【Python】为什么通过urllib获取Response数据与在浏览器开发工具中看到的不一致?
python模拟浏览器发送请求,自动获取信息,但是使用urllib模块获取的信息与在浏览器开发工具中的不一致
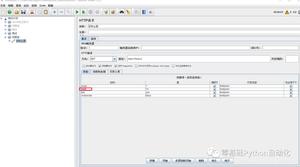
访问信息:



具体代码:
from urllib import request, parsereq = request.Request(
'http://bpm.tinno.com/project/list_Materials.action?userId=613689,614904,613697')
req.add_header(
'Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8')
req.add_header(
'Cookie', 'bpm_ident=-wM0Y383RviJI04BfBiznQ; JSESSIONID=09BE59A85DD61AAA981011B302824320; LoginFlag=618190')
req.add_header('Referer', 'http://bpm.tinno.com/')
req.add_header(
'User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML:like Gecko) Chrome/50.0.2661.102 Safari/537.36')
req.add_header('X-Requested-With', 'XMLHttpRequest')
data = parse.urlencode(
{'start': '',
'limit': 5,
'NewMaterialNo': 'G08-MT6515-001',
'MaterialAtt': '',
'MaterialAtt2': '',
'MaterialType1': '',
'MaterialType': '',
'OPType': '',
'suppliernamedid': '',
'suppliername': '',
'StandardText': '',
'MaterialDescribe': '',
'functionDes': ''})
data = data.encode('ascii')
with request.urlopen(req, data) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print(f.read().decode('utf-8'))
代码运行结果:
Status: 200 OKServer: Apache-Coyote/1.1
Content-Type: application/json;charset=UTF-8
Content-Length: 16
Date: Sat, 24 Dec 2016 07:19:43 GMT
Connection: close
{"success":true}
[Finished in 0.2s]
但是在浏览器开发工具中:
![]()
代码运行结果只有数据:{"success":true},后面的一大串数据为什么没有呢?
回答
start: 0 和 start: ''
请问一下 我这里有个B站用户空间数据的爬虫 可是每次都超时了 博主能帮我搞定下么。?
脚本返回结果包含 Response Headers 的一部分内容,而Response Headers的信息位于Headers标签里。

以上是 【Python】为什么通过urllib获取Response数据与在浏览器开发工具中看到的不一致? 的全部内容, 来源链接: utcz.com/a/78547.html