
const stack = []
while (html) {
last = html
let textEnd = html.indexOf('<')
// "<" 字符在当前 html 字符串开始位置
if (textEnd === 0) {
// 1、匹配到注释: <!-- -->
if (/^<!\--/.test(html)) {
const commentEnd = html.indexOf('-->')
if (commentEnd >= 0) {
// 调用 options.comment 回调,传入注释内容
options.comment(html.substring(4, commentEnd))
// 裁切掉注释部分
advance(commentEnd + 3)
continue
}
}
// 2、匹配到条件注释: <![if !IE]> <![endif]>
if (/^<!\[/.test(html)) {
// ... 逻辑与匹配到注释类似
}
// 3、匹配到 Doctype: <!DOCTYPE html>
const doctypeMatch = html.match(/^<!DOCTYPE [^>]+>/i)
if (doctypeMatch) {
// ... 逻辑与匹配到注释类似
}
// 4、匹配到结束标签: </div>
const endTagMatch = html.match(endTag)
if (endTagMatch) {
}
// 5、匹配到开始标签: <div>
const startTagMatch = parseStartTag()
if (startTagMatch) {
}
}
// "<" 字符在当前 html 字符串中间位置
let text, rest, next
if (textEnd > 0) {
// 提取中间字符
rest = html.slice(textEnd)
// 这一部分当成文本处理
text = html.substring(0, textEnd)
advance(textEnd)
}
// "<" 字符在当前 html 字符串中不存在
if (textEnd < 0) {
text = html
html = ''
}
// 如果存在 text 文本
// 调用 options.chars 回调,传入 text 文本
if (options.chars && text) {
// 字符相关回调
options.chars(text)
}
}
// 向前推进,裁切 html
function advance(n) {
index += n
html = html.substring(n)
}
}
上述代码为简化后的 parseHTML,while 循环中每次截取一段 html 文本,然后通过正则判断文本的类型进行处理,这就类似于编译原理中常用的有限状态机。每次拿到 "<" 字符前后的文本,"<" 字符前的就当做文本处理,"<" 字符后的通过正则判断,可推算出有限的几种状态。

<center>html 的几种状态</center>
其他的逻辑处理都不复杂,主要是开始标签与结束标签,我们先看看关于开始标签与结束标签相关的正则。
const ncname = '[a-zA-Z_][\\w\\-\\.]*'const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
这段正则看起来很长,但是理清之后也不是很难。这里推荐一个正则可视化工具。我们到工具上看看 startTagOpen:

<center>startTagOpen</center>
这里比较疑惑的点就是为什么 tagName 会存在 :,这个是 XML 的 命名空间,现在已经很少使用了,我们可以直接忽略,所以我们简化一下这个正则:
const ncname = '[a-zA-Z_][\\w\\-\\.]_'const startTagOpen = new RegExp(`^<${ncname}`)
const startTagClose = /^\s_(\/?)>/
const endTag = new RegExp(`^<\\/${ncname}[^>]*>`)

<center>startTagOpen</center>

<center>endTag</center>
除了上面关于标签开始和结束的正则,还有一段用来提取标签属性的正则,真的是又臭又长。
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']\*)'+|([^\s"'=<>`]+)))?/把正则放到工具上就一目了然了,以 = 为分界,前面为属性的名字,后面为属性的值。

<center>attribute</center>
理清正则后可以更加方便我们看后面的代码。
while (html) {last = html
let textEnd = html.indexOf('<')
// "<" 字符在当前 html 字符串开始位置
if (textEnd === 0) {
// some code ...
// 4、匹配到标签结束位置: </div>
const endTagMatch = html.match(endTag)
if (endTagMatch) {
const curIndex = index
advance(endTagMatch[0].length)
parseEndTag(endTagMatch[1], curIndex, index)
continue
}
// 5、匹配到标签开始位置: <div>
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
continue
}
}
}
// 向前推进,裁切 html
function advance(n) {
index += n
html = html.substring(n)
}
// 判断是否标签开始位置,如果是,则提取标签名以及相关属性
function parseStartTag() {
// 提取 <xxx
const start = html.match(startTagOpen)
if (start) {
const [fullStr, tag] = start
const match = {
attrs: [],
start: index,
tagName: tag,
}
advance(fullStr.length)
let end, attr
// 递归提取属性,直到出现 ">" 或 "/>" 字符
while (
!(end = html.match(startTagClose)) &&
(attr = html.match(attribute))
) {
advance(attr[0].length)
match.attrs.push(attr)
}
if (end) {
// 如果是 "/>" 表示单标签
match.unarySlash = end[1]
advance(end[0].length)
match.end = index
return match
}
}
}
// 处理开始标签
function handleStartTag(match) {
const tagName = match.tagName
const unary = match.unarySlash
const len = match.attrs.length
const attrs = new Array(len)
for (let i = 0; i < l; i++) {
const args = match.attrs[i]
// 这里的 3、4、5 分别对应三种不同复制属性的方式
// 3: attr="xxx" 双引号
// 4: attr='xxx' 单引号
// 5: attr=xxx 省略引号
const value = args[3] || args[4] || args[5] || ''
attrs[i] = {
name: args[1],
value,
}
}
if (!unary) {
// 非单标签,入栈
stack.push({
tag: tagName,
lowerCasedTag: tagName.toLowerCase(),
attrs: attrs,
})
lastTag = tagName
}
if (options.start) {
// 开始标签的回调
options.start(tagName, attrs, unary, match.start, match.end)
}
}
// 处理闭合标签
function parseEndTag(tagName, start, end) {
let pos, lowerCasedTagName
if (start == null) start = index
if (end == null) end = index
if (tagName) {
lowerCasedTagName = tagName.toLowerCase()
}
// 在栈内查找相同类型的未闭合标签
if (tagName) {
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
pos = 0
}
if (pos >= 0) {
// 关闭该标签内的未闭合标签,更新堆栈
for (let i = stack.length - 1; i >= pos; i--) {
if (options.end) {
// end 回调
options.end(stack[i].tag, start, end)
}
}
// 堆栈中删除已关闭标签
stack.length = pos
lastTag = pos && stack[pos - 1].tag
}
}
在解析开始标签的时候,如果该标签不是单标签,会将该标签放入到一个堆栈当中,每次闭合标签的时候,会从栈顶向下查找同名标签,直到找到同名标签,这个操作会闭合同名标签上面的所有标签。接下来我们举个例子:
<div><h2>test</h2>
<p>
<p>
</div>
在解析了 div 和 h2 的开始标签后,栈内就存在了两个元素。h2 闭合后,就会将 h2 出栈。然后会解析两个未闭合的 p 标签,此时,栈内存在三个元素(div、p、p)。如果这个时候,解析了 div 的闭合标签,除了将 div 闭合外,div 内两个未闭合的 p 标签也会跟随闭合,此时栈被清空。
为了便于理解,特地录制了一个动图,如下:

<center>入栈与出栈</center>
理清了 parseHTML 的逻辑后,我们回到调用 parseHTML 的位置,调用该方法的时候,一共会传入四个回调,分别对应标签的开始和结束、文本、注释。
parseHTML(template, {// some options...
// 解析到标签位置开始的回调
start(tag, attrs, unary) {},
// 解析到标签位置结束的回调
end(tag) {},
// 解析到文本时的回调
chars(text: string) {},
// 解析到注释时的回调
comment(text: string) {},
})
处理开始标签
首先看解析到开始标签时,会生成一个 AST 节点,然后处理标签上的属性,最后将 AST 节点放入树形结构中。
function makeAttrsMap(attrs) {const map = {}
for (let i = 0, l = attrs.length; i < l; i++) {
const { name, value } = attrs[i]
map[name] = value
}
return map
}
function createASTElement(tag, attrs, parent) {
const attrsList = attrs
const attrsMap = makeAttrsMap(attrsList)
return {
type: 1, // 节点类型
tag, // 节点名称
attrsMap, // 节点属性映射
attrsList, // 节点属性数组
parent, // 父节点
children: [], // 子节点
}
}
const stack = []
let root // 根节点
let currentParent // 暂存当前的父节点
parseHTML(template, {
// some options...
// 解析到标签位置开始的回调
start(tag, attrs, unary) {
// 创建 AST 节点
let element = createASTElement(tag, attrs, currentParent)
// 处理指令: v-for v-if v-once
processFor(element)
processIf(element)
processOnce(element)
processElement(element, options)
// 处理 AST 树
// 根节点不存在,则设置该元素为根节点
if (!root) {
root = element
checkRootConstraints(root)
}
// 存在父节点
if (currentParent) {
// 将该元素推入父节点的子节点中
currentParent.children.push(element)
element.parent = currentParent
}
if (!unary) {
// 非单标签需要入栈,且切换当前父元素的位置
currentParent = element
stack.push(element)
}
},
})
处理结束标签
标签结束的逻辑就比较简单了,只需要去除栈内最后一个未闭合标签,进行闭合即可。
parseHTML(template, {// some options...
// 解析到标签位置结束的回调
end() {
const element = stack[stack.length - 1]
const lastNode = element.children[element.children.length - 1]
// 处理尾部空格的情况
if (lastNode && lastNode.type === 3 && lastNode.text === ' ') {
element.children.pop()
}
// 出栈,重置当前的父节点
stack.length -= 1
currentParent = stack[stack.length - 1]
},
})
处理文本
处理完标签后,还需要对标签内的文本进行处理。文本的处理分两种情况,一种是带表达式的文本,还一种就是纯静态的文本。
parseHTML(template, {// some options...
// 解析到文本时的回调
chars(text) {
if (!currentParent) {
// 文本节点外如果没有父节点则不处理
return
}
const children = currentParent.children
text = text.trim()
if (text) {
// parseText 用来解析表达式
// delimiters 表示表达式标识符,默认为 ['{{', '}}']
const res = parseText(text, delimiters))
if (res) {
// 表达式
children.push({
type: 2,
expression: res.expression,
tokens: res.tokens,
text
})
} else {
// 静态文本
children.push({
type: 3,
text
})
}
}
}
})
下面我们看看 parseText 如何解析表达式。
// 构造匹配表达式的正则const buildRegex = (delimiters) => {
const open = delimiters[0]
const close = delimiters[1]
return new RegExp(open + '((?:.|\\n)+?)' + close, 'g')
}
function parseText(text, delimiters) {
// delimiters 默认为 {{ }}
const tagRE = buildRegex(delimiters || ['{{', '}}'])
// 未匹配到表达式,直接返回
if (!tagRE.test(text)) {
return
}
const tokens = []
const rawTokens = []
let lastIndex = (tagRE.lastIndex = 0)
let match, index, tokenValue
while ((match = tagRE.exec(text))) {
// 表达式开始的位置
index = match.index
// 提取表达式开始位置前面的静态字符,放入 token 中
if (index > lastIndex) {
rawTokens.push((tokenValue = text.slice(lastIndex, index)))
tokens.push(JSON.stringify(tokenValue))
}
// 提取表达式内部的内容,使用 \_s() 方法包裹
const exp = match[1].trim()
tokens.push(`_s(${exp})`)
rawTokens.push({ '@binding': exp })
lastIndex = index + match[0].length
}
// 表达式后面还有其他静态字符,放入 token 中
if (lastIndex < text.length) {
rawTokens.push((tokenValue = text.slice(lastIndex)))
tokens.push(JSON.stringify(tokenValue))
}
return {
expression: tokens.join('+'),
tokens: rawTokens,
}
}
首先通过一段正则来提取表达式:

<center>提取表达式</center>
看代码可能有点难,我们直接看例子,这里有一个包含表达式的文本。
<div>是否登录:{{isLogin ? '是' : '否'}}</div>
<center>运行结果</center>

<center>解析文本</center>
optimize
通过上述一些列处理,我们就得到了 Vue 模板的 AST。由于 Vue 是响应式设计,所以拿到 AST 之后还需要进行一系列优化,确保静态的数据不会进入虚拟 DOM 的更新阶段,以此来优化性能。
export function optimize(root, options) {if (!root) return
// 标记静态节点
markStatic(root)
}
简单来说,就是把所以静态节点的 static 属性设置为 true。
function isStatic(node) {if (node.type === 2) {
// 表达式,返回 false
return false
}
if (node.type === 3) {
// 静态文本,返回 true
return true
}
// 此处省略了部分条件
return !!(
(
!node.hasBindings && // 没有动态绑定
!node.if &&
!node.for && // 没有 v-if/v-for
!isBuiltInTag(node.tag) && // 不是内置组件 slot/component
!isDirectChildOfTemplateFor(node) && // 不在 template for 循环内
Object.keys(node).every(isStaticKey)
) // 非静态节点
)
}
function markStatic(node) {
node.static = isStatic(node)
if (node.type === 1) {
// 如果是元素节点,需要遍历所有子节点
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i]
markStatic(child)
if (!child.static) {
// 如果有一个子节点不是静态节点,则该节点也必须是动态的
node.static = false
}
}
}
}
generate
得到优化的 AST 之后,就需要将 AST 转化为 render 方法。还是用之前的模板,先看看生成的代码长什么样:
<div><h2 v-if="message">{{message}}</h2>
<button @click="showName">showName</button>
</div>
{render: "with(this){return \_c('div',[(message)?\_c('h2',[_v(_s(message))]):\_e(),\_v(" "),\_c('button',{on:{"click":showName}},[_v("showName")])])}"
}
将生成的代码展开:
with (this) {return \_c('div', [
message ? \_c('h2', [_v(_s(message))]) : \_e(),
\_v(' '),
\_c('button', { on: { click: showName } }, [_v('showName')]),
])
}
看到这里一堆的下划线肯定很懵逼,这里的 _c 对应的是虚拟 DOM 中的 createElement 方法。其他的下划线方法在 core/instance/render-helpers 中都有定义,每个方法具体做了什么不做展开。

<center>render-helpers</center>
具体转化方法就是一些简单的字符拼接,下面是简化了逻辑的部分,不做过多讲述。
export function generate(ast, options) {const state = new CodegenState(options)
const code = ast ? genElement(ast, state) : '_c("div")'
return {
render: `with(this){return ${code}}`,
staticRenderFns: state.staticRenderFns,
}
}
export function genElement(el, state) {
let code
const data = genData(el, state)
const children = genChildren(el, state, true)
code = `_c('${el.tag}'${
data ? `,${data}` : '' // data
}${
children ? `,${children}` : '' // children
})`
return code
}
总结
理清了 Vue 模板编译的整个过程,重点都放在了解析 HTML 生成 AST 的部分。本文只是大致讲述了主要流程,其中省略了特别多的细节,比如:对 template/slot 的处理、指令的处理等等,如果想了解其中的细节可以直接阅读源码。希望大家在阅读这篇文章后有所收获。
以上是 【JS】【转】vue模板编译原理 的全部内容, 来源链接: utcz.com/a/91039.html