金九银十冲刺大厂,你需要知道的性能优化和手写源码
写在开头
- 今天这些只是基础知识,面试时候如果面试很高级的岗位,只靠背面试题是很容易被识破,建议大家只是作为一个学习的点,不断去深入、实践在项目中。有一些同学说前端很难,很多东西,学不完,我想你可能是走错了方向,毕竟人不是万能,不要太深入那些对你目前来说没有意义的东西,如果你有对现状不是很满意,可以在下面评论留言,我可以给你一些学习建议.
- 我的手写源码教程集合提供给大家学习,地址是:仓库地址,希望大家给个
star~

正式开始
- 本文为上篇-纯前端,不涉及
Node.js、Electron、React-native、Linux、Docker、数据库、redis、消息队列和操作系统等知识.根据经验,看上篇的人最多,因为毕竟这部分的前端占比大。有一定技术基础的,可以看看后面文章。
如何让display出现“动画”
- 初始化
APP,display为"none"
<!DOCTYPE html><html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
#app {
width: 200px;
height: 200px;
background-color: red;
display: none;
transition: all 1s;
}
</style>
</head>
<body>
<div id="app">
</div>
<button id="test">测试</button>
</body>
</html>
- 初始化界面:

- 此时我将app的display初始化为
none,并且写入脚本文件
<style>#app {
width: 200px;
height: 200px;
background-color: red;
display: none;
}
</style>
。。。
<script>
test.onclick = function () {
const app = document.querySelector('#app')
console.log(app, 'app')
app.style.transform = "translateX(200px)"
app.style.display = "block"
}
</script>
- 初始化界面变成了这样:

- 此时,我点击测试按钮

- 并没有出现动画,非常生硬的出来了,有一些场景我又要性能,比如初始化不渲染,但是当它出现又要有动画的时候,就有可能使用这行代码
test.onclick = function () {const app = document.querySelector('#app')
console.log(app, 'app')
app.style.display = "block"
const height = app.offsetHeight
app.style.transform = "translateX(200px)"
}
- 当我加入
const height = app.offsetHeight这行代码的时候,再点击测试按钮,display切换就顺带出来了“动画”,有了过度效果 - 为什么会出现动画了呢? 因为我读取
dom的这些特殊属性时,浏览器就会强制清空渲染队列一次,让我拿到最新的值。也就是说读取的时候,其实已经是display为"block"了,因此。我们出现了过渡动画

- 完整代码
<!DOCTYPE html><html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
#app {
width: 200px;
height: 200px;
background-color: red;
display: none;
transition: all 1s;
}
</style>
</head>
<body>
<div id="app">
</div>
<button id="test">测试</button>
</body>
<script>
test.onclick = function () {
const app = document.querySelector('#app')
console.log(app, 'app')
app.style.display = "block"
const height = app.offsetHeight
app.style.transform = "translateX(200px)"
}
</script>
</html>
- 要注意的一点是,除了手动读取特殊属性清空浏览器渲染队列外,浏览器也会有自己的一个队列阀值,当达到后,会自动清空。这就是为什么在一个for循环里面多次操作DOM,但是它不会真的渲染那么多次的原因,因为浏览器帮我们维护了一个队列,择机渲染。
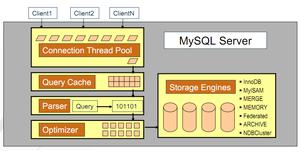
前端出现性能问题可能有哪些层面的原因?
答:
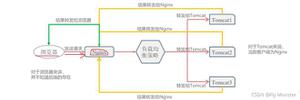
- 网络传输层面
- 前端渲染机制层面
js代码执行层面的- 部署层面
- 产品设计层面
- 前端缓存机制层面
- 功能实现方式层面
- 等...
- 逐个击破:
- 网络传输层面:对于这块,应该跟前端缓存机制层面的问题一起解决,我们看掘金的代码分割:

- 不需要看掘金的工程化环境配置,我就大概知道他们配置是怎样的。
webpack/或其他工具打包,精细化分割了代码。将node_modules(vendor开头)和自己写的src(default开头)源码分开打包了.这样最小的限度的缩小了hash值改变带来的http缓存失效问题.在webpack中配置splitChunks.
splitChunks: {
// 表示选择哪些 chunks 进行分割,可选值有:async,initial和all
chunks: "async",
// 表示新分离出的chunk必须大于等于minSize,默认为30000,约30kb。
minSize: 30000,
// 表示一个模块至少应被minChunks个chunk所包含才能分割。默认为1。
minChunks: 1,
// 表示按需加载文件时,并行请求的最大数目。默认为5。
maxAsyncRequests: 5,
// 表示加载入口文件时,并行请求的最大数目。默认为3。
maxInitialRequests: 3,
// 表示拆分出的chunk的名称连接符。默认为~。如chunk~vendors.js
automaticNameDelimiter: '~',
// 设置chunk的文件名。默认为true。当为true时,splitChunks基于chunk和cacheGroups的key自动命名。
name: true,
// cacheGroups 下可以可以配置多个组,每个组根据test设置条件,符合test条件的模块,就分配到该组。模块可以被多个组引用,但最终会根据priority来决定打包到哪个组中。默认将所有来自 node_modules目录的模块打包至vendors组,将两个以上的chunk所共享的模块打包至default组。
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
//
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
- 有人会疑问,为什么会把这个问题,放在第一个?因为这是抛砖引玉,很多性能问题来源于此,小项目感知很小,但是对于一个百万行,千万行级别的巨无霸项目,提升就会非常大,这都是我实践过的。(首屏性能可能会因为精细化分割代码提升十倍,我强烈推荐大家使用精细化分割手段)
- 代码分割完了,把依赖拆解开了,但是一个组件代码有一万多行,传输的
js文件还是有几MB大小,这个问题能忽略吗?当然不可以。我们一般生产环境部署时候,会借助CDN,在各种云厂商提供/自己搭建的CDN服务配置相应的解析。掘金现在已由头条系接手,我看静态资源方案的域名开头使用的是s3.pstatp.com,我查询大概是跟抖音/相关的域名。或许是自己搭建的CDN服务(千万不要忽略CDN,静态资源服务对于服务器来说是非常占带宽的,速度和体验肯定会比CDN差很多,越大越重的系统提升越大) 网络传输层面, 仅仅是静态资源吗?
- 还有前端发送
ajax请求 - 对于一些比较大的数据,例如表格、列表,我们如果一次性拉取数据,那么就可能后端需要查询很长时间数据库、传输也需要很长时间,如果又是弱网,那就要可能用户点击一下,就要等上好几秒甚至十几秒才能拿到数据继续操作(前不久刚设计了一套混合
APP改造方案,弱网/无网络情况拥有正常的体验,觉得分块传输就是核心,特别在APP端)
- 还有前端发送
对于
ws/wss协议、TCP等私有协议双工通信的- 心跳检测、发送队列持久化是必要的,手机端经常出现网络切换、弱网情况,那就避免不了心跳检测保活,我们可以参考一种监控实现手段,他们为了避免监控数据的重复上传,后端通过统一
hash算法和接收到的错误上报,生成对应的后缀空文件,发布到CDN。这样前端每次上报时候,都会用统一hash算法生成对应后缀,请求那个地址,如果存在,就说明后端已经接受到了这个上报,可以丢弃这个上报。同理,我们可以参考这个,可以用空的CDN文件做网络检测质量检测(因为一些跨平台APP框架无法精确获取当前网络质量),然后再将发送请求队列持久化即可保证请求不丢失。(对于IM场景的APP,那就要考虑更多,这里不对IM展开讲)
- 心跳检测、发送队列持久化是必要的,手机端经常出现网络切换、弱网情况,那就避免不了心跳检测保活,我们可以参考一种监控实现手段,他们为了避免监控数据的重复上传,后端通过统一
Js代码执行层面的,先看一段代码:
// 真奥义之阻塞JS主线程之休眠const sleep = (delay = 500) => {
let t = Date.now();
while(Date.now() - t <= delay) {
continue;
}
};
- 上面这段代码,会阻塞
JS主解析线程,默认是500ms,这意味着,这500ms,用户操作我们的系统,是不会有任何相应的,因为此时JS主解析线程一直被阻塞。(如果是10秒,那么会怎样?如果把这段代码换成其他计算的函数/循环,效果也是一样)。这就是因为JS代码导致的性能问题,如何解决?当然是分片分片分片!不要写太耗时的JS同步代码. - 这里又会有人说 用
web worker wasm PWA等技术可以解决一些问题啊.但是我劝你在技术选型的时候,要考虑一个复杂度和收益的问题。现在还是有人用JQ和原生JS、Canvas开发项目,因为开发最复杂的功能,往往都需要他们。(例如富文本编辑器、可视化编辑等) - 对于纯粹计算占用耗时的,可以考虑
web worker技术,使用事件通信,将大量计算工作交给web worker。Worker 也可以创建新的 Worker,当然,所有 Worker 必须与其创建者同源(注意:Blink暂时不支持嵌套 Worker)。
var myWorker = new Worker('worker.js');var first = document.querySelector('#number1');
var second = document.querySelector('#number2');
first.onchange = function() {
myWorker.postMessage([first.value,second.value]);
console.log('Message posted to worker');
}
web worker兼容性很好,如果是webpack环境,需要对应做一些工程化环境处理,web worker在我看来,适用于纯粹的大量计算场景。我记得有团队是用于3D数据可视化处理的,他们使用web worker后提升就很大
webAssembly技术,更适用于音视频领域,更底层的功能处理,例如浏览器端要音视频编解码或者图片压缩处理之类就很适合用它.它有点像浏览器版的Node.js的c++插件。Node.js可以调用C# Go Object-c等语言的插件&通信,同理,webAssembly也是可以用各种语言编写。关于webAssembly这个技术,我写过一篇文章方便大家入门。
self.importScripts('ffmpeg.js');onmessage = function(e) {
console.log('ffmpeg_run', ffmpeg_run);
var files = e.data;
console.log(files);
ffmpeg_run({
arguments: ['-i', '/input/' + files[0].name, '-b:v', '64k', '-bufsize', '64k', '-vf', 'showinfo', '-strict', '-2', 'out.mp4'],
files: files,
}, function(results) {
console.log('result',results);
self.postMessage(results[0].data, [results[0].data]);
});
}
- 这里讲到了这些技术,不得不提到
V8,由于它是自动垃圾回收机制,那么有一可能下一次回收的内存垃圾达到500MB,这个时候就会产生卡顿,有人会莫名其妙,为什么会卡?因为v8垃圾回收也会阻塞主解析线程,所以造成了让你卡的假象.
渲染层面的性能问题:
- 频繁触发的更新,可以合并为一帧更新,异步调度处理渲染任务
function defer(fn) {
//requestIdleCallback的兼容性不好,对于用户交互频繁多次合并更新来说,requestAnimation更有及时性高优先级,requestIdleCallback则适合处理可以延迟渲染的任务~
// if (window.requestIdleCallback) {
// return requestIdleCallback(fn);
// }
//高优先级任务 异步的 先挂起
return requestAnimationFrame(fn);
}
export function enqueueSetState(stateChange, component) {
//第一次进来肯定会先调用defer函数
if (setStateQueue.length === 0) {
//清空队列的办法是异步执行
defer(flush);
}
//向队列中添加对象 key:stateChange value:component
setStateQueue.push({
stateChange,
component
});
//如果渲染队列中没有这个组件 那么添加进去
if (!renderQueue.some(item => item === component)) {
renderQueue.push(component);
}
}
- 对于首屏渲染压力比较大的,可以采取webpack的代码分割&懒加载js文件

- 以及图片懒加载,下拉加载更多等手段处理

- 对于一次性渲染压力比较大而且不分页的,可以考虑使用虚拟列表,像原生APP一样,只渲染可视区域,但是给用户无感知的滚动体验。
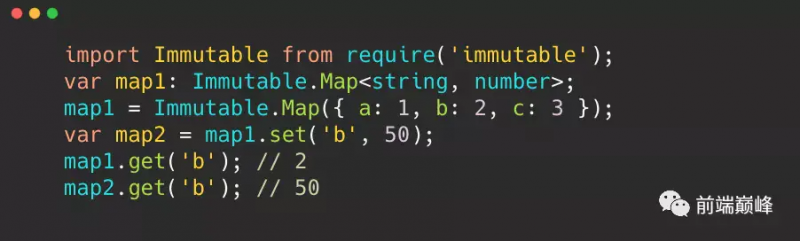
- 对于说很大的超复杂项目,使用可变数据,导致内存使用一直非常高的情况,可以使用不可变数据,减少内存使用,我是真的使用在项目中,确实优化很大。但是前提你的项目用得上,不然就是增加复杂度(特别注意,对比跟渲染,其实都耗时,不要天真以为用了不可变数据去做对比,然后不重新渲染组件就会提升很大性能)
- 对于一次性渲染压力比较大而且不分页的,可以考虑使用虚拟列表,像原生APP一样,只渲染可视区域,但是给用户无感知的滚动体验。
- 对于对于SEO和首屏要求非常高的,可以考虑做
SSR,SSR有成熟的框架和库,可以考虑用nuxt,next等直接生成静态资源文件
手写Promise核心原理
.then实现链式调用,每次都是返回一个新的Promise,跟JQuery的链式调用相似(返回this)
MyPromise.prototype.then = function (onResolved, onRejected) { // 定义thenconst self = this;
// 指定回调函数的默认值(必须是函数)
onResolved = typeof onResolved==='function' ? onResolved : value => value;
onRejected = typeof onRejected==='function' ? onRejected : reason => {throw reason};
return new MyPromise((resolve,reject)=>{ // 返回一个新的MyPromise对象
function handle(callback) {
// 返回的MyPromise结果由onResolved/onRejected的结果决定
// 1、抛出异常MyPromise结果为失败 reason为结果
// 2、返回的是MyPromise MyPromise为当前的结果
// 3、返回的不是MyPromise value为结果
// 需要通过捕获获取才能知道有没有异常
try{
const result = callback(self.data)
// 判断是不是MyPromise
if ( result instanceof MyPromise){
// 只有then才知道结果
result.then(value=>resolve(value),reason=>reject(reason))
}else{
resolve(result)
}
}catch(error){
reject(error) // 返回的结果为reject(error) 上面第一点
}
}
// 判断当前的status
if (self.status === FULFILLED){ // 状态为 fulfilled
setTimeout(()=>{ // 立即执行异步回调
handle(onResolved);
})
} else if (self.status === REJECTED){ // 状态为 rejected
setTimeout(()=>{ // 立即执行异步回调
handle(onRejected);
})
}else{ // pendding将成功和失败保存到callbacks里缓存起来
self.callbacks.push({
onResolved(value){ //函数里面调用回调函数 并且根据回调函数的结果改变MyPromise的结果
handle(onResolved) //为什么这里没有setTimeout,因为上面已经写到过改变状态后回去callbacks里循环待执行的回调函数
},
onRejected(reason){
handle(onRejected)
}
})
}
})
}
手写redux核心原理
createStore里的实现,根据是否传入了中间件做处理
export default function createStore(reducer, enhancer) {if (typeof enhancer !== 'undefined') {
return enhancer(createStore)(reducer)
}
let state = null
const listeners = []
const subscribe = (listener) => {
listeners.push(listener)
}
const getState = () => state
const dispatch = (action) => {
state = reducer(state, action)
listeners.forEach((listener) => listener())
}
dispatch({})
return { getState, dispatch, subscribe }
}
- 中间件实现,通过
reduce,将上次的结果逐个传入,核心在于compose,支持了多个中间件使用.
import compose from './compose';export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer) => {
const store = createStore(reducer)
let dispatch = store.dispatch
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}
export default function compose(...funcs) {
return funcs.reduce((a, b) => (...args) => a(b(...args)));
}
手写微前端框架原理
- 微前端的模式:
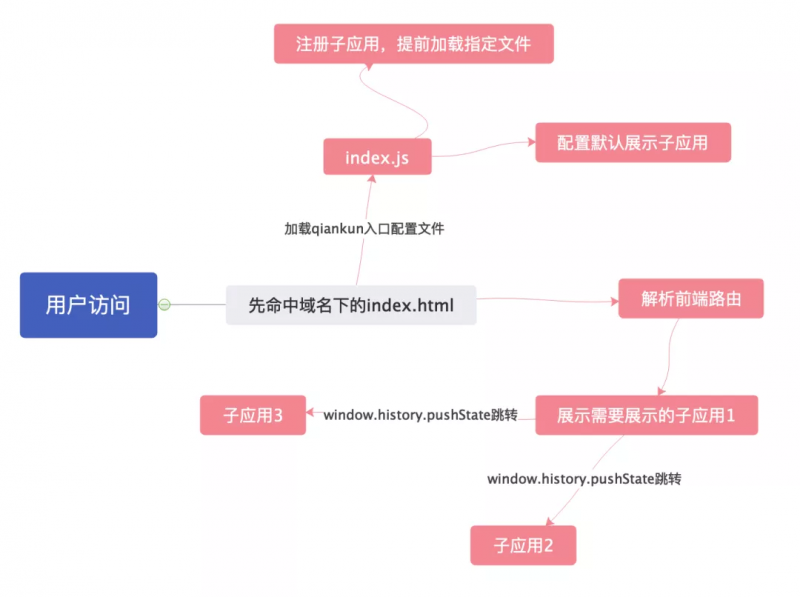
微前端原理:
- 通过fetch请求,通过配置的
entry入口,去对应的地址拉取index.html文件,获取他们所需的资源和所有标签、DOM节点 - 拉取他们的资源全部字符串化.
- 把资源生成对应
DOM节点和标签塞入基座中以及用key-value形式缓存内存中(避免重复发送请求拉取) - 像子应用一样渲染和交互
- 通过fetch请求,通过配置的
- 代码实现:
- 加载子应用
async function loadApp() {const shouldMountApp = Apps.filter(shouldBeActive);
const App = shouldMountApp.pop();
fetch(App.entry)
.then(function (response) {
return response.text();
})
.then(async function (text) {
const dom = document.createElement('div');
dom.innerHTML = text;
const entryPath = App.entry;
const subapp = document.querySelector('#subApp-content');
subapp.appendChild(dom);
handleScripts(entryPath, subapp, dom);
handleStyles(entryPath, subapp, dom);
});
}
- 拉取&生成资源标签等
async function handleScripts(entryPath, subapp, dom) {const scripts = dom.querySelectorAll('script');
const paromiseArr =
scripts &&
Array.from(scripts).map((item) => {
if (item.src) {
const url = window.location.protocol + '//' + window.location.host;
return fetch(`${entryPath}/${item.src}`.replace(url, '')).then(
function (response) {
return response.text();
}
);
} else {
return Promise.resolve(item.textContent);
}
});
const res = await Promise.all(paromiseArr);
if (res && res.length > 0) {
res.forEach((item) => {
const script = document.createElement('script');
script.innerText = item;
subapp.appendChild(script);
});
}
}
手写webpack原理
webpack打包过程
- 1.识别入口文件
- 2.通过逐层识别模块依赖。(Commonjs、amd或者es6的import,webpack都会对其进行分析。来获取代码的依赖)
- 3.webpack做的就是分析代码。转换代码,编译代码,输出代码
- 4.最终形成打包后的代码
webpack打包原理
- 1.先逐级递归识别依赖,构建依赖图谱
- 2.将代码转化成
AST抽象语法树 ,一个AST抽象语法树如下所示:
Node {type: 'File',
start: 0,
end: 32,
loc:
SourceLocation {
start: Position { line: 1, column: 0 },
end: Position { line: 1, column: 32 } },
program:
Node {
type: 'Program',
start: 0,
end: 32,
loc: SourceLocation { start: [Position], end: [Position] },
sourceType: 'module',
interpreter: null,
body: [ [Node] ],
directives: [] },
comments: [] }
- 3.在
AST阶段中去处理代码 - 4.把
AST抽象语法树变成浏览器可以识别的代码, 然后输出
- 核心实现过程
- 将代码转化成AST,并且收集依赖
const fs = require('fs');const path = require('path');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
// traverse 采用的 ES Module 导出,我们通过 requier 引入的话就加个 .default
const babel = require('@babel/core');
const read = fileName => {
const buffer = fs.readFileSync(fileName, 'utf-8');
const AST = parser.parse(buffer, { sourceType: 'module' });
console.log(AST);
// 依赖收集
const dependencies = {};
// 使用 traverse 来遍历 AST
traverse(AST, {
ImportDeclaration({ node }) { // 函数名是 AST 中包含的内容,参数是一些节点,node 表示这些节点下的子内容
const dirname = path.dirname(filename); // 我们从抽象语法树里面拿到的路径是相对路径,然后我们要处理它,在 bundler.js 中才能正确使用
const newDirname = './' + path.join(dirname, node.source.value).replace('\\', '/'); // 将dirname 和 获取到的依赖联合生成绝对路径
dependencies[node.source.value] = newDirname; // 将源路径和新路径以 key-value 的形式存储起来
}
})
// 将抽象语法树转换成浏览器可以运行的代码
const { code } = babel.transformFromAst(AST, null, {
presets: ['@babel/preset-env']
})
return {
filename,
dependencies,
code
}
};
read('./test1.js');
- 绘制依赖图谱
// 创建依赖图谱函数, 递归遍历所有依赖模块const makeDependenciesGraph = (entry) => {
const entryModule = read(entry)
const graghArray = [ entryModule ]; // 首先将我们分析的入口文件结果放入图谱数组中
for (let i = 0; i < graghArray.length; i ++) {
const item = graghArray[i];
const { dependencies } = item; // 拿到当前模块所依赖的模块
if (dependencies) {
for ( let j in dependencies ) { // 通过 for-in 遍历对象
graghArray.push(read(dependencies[j])); // 如果子模块又依赖其它模块,就分析子模块的内容
}
}
}
const gragh = {}; // 将图谱的数组形式转换成对象形式
graghArray.forEach( item => {
gragh[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
console.log(gragh)
return gragh;
}
- 打印
gragh得到的对象:
{ './app.js':{ dependencies: { './test1.js': './test1.js' },
code:
'"use strict";\n\nvar _test = _interopRequireDefault(require("./test1.js"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n\nconsole.log(test
1);' },
'./test1.js':
{ dependencies: { './test2.js': './test2.js' },
code:
'"use strict";\n\nvar _test = _interopRequireDefault(require("./test2.js"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n\nconsole.log(\'th
is is test1.js \', _test["default"]);' },
'./test2.js':
{ dependencies: {},
code:
'"use strict";\n\nObject.defineProperty(exports, "__esModule", {\n value: true\n});\nexports["default"] = void 0;\n\nfunction test2() {\n console.log(\'this is test2 \');\n}\n\nvar _default = tes
t2;\nexports["default"] = _default;' } }
- 获取编译后的代码
const generateCode = (entry) => {// 注意:我们的 gragh 是一个对象,key是我们所有模块的绝对路径,需要通过 JSON.stringify 来转换
const gragh = JSON.stringify(makeDependenciesGraph(entry));
// 我们知道,webpack 是将我们的所有模块放在闭包里面执行的,所以我们写一个自执行的函数
// 注意: 我们生成的代码里面,都是使用的 require 和 exports 来引入导出模块的,而我们的浏览器是不认识的,所以需要构建这样的函数
return `
(function( gragh ) {
function require( module ) {
// 相对路径转换成绝对路径的方法
function localRequire(relativePath) {
return require(gragh[module].dependencies[relativePath])
}
const exports = {};
(function( require, exports, code ) {
eval(code)
})( localRequire, exports, gragh[module].code )
return exports;
}
require('${ entry }')
})(${ gragh })
`;
}
const code = generateCode('./app.js');
console.log(code)
- 得到编译输出的代码
code如下:
(function( gragh ) {function require( module ) {
// 相对路径转换成绝对路径的方法
function localRequire(relativePath) {
return require(gragh[module].dependencies[relativePath])
}
const exports = {};
(function( require, exports, code ) {
eval(code)
})( localRequire, exports, gragh[module].code )
return exports;
}
require('./app.js')
})({"./app.js":{"dependencies":{"./test1.js":"./test1.js"},"code":"\"use strict\";\n\nvar _test = _interopRequireDefault(require(\"./test1.js\"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { \"default\": obj }; }\n\nconsole.log(_test[\"default\"]);"},"./test1.js":{"dependencies":{"./test2.js":"./test2.js"},"code":"\"use strict\";\n\nvar _test = _interopRequireDefault(require(\"./test2.js\"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { \"default\": obj }; }\n\nconsole.log('this is test1.js ', _test[\"default\"]);"},"./test2.js":{"dependencies":{},"code":"\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", {\n value: true\n});\nexports[\"default\"] = void 0;\n\nfunction test2() {\n console.log('this is test2 ');\n}\n\nvar _default = test2;\nexports[\"default\"] = _default;"}})
- 复制这段代码到浏览器中运行即可
最后
- 纸上得来终觉浅,这些手写框架&库源码,都需要一些时间去钻研,当你理解了源码之后,就会发现,源码其实大都差不多,所以你要抓住每个框架&库源码实现最重要的点,但没有必要全部去搞懂它,抓重点学习是很重要的
- 如果感觉对你有帮助,可以点个
赞,让更多人看到这篇文章 - 同时,欢迎你关注我的公众号:[
前端巅峰],我的gitHub源码地址是:https://github.com/JinJieTan/Peter-,记得Star哦
以上是 金九银十冲刺大厂,你需要知道的性能优化和手写源码 的全部内容, 来源链接: utcz.com/a/39027.html