消息型web框架之RabbashMQhdfs
在上一篇博客中我们简单的介绍了下rabbitmq安装配置相关指令的说明以及rabbitmqctl的相关子命令的说明;回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13561245.html;今天我们来聊一聊rabbitmq集群;之所以要用集群是因为在一个分布式应用环境中,rabbitmq的作用是连接各组件,一旦rabbitmq服务挂掉,可能影响整个线上业务,为了避免这样的问题发生,我们就必须想办法对rabbitmq做高可用,能够让集群中的每个rabbitmq节点把自身接收到的消息通过网络同步到其他节点,这样一来使得每个节点都有整个rabbitmq集群的所有消息,即便其中一台rabbitmq宕机不影响消息丢失的情况;rabbitmq集群它的主要作用就是各节点互相同步消息,从而实现了数据的冗余;除了rabbitmq的数据冗余,我们还需要考虑,一旦后端有多台rabbitmq我们就需要通过对后端多台rabbitmq-server做负载均衡,使得每个节点能够分担一部分流量,同时对客户端访问提供一个统一的访问接口;客户端就可以基于负载均衡的地址来请求rabbitmq,通过负载均衡调度,把客户端的请求分摊到后端多个rabbitmq上;如果某一台rabbitmq宕机了,根据负载均衡的健康状态监测,自动将请求不调度到宕机的rabbitmq-server上,从而也实现了对rabbitmq高可用;
在实现rabbitmq集群前我们需要做以下准备
1、更改各节点的主机名同hosts文件解析的主机名相同,必须保证各节点主机名称不一样,并且可以通过hosts文件解析出来;
2、时间同步,时间同步对于一个集群来讲是最基本的要求;
3、各节点的cookie信息必须保持一致;
实验环境说明
| 节点名 | 主机名 | ip地址 |
| node01 | node01 | 192.168.0.41 |
| node2 | node2 | 192.168.0.42 |
| 负载均衡 | node3 | 192.168.0.43 |
1、配置各节点的主机名称
[root@node01 ~]# hostnamectl set-hostname node01[root@node01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.41 node01
192.168.0.42 node2
192.168.0.43 node3
[root@node01 ~]# scp /etc/hosts node2:/etc/
hosts 100% 218 116.4KB/s 00:00
[root@node01 ~]# scp /etc/hosts node3:/etc/
hosts 100% 218 119.2KB/s 00:00
[root@node01 ~]#
提示:对于rabbitmq集群来讲就只有node01和node2,这两个节点互相同步消息;而负载均衡是为了做流量负载而设定的,本质上不属于rabbitmq集群;所以对于负载均衡的主机名是什么都可以;
验证:链接个节点验证主机名是否正确,以及hosts文件
[root@node2 ~]# hostnamenode2
[root@node2 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.41 node01
192.168.0.42 node2
192.168.0.43 node3
[root@node2 ~]#
在各节点安装rabbitmq-server
yum install rabbitmq-server -y
启动各节点rabbitmq-server
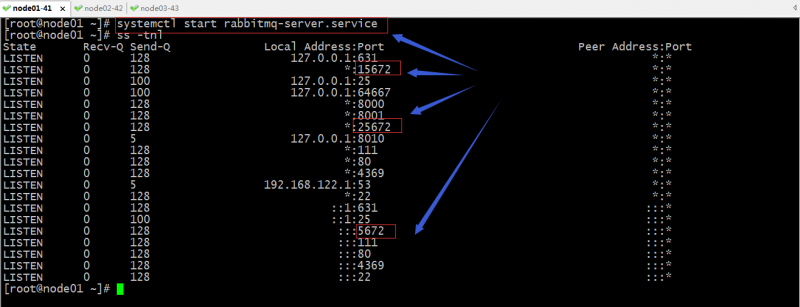
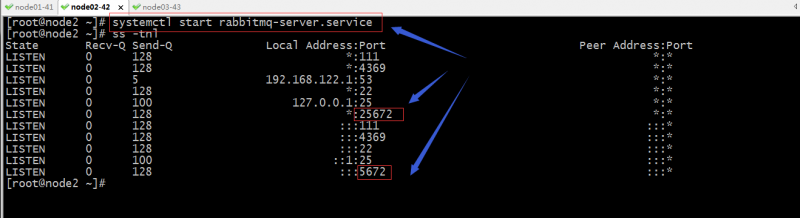
提示:node01上启动了rabbitmq-management插件,所以15672处于监听;而node2没有启动rabbitmq-management插件,15672端口并没有处于监听状体;对于一个rabbitmq集群,25672这个端口就是专用于集群个节点通信;
现在基本环境已经准备好,现在我们就可以来配置集群了,rabbitmq集群的配置非常简单,默认情况启动一个rabbitmq,它就是一个集群,所以25672处于监听状态嘛,只不过集群中就只有一个自身节点;
验证:各节点集群状态信息,节点名是否同主机hostname名称相同


提示:从上面的信息可以看到两个节点的集群名称都是同host主机名相同;
停止node2上的应用,把node2加入node01集群
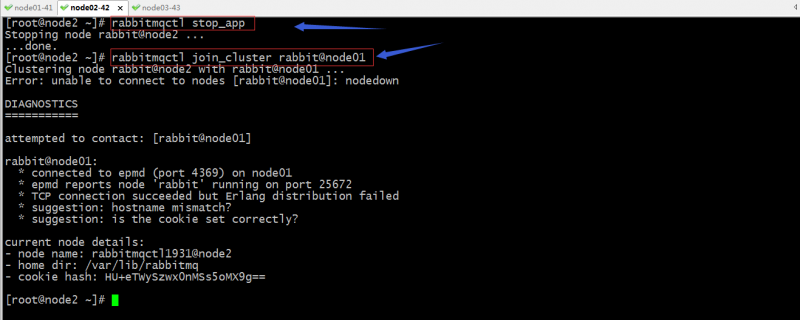
提示:这里提示我们无法连接到rabbit@node01,出现以上错误的主要原因有两个,第一个是主机名称解析不正确;第二是cookie不一致;
复制cookie信息
[root@node2 ~]# scp /var/lib/rabbitmq/.erlang.cookie node01:/var/lib/rabbitmq/The authenticity of host 'node01 (192.168.0.41)' can't be established.
ECDSA key fingerprint is SHA256:EG9nua4JJuUeofheXlgQeL9hX5H53JynOqf2vf53mII.
ECDSA key fingerprint is MD5:57:83:e6:46:2c:4b:bb:33:13:56:17:f7:fd:76:71:cc.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node01,192.168.0.41' (ECDSA) to the list of known hosts.
.erlang.cookie 100% 20 10.6KB/s 00:00
[root@node2 ~]#
验证:md5sum验证各节点cookie是否一致
[root@node2 ~]# md5sum /var/lib/rabbitmq/.erlang.cookie1d4f9e4d6c92cf0c749cc4ace68317f6 /var/lib/rabbitmq/.erlang.cookie
[root@node2 ~]# ssh node01
Last login: Wed Aug 26 19:41:30 2020 from 192.168.0.232
[root@node01 ~]# md5sum /var/lib/rabbitmq/.erlang.cookie
1d4f9e4d6c92cf0c749cc4ace68317f6 /var/lib/rabbitmq/.erlang.cookie
[root@node01 ~]#
提示:现在两个节点的cookie信息一致了,再次把node2加入到node01上看看是否能够加入?
[root@node2 ~]# rabbitmqctl join_cluster rabbit@node01Clustering node rabbit@node2 with rabbit@node01 ...
Error: unable to connect to nodes [rabbit@node01]: nodedown
DIAGNOSTICS
===========
attempted to contact: [rabbit@node01]
rabbit@node01:
* connected to epmd (port 4369) on node01
* epmd reports node 'rabbit' running on port 25672
* TCP connection succeeded but Erlang distribution failed
* suggestion: hostname mismatch?
* suggestion: is the cookie set correctly?
current node details:
- node name: rabbitmqctl2523@node2
- home dir: /var/lib/rabbitmq
- cookie hash: HU+eTWySzwx0nMSs5oMX9g==
[root@node2 ~]#
提示:还是提示我们加不进去,这里的原因是我们更新了node01的cookie信息,没有重启rabbitmq-server,所以它默认还是以前的cookie;
重启node01上的rabbitmq-server
[root@node01 ~]# systemctl restart rabbitmq-server.service[root@node01 ~]# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:631 *:*
LISTEN 0 128 *:15672 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 100 127.0.0.1:64667 *:*
LISTEN 0 128 *:8000 *:*
LISTEN 0 128 *:8001 *:*
LISTEN 0 128 *:25672 *:*
LISTEN 0 5 127.0.0.1:8010 *:*
LISTEN 0 128 *:111 *:*
LISTEN 0 128 *:80 *:*
LISTEN 0 128 *:4369 *:*
LISTEN 0 5 192.168.122.1:53 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 ::1:631 :::*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 128 :::5672 :::*
LISTEN 0 128 :::111 :::*
LISTEN 0 128 :::80 :::*
LISTEN 0 128 :::4369 :::*
LISTEN 0 128 :::22 :::*
[root@node01 ~]#
提示:如果是把node01的cookie复制给node2,我们需要重启node2,总之拿到新cookie节点都要重启,保证在用cookie的信息一致就可以了;
再次把node2加入到node01
[root@node2 ~]# rabbitmqctl join_cluster rabbit@node01Clustering node rabbit@node2 with rabbit@node01 ...
...done.
[root@node2 ~]#
提示:加入对应节点集群没有报错就表示加入集群成功;
验证:查看各节点的集群状态信息


提示:在两个节点上我们都可以看到两个节点;到此node2就加入到node01这个集群中了;但是两个节点的集群状态信息不一样,原因是node2上没有启动应用,启动应用以后,它俩的状态信息就会是一样;
启动node2上的应用
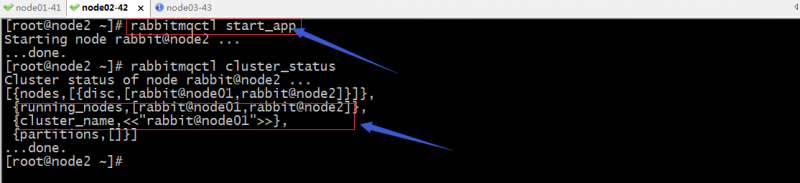

提示:此时两个节点的状态信息就一样了;到此rabbitmq集群就搭建好了;
验证:在浏览器登录node1的15672,看看web管理界面是否有节点信息?

提示:node2之所以没有统计信息是因为node2上没有启动rabbitmq-management插件;启用插件就可以统计到数据;
rabbitmqctl集群相关子命令
join_cluster <clusternode> [--ram]:加入指定节点集群;
cluster_status:查看集群状态
change_cluster_node_type disc | ram:更改节点存储类型,disc表示磁盘,ram表示内存;一个集群中必须有一个节点为disc类型;
[root@node2 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]},
{running_nodes,[rabbit@node01,rabbit@node2]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node2 ~]# rabbitmqctl change_cluster_node_type ram
Turning rabbit@node2 into a ram node ...
Error: mnesia_unexpectedly_running
[root@node2 ~]#
提示:这里提示我们mnesia_unexpectedly_running,所以我们更改不了节点类型;解决办法是停止node2上的应用,然后在更改类型,在启动应用即可;
[root@node2 ~]# rabbitmqctl stop_appStopping node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]}]
...done.
[root@node2 ~]# rabbitmqctl change_cluster_node_type ram
Turning rabbit@node2 into a ram node ...
...done.
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01]},{ram,[rabbit@node2]}]},
{running_nodes,[rabbit@node01,rabbit@node2]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node2 ~]#
提示:可以看到node2就变成了ram类型了;
[root@node01 ~]# rabbitmqctl change_cluster_node_type ramTurning rabbit@node01 into a ram node ...
Error: mnesia_unexpectedly_running
[root@node01 ~]# rabbitmqctl stop_app
Stopping node rabbit@node01 ...
...done.
[root@node01 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01]},{ram,[rabbit@node2]}]}]
...done.
[root@node01 ~]# rabbitmqctl change_cluster_node_type ram
Turning rabbit@node01 into a ram node ...
Error: {resetting_only_disc_node,"You cannot reset a node when it is the only disc node in a cluster. Please convert another node of the cluster to a disc node first."}
[root@node01 ~]#
提示:这里需要注意一个集群中至少保持一个节点是disc类型;所以node2更改成ram类型,node01就必须是disc类型;
forget_cluster_node [--offline]:离开集群;
[root@node01 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01]},{ram,[rabbit@node2]}]},
{running_nodes,[rabbit@node2,rabbit@node01]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node01 ~]# rabbitmqctl forget_cluster_node rabbit@node2
Removing node rabbit@node2 from cluster ...
Error: {failed_to_remove_node,rabbit@node2,
{active,"Mnesia is running",rabbit@node2}}
[root@node01 ~]#
提示:我们在node01上移除node2,提示我们node2节点处于活跃状态不能移除;这也告诉我们这个子命令只能移除不在线的节点;
下线node2上的应用
[root@node2 ~]# rabbitmqctl stop_appStopping node rabbit@node2 ...
...done.
[root@node2 ~]#
再次移除node2
[root@node01 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01]},{ram,[rabbit@node2]}]},
{running_nodes,[rabbit@node01]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node01 ~]# rabbitmqctl forget_cluster_node rabbit@node2
Removing node rabbit@node2 from cluster ...
...done.
[root@node01 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01]}]},
{running_nodes,[rabbit@node01]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node01 ~]#
update_cluster_nodes clusternode:更新集群节点信息;
把node2加入node01这个集群
[root@node2 ~]# rabbitmqctl stop_appStopping node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl join_cluster rabbit@node01
Clustering node rabbit@node2 with rabbit@node01 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]}]
...done.
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]},
{running_nodes,[rabbit@node01,rabbit@node2]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node2 ~]#
停掉node2上的应用
[root@node2 ~]# rabbitmqctl stop_appStopping node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]}]
...done.
[root@node2 ~]#
提示:如果此时有新节点加入集群,如果在把node01上的应用停掉,node2再次启动应用就会提示错误;如下
把node3加入node01
[root@node3 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node3]}]},
{running_nodes,[rabbit@node3]},
{cluster_name,<<"rabbit@node3">>},
{partitions,[]}]
...done.
[root@node3 ~]# rabbitmqctl stop_app
Stopping node rabbit@node3 ...
...done.
[root@node3 ~]# rabbitmqctl join_cluster rabbit@node01
Clustering node rabbit@node3 with rabbit@node01 ...
...done.
[root@node3 ~]# rabbitmqctl start_app
Starting node rabbit@node3 ...
...done.
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node01,rabbit@node3]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node3 ~]#
停掉node01上的应用
[root@node01 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node3,rabbit@node01]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node01 ~]# rabbitmqctl stop_app
Stopping node rabbit@node01 ...
...done.
[root@node01 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node01 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]}]
...done.
[root@node01 ~]#
启动node2上的应用
[root@node2 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2]}]}]
...done.
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbit@node2 ...
BOOT FAILED
===========
Error description:
{could_not_start,rabbit,
{bad_return,
{{rabbit,start,[normal,[]]},
{'EXIT',
{rabbit,failure_during_boot,
{error,
{timeout_waiting_for_tables,
[rabbit_user,rabbit_user_permission,rabbit_vhost,
rabbit_durable_route,rabbit_durable_exchange,
rabbit_runtime_parameters,
rabbit_durable_queue]}}}}}}}
Log files (may contain more information):
/var/log/rabbitmq/rabbit@node2.log
/var/log/rabbitmq/rabbit@node2-sasl.log
Error: {rabbit,failure_during_boot,
{could_not_start,rabbit,
{bad_return,
{{rabbit,start,[normal,[]]},
{'EXIT',
{rabbit,failure_during_boot,
{error,
{timeout_waiting_for_tables,
[rabbit_user,rabbit_user_permission,
rabbit_vhost,rabbit_durable_route,
rabbit_durable_exchange,
rabbit_runtime_parameters,
rabbit_durable_queue]}}}}}}}}
[root@node2 ~]#
提示:此时node2就启动不起来了,这时我们就需要用到update_cluster_nodes子命令向node3更新集群信息,然后再次在node2上启动应用就不会报错了;
向node3询问更新集群节点信息,并启动node2上的应用
[root@node2 ~]# rabbitmqctl update_cluster_nodes rabbit@node3Updating cluster nodes for rabbit@node2 from rabbit@node3 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]}]
...done.
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbit@node2 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node3,rabbit@node2]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node2 ~]#
提示:可以看到更新了集群节点信息后,在node2上查看集群状态信息就可以看到node3了;此时在启动node2上的应用就没有任何问题;
sync_queue queue:同步指定队列;
cancel_sync_queue queue:取消指定队列同步
set_cluster_name name:设置集群名称
[root@node2 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node01,rabbit@node3,rabbit@node2]},
{cluster_name,<<"rabbit@node01">>},
{partitions,[]}]
...done.
[root@node2 ~]# rabbitmqctl set_cluster_name rabbit@rabbit_node02
Setting cluster name to rabbit@rabbit_node02 ...
...done.
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node01,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node01,rabbit@node3,rabbit@node2]},
{cluster_name,<<"rabbit@rabbit_node02">>},
{partitions,[]}]
...done.
[root@node2 ~]#
提示:在集群任意一个节点更改名称都会同步到其他节点;也就是说集群状态信息在每个节点都是保持一致的;
基于haproxy负载均衡rabbitmq集群
1、安装haproxy
[root@node3 ~]# yum install -y haproxyLoaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Resolving Dependencies
--> Running transaction check
---> Package haproxy.x86_64 0:1.5.18-9.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
====================================================================================================
Package Arch Version Repository Size
====================================================================================================
Installing:
haproxy x86_64 1.5.18-9.el7 base 834 k
Transaction Summary
====================================================================================================
Install 1 Package
Total download size: 834 k
Installed size: 2.6 M
Downloading packages:
haproxy-1.5.18-9.el7.x86_64.rpm | 834 kB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : haproxy-1.5.18-9.el7.x86_64 1/1
Verifying : haproxy-1.5.18-9.el7.x86_64 1/1
Installed:
haproxy.x86_64 0:1.5.18-9.el7
Complete!
[root@node3 ~]#
提示:haproxy可以重新找个主机部署,也可以在集群中的某台节点上部署;建议重新找个主机部署,这样可避免端口冲突;
配置haproxy
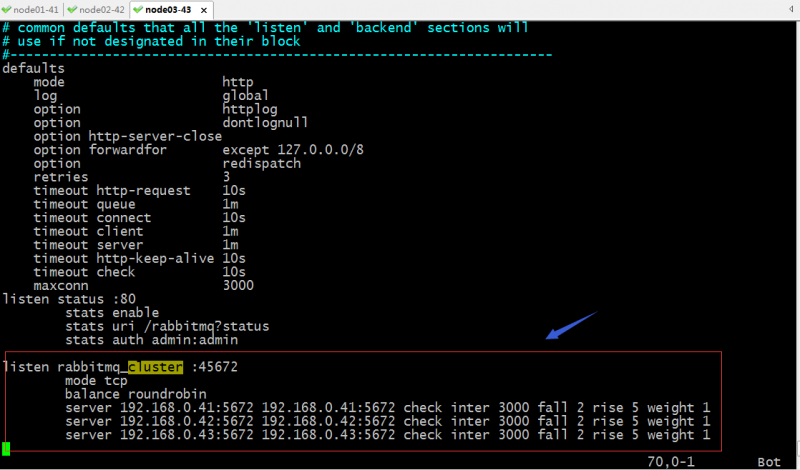
提示:以上就是haproxy负载均衡rabbitmq集群的示例,我们通过使用haproxy的tcp模式去代理rabbitmq,并且使用轮询的算法把请求调度到后端server上;
验证:启动haproxy,看看对应的端口是否处于监听状态,状态页面是否能够正常检测到后端server是否在线?
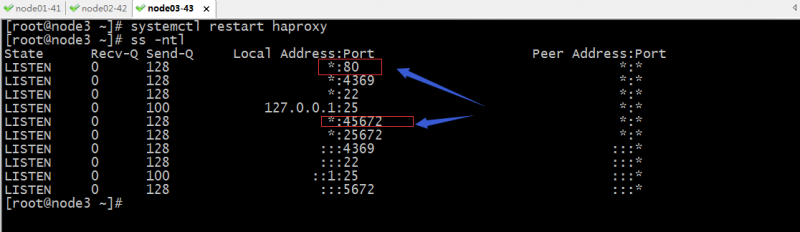
提示:此时负载均衡就搭建好了,后续使用这个集群,我们就可以把这个负载均衡上监听的地址给用户访问即可;这里要考虑一点haproxy是新的单点;
在浏览器打开haproxy的状态页看看后端server是否在线?
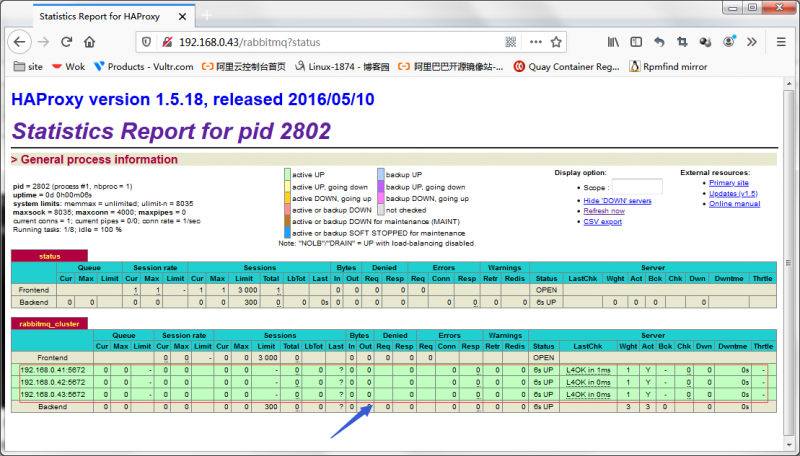
提示:可以看到后端3台rabbitmq-server都是正常在线;
停止node3上的rabbitmq,看看haproxy是否能够及时发现node3不再线,并把它标记为down?

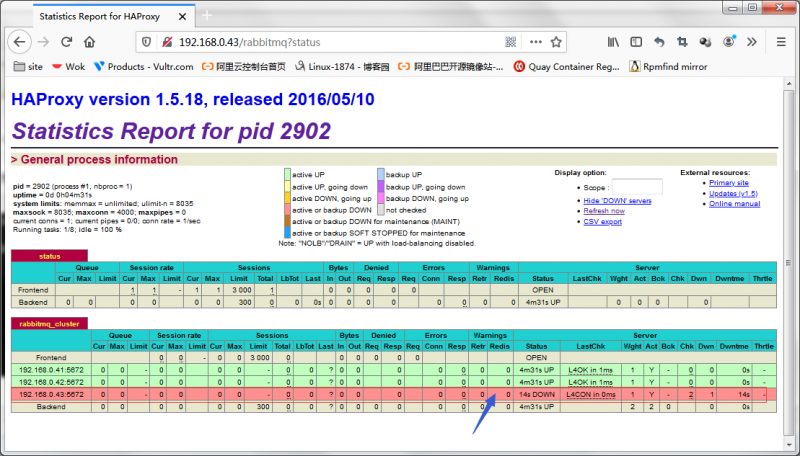
提示:我们根据haproxy对后端server做健康状态检查来实现rabbitmq集群的故障转移,所以对于rabbitmq集群来讲,它只复制消息的同步,实现数据冗余,真正高可用还是要靠前端的调度器实现;对于nginx负载均衡rabbitmq可以参考ngixn对tcp协议的代理来写配置;有关nginx负载均衡tcp应用相关话题,可以参考本人博客https://www.cnblogs.com/qiuhom-1874/p/12468946.html我这里就不过多阐述;
以上是 消息型web框架之RabbashMQhdfs 的全部内容, 来源链接: utcz.com/a/50302.html