Defining Python Source Code Encodings
Defining the Encoding
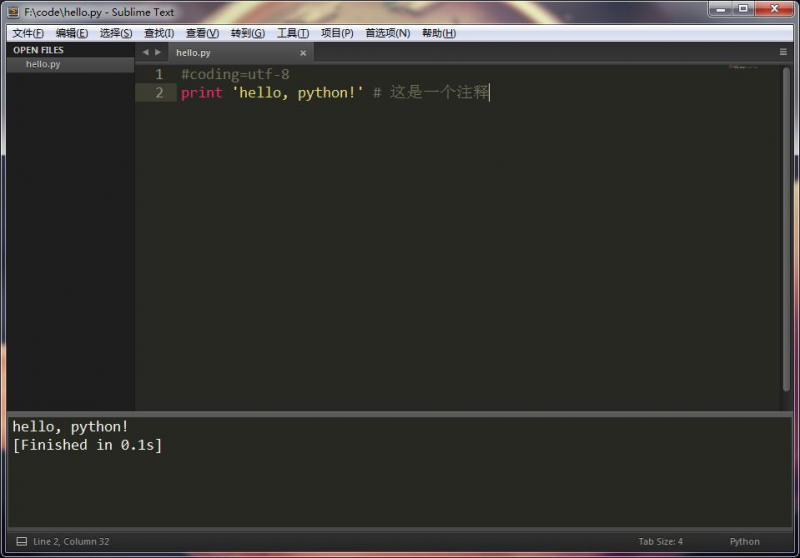
Python will default to ASCII as standard encoding if no other encoding hints are given.
To define a source code encoding, a magic comment must be placed into the source files either as first or second line in the file, such as:
# coding=<encoding name>
or (using formats recognized by popular editors):
#!/usr/bin/python
# -*- coding: <encoding name> -*-
or:
#!/usr/bin/python
# vim: set fileencoding=<encoding name> :
More precisely, the first or second line must match the following regular expression:
^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
The first group of this expression is then interpreted as encoding name. If the encoding is unknown to Python, an error is raised during compilation. There must not be any Python statement on the line that contains the encoding declaration. If the first line
matches the second line is ignored.
To aid with platforms such as Windows, which add Unicode BOM marks to the beginning of Unicode files, the UTF-8 signature \xef\xbb\xbf will be interpreted as 'utf-8' encoding as well (even if no magic encoding comment is given).
If a source file uses both the UTF-8 BOM mark signature and a magic encoding comment, the only allowed encoding for the comment is 'utf-8'. Any other encoding will cause an error.
详情请查阅:
https://www.python.org/dev/peps/pep-0263/
以上是 Defining Python Source Code Encodings 的全部内容, 来源链接: utcz.com/a/52887.html