图计算黑科技:打开中文词嵌入训练实践新模式
在自然语言处理领域,文本表示学习技术可以帮助我们将现实世界转化为计算机可以处理的数据,以求更精准地建立学习模型。而在中文搜索场景下,同音词、易混词、错别字等文本的召回和相似度匹配一直存在着棘手的问题,本文将尝试从图计算的角度来进行中文词向量的训练,并取得了积极的效果,希望与大家一同分享交流。文章作者:翟彬旭,腾讯云大数据高级研发工程师。
一、技术背景
在中文搜索场景下,同音词、易混词、错别字等文本的召回和相似匹配是一个常见且棘手的问题。NLP(自然语言处理)社区对文本的匹配和召回已经经历从早期的基于分词和倒排索引的全文检索过渡到如今流行的文本向量检索。
向量检索通过训练和学习文本的分布式表征得到文本向量,可以解决倒排索引无法解决的语义相似度匹配问题,而且针对高维向量的大规模快速检索在业界已经有相当成熟的解决方案,如Faiss、Nmslib等。
但目前业内常用的表示学习方法很少考虑中文场景下由于输入法输入错误、发音问题等导致的文本相似匹配问题。
例如,在笔者所在的腾讯云企业画像产品研发过程中,就经常遇到类似的需求。当用户在我们的产品中搜索“腾迅科技集团股份有限责任公司”时,此时用户希望搜索的企业工商注册名称应该是“腾讯科技(深圳)有限公司”,但由于输入法错误(将“腾讯”错输为“腾迅”)、认知错误(将“有限责任公司”误认为“集团股份有限责任公司”)等原因,导致用户输入无法匹配到想要的搜索结果,甚至出现OOV的情况(“腾迅”可能不在词表中)。
如何在无需过多考虑语义相似度的前提下解决中文词形学表示学习的问题是本文讨论的重点话题。
二、词嵌入训练的演进
在统计学习模型中,使用词嵌入(Word Embedding)完成自然语言处理任务,是NLP领域里的一项关键技术。常见的词嵌入(又称为文本表征)训练方法及主要特点如下图所示。
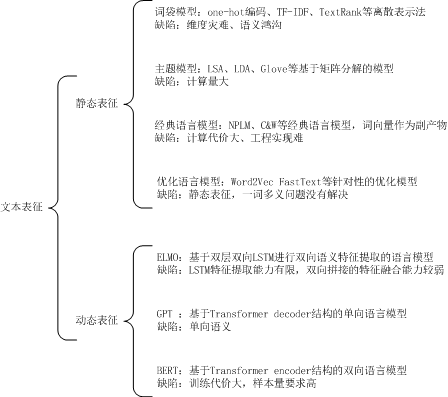 图1. 文本分布式表征方法概览
图1. 文本分布式表征方法概览
早期的词嵌入研究主要包括One-hot编码、TF-IDF等词袋模型。词袋模型(Bag of Words, BOW)是指忽略文档的语法和语序等要素,将文档仅仅看成是若干无序单词的集合,并且每个词都是独立的。
这些方法都属于离散表示法,当词汇表庞大时,会占用很大的存储空间,词汇表的大小决定了向量的维度大小,存在维数灾难问题。此外,这类方法无法通过任何计算得到词语之间的相似度,因此词向量之间不存在关联关系。
鉴于词袋表示法存在维度灾难、语义鸿沟的问题,Yoshua Bengio等人在[1]中证明使用神经网络训练的语言模型可以生成更好的词向量,并且提出了很多优化训练的方法。
如下图所示,整个网络分为两部分,第一部分是利用词特征矩阵C获得词的分布式表示(即词嵌入)。第二部分是将表示context的n个词的词嵌入拼接起来,通过一个隐藏层和一个输出层,最后通过softmax输出当前的p(wt|context)(当前上下文语义的概率分布,最大化要预测的那个词的概率,就可以训练此模型)。
这一模型框架不但训练了一个用神经网络表示的语言模型,而且作为语言模型的副产物还获得了词语的词嵌入(存在矩阵C中)。
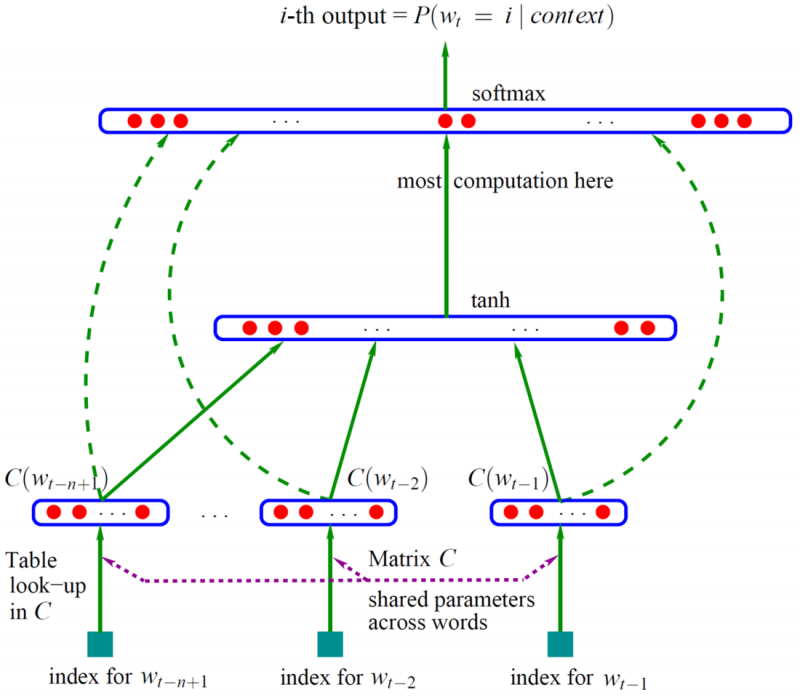
图2. 经典的自然语言模型(Bengio et al., 2003)
经典语言模型的训练存在计算量大的问题(主要集中在隐含层到输出层的全连接层以及输出层的softmax计算上),具体实现较为困难,针对这些问题,Mikolov等人[2,3]在语言模型的基础上进行了简化并给出了Cbow和skip-gram两种架构的word2vec模型,同时在具体学习过程中可以采用两种降低复杂度的近似方法——Hierarchical Softmax和Negative Sampling。
如下图所示,这种架构大大简化了计算量。不过,word2vec训练出来的词向量与单词是一对一的静态映射关系,一词多义问题没有解决。
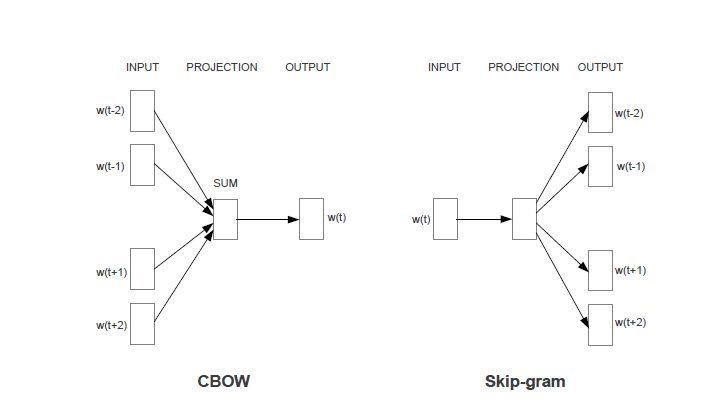
图3. word2vector模型结构
为了解决一词多义问题,ELMO模型[4]被提出来,它通过语言模型进行学习,得到一个词嵌入表示,在实际使用词嵌入时,根据上下文单词的语义再去调整单词的词嵌入表示,从而使得单词在不同的上下文语境得到不同的词嵌入表示。
网络结构采用双向LSTM网络。其中前向双层LSTM和逆向LSTM分别代表正方向和反方向编码器,输入分别是单词的上文和下文。一个句子输入到训练好的网络中,最终将得到每个单词三个不同的嵌入表示:双向LSTM中的两层词嵌入表示以及单词的词嵌入表示。其中双向LSTM中的两层词嵌入表示分别编码了单词的句法信息和语义信息。在做实际任务时,网络中单词对应的词嵌入表示将被提取出来作为新特征补充到实际任务中去。
ELMO根据上下文动态调整后的embedding不仅能够找出对应的相同语义的句子,而且还可以保证找出的句子中的同义词对应的词性也是相同的。不过,ELMO使用LSTM提取特征的能力不如后来的Transformer,其双向语言模型采取的是用简单的拼接来融合特征,一体化特征融合表现欠佳。
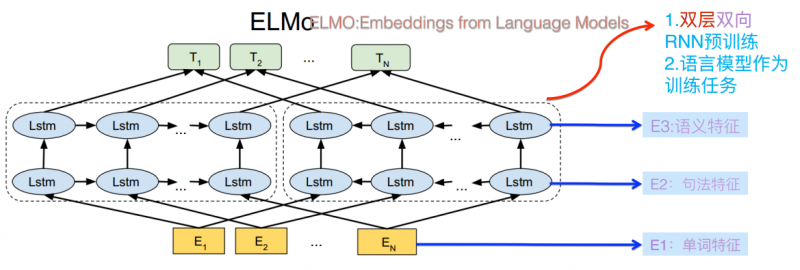
图4. ELMO模型示意图
BERT[5]作为动态词嵌入表示学习的集大成者,是一种双向融合特征的模型。
BERT提出两个任务:MLM(Masked Language Model)和NSP(Next Sentence Predict)。前者是词级别的,其采取的方法是,随机挡住15%的单词,让模型去预测这个单词,能够训练出深度的双向词嵌入向量表示;后者是句子级别的,也是一个二分类任务,其采取的方法是,将两个句子的序列串连作为模型的输入,预测后一句是否是前一句文本的下文,这一方法能够学习句子之间的关系,捕捉句子级别的表示。因此BERT得到的词嵌入表示融入了更多的语法、词法以及语义信息,而且动态地改变词嵌入也能够让单词在不同的语境下具有不同的词嵌入。
不过,BERT 对数据规模要求较高,如果没有足够大的语料,则很难达到预期的效果;其计算量很大,所需成本较高。
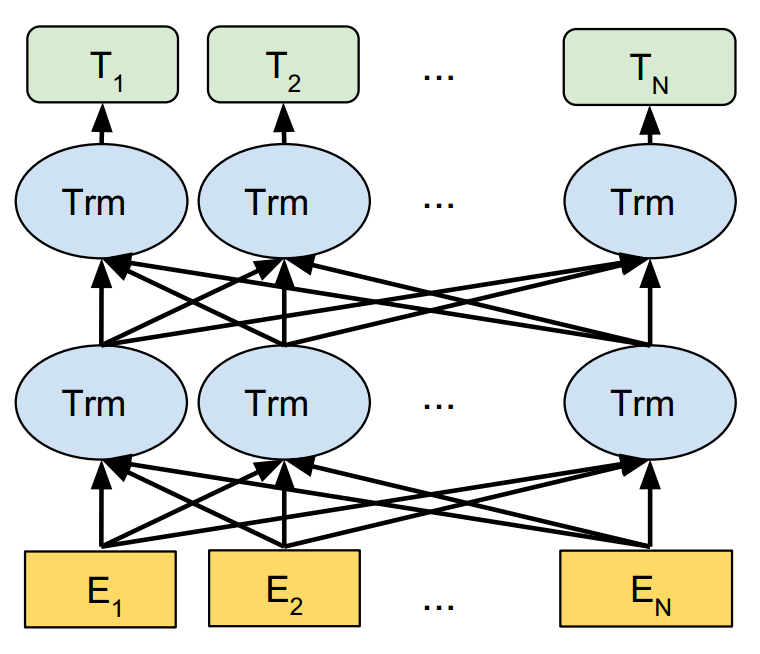
图5. BERT模型结构示意图
目前已经存在的主要词向量模型都是基于西方语言,这些西方语言的内部组成都是拉丁字母,然而,由于中文书写和西方语言完全不同,中文词语存在同音字、错别字等场景,而且中文字符内部的偏旁部首以及发音也包含了很强的语义信息,因此,如何有效利用中文字符内部的语义信息来训练词向量,成为近些年研究的热点[6,7,8]。
这里的典型代表是2018年蚂蚁金服提出的基于中文笔画的cw2vec模型[6]。文中将中文笔画划分为5类,类似于fasttext[9]的思想,每个词语使用n-gram 窗口滑动的方法将其表示为多个笔画序列。每个 gram 和词语都被表示成向量,用来训练和计算他们之间的相似度。为了简化计算文中也采用了负采样的方法,实验也取得了良好的效果。
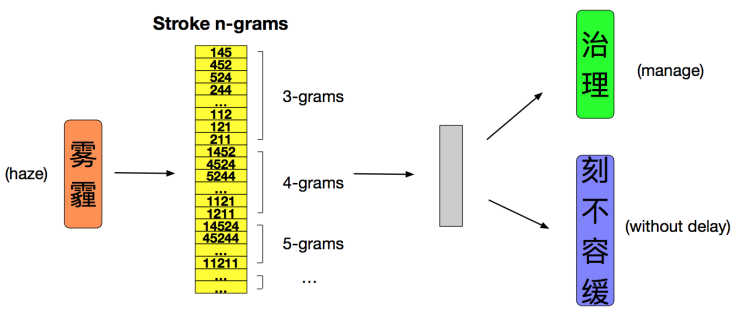
图6. cw2vec模型示意图
三、存在的问题及解决方案
从以上相关工作可以看出,当前主要的词嵌入表征学习方法主要集中在从文本语料的上下文语义角度学习词嵌入,对于其他角度如中文词形学角度的研究较少。采用这些方法训练学习得到的词向量,即使在中文编辑距离较近、发音相同的词语,在词嵌入空间的距离也相差甚远。
例如,以腾讯AILab发布的百万词向量为例,该版词向量模型可以较好地捕捉中文词语间的语义相似度,但对于子词和同音字的相似度量场景,效果欠佳,如下图所示。
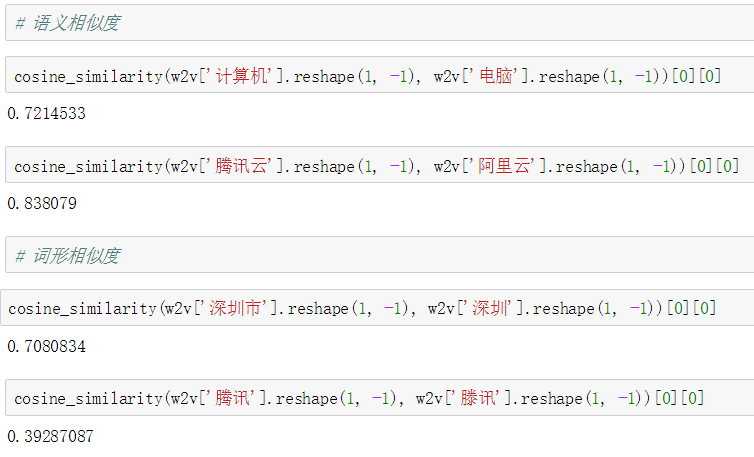
图7. 词向量相似度计算示例
在无需过多考虑语义相似度的前提下,本文提出从图计算的角度训练学习文本的向量表征,解决中文词形学相似匹配的问题。算法基本原理如下。
将常用汉字及业务场景下的词库构建无向带权图:每个词语和汉字作为图中一个节点,同时加入子词和拼音节点,依次在图中的“词语-子词-单字-拼音”节点间建立连边(如图8所示),根据字词之间在拼音和构成上的编辑距离(此处可根据业务需求灵活设置,亦可直接单独训练权重模型)为节点之间的连边赋予权重。
特别地,本文重点在同音字、平舌音、翘舌音以及子词序列等类型的节点间建立了连边,以保证同音字、易混字在图中可达,同时子词(subword)的引入在一定程度上保留了文本的语序特征。而后采用node2vec或metapath2vec等skip-gram类模型学习得到各节点的向量表示,以此作为字符的分布式表征。
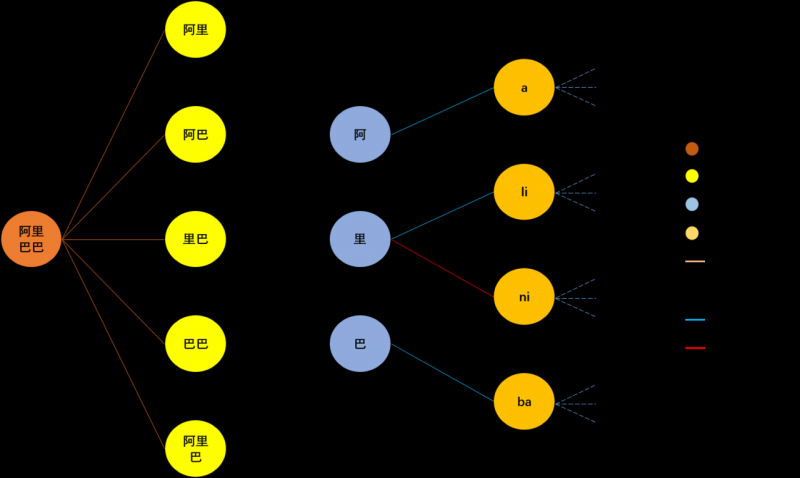
图8. 构图示例
在游走方式的选择上,对于当前业内主要的学习方法,如deepwalk[10]、node2vec[11]、Line[12]、metapath2vec[13]等算法,考虑到这里构造的图是带权图,故而不宜采用deepwalk,而图中的节点关联需要考虑二度以上联系,故不宜采用Line,所以本文重点对比node2vec和metapath2vec算法在嵌入效果上的差异。
对于未登录词,可以采用类似FastText的方法将未登录词的单字向量求平均得到,如果单字也是未登录词则采用拼音节点的词向量代替。这种方式可以获得较高质量的词嵌入,使得词形上接近的单词在词嵌入空间也拥有较高的相似性,同时由于拼音和子词节点的加入,大大缓解了OOV(Out Of Vocabulary)的问题。
简而言之,算法主要步骤包括以下部分:构建图 —> 随机游走采样 —> 训练词嵌入。
以上就是对于腾讯自研的中文词形表示学习算法 AlphaEmbedding 的完整介绍。AlphaEmbedding 从图计算的角度重点解决针对中文场景下的分布式词表征学习问题,使得学习到的词向量在中文词形学角度相近的词语在向量空间中也拥有较近的距离。
四、实验结果
实验数据采用全量国内工商注册企业名称(约2.2亿家),对企业名称进行名称分割(这里由于业务需要,已经开发了一个可用的BERT-CRF序列标注模型),针对name字段清洗、过滤、去重后构建图。输入数据示例如下图所示:
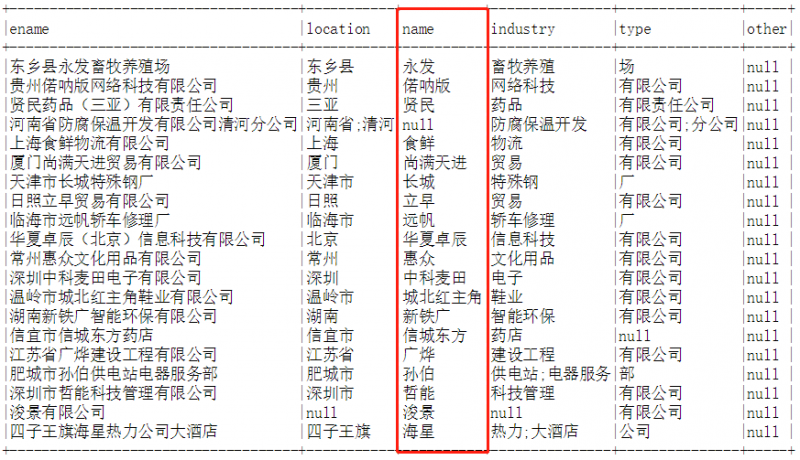
图9. 名称分割示意图
构建图部分采用Pyspark实现,形成的图的规模包含千万节点、亿级边,随机游走和词嵌入训练采用WXG开源的plato计算框架在腾讯云EMR集群进行,在20个节点进行随机游走约用时1分钟左右,进行节点嵌入学习约耗时2小时左右。构建的带权图效果如下图所示:
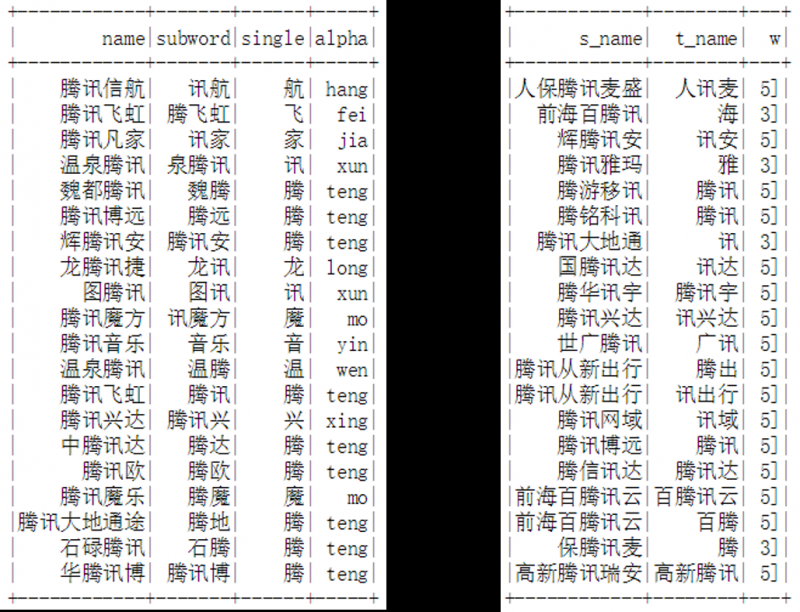
图10. 构建的无向带权图示例
在具体构图的实现方面,本文对比了两种实现方法:最初基于全称的排列组合,仅考虑同音词和子词在节点间建立连边,每个汉字节点最短两个字,拼音节点为对应汉字词语节点的拼音,我们称这种方法为combination style,其构图方式示意图如下图所示。
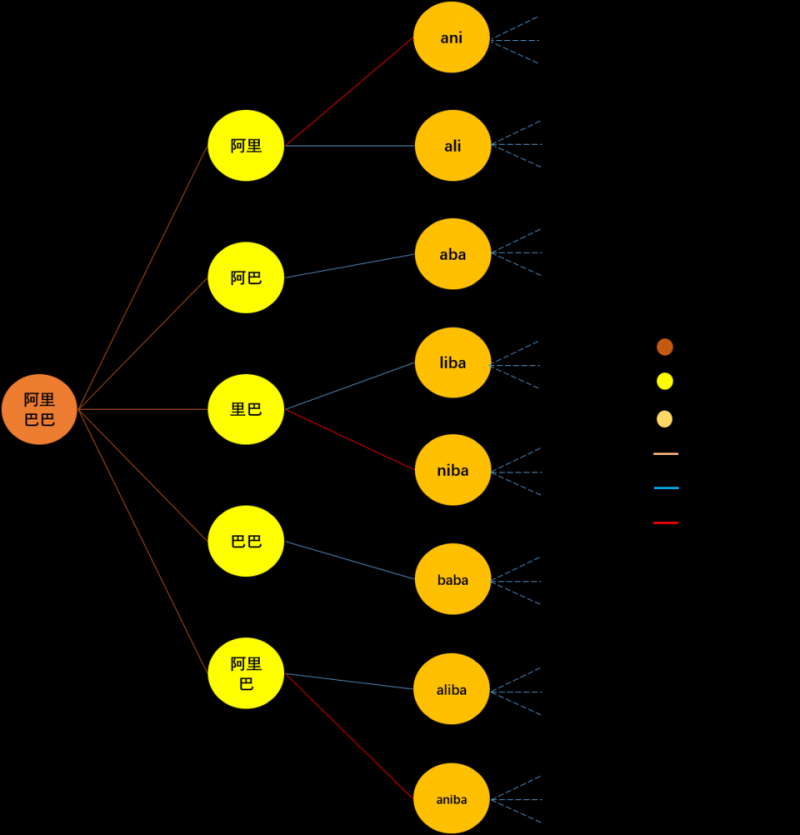
图11. combination style 构图示例
采用node2vec进行训练学习,以业务中常用的词语相似度排序为例,实验结果如下(检索词为“腾讯”,已在图中标红显示):
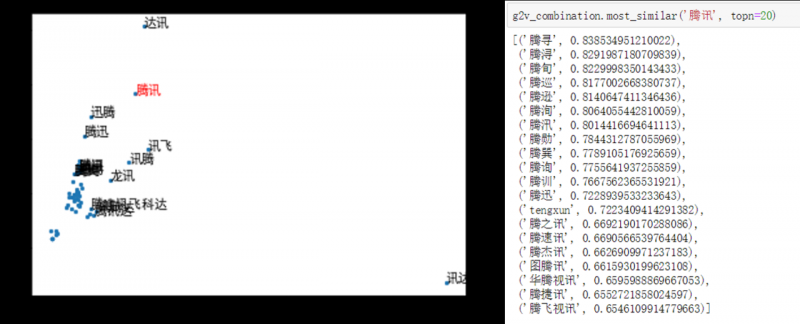
图12. combination style 效果
combination style 在业务应用中存在较多 OOV 的情况,之后采用更为简洁的“词语-子词-单字-拼音”构图方式(如图8所示),我们称之为fasttext style,并在节点嵌入学习中分别尝试了node2vec和metapath进行训练。这里仍以业务中常用的词语相似度排序为例,实验结果如下:

图13. fasttext style + node2vec 深度优先搜索效果
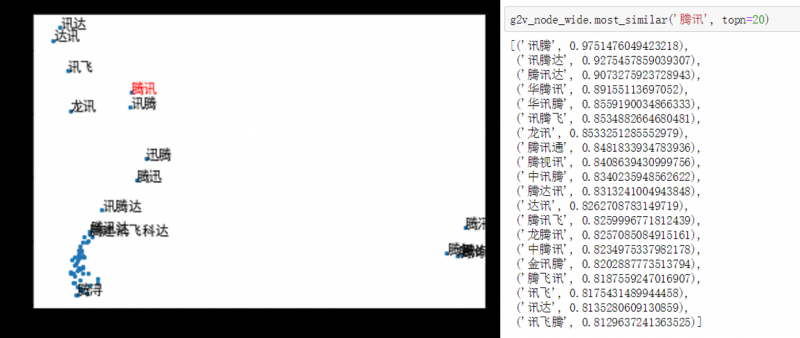
图14. fasttext style + node2vec 宽度优先搜索效果
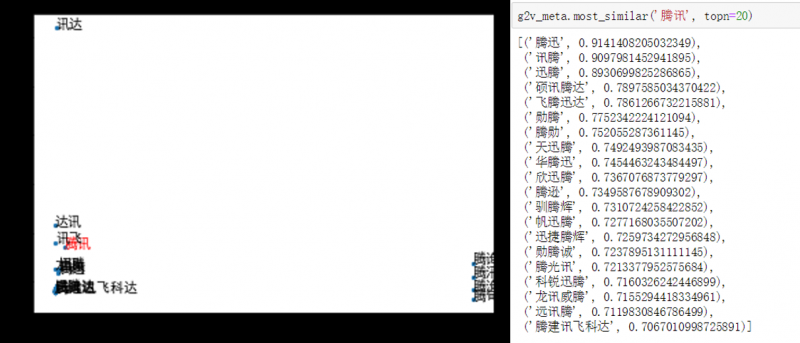
图15. fasttext style + metapath2vec 效果
其中,三种游走方式的参数设置如下,除游走采样设置不同外,其他输入数据、嵌入学习参数均相同:
node2vec 深度优先:p=100, q=0.2, step=5, epoch=30
node2vec 宽度优先:p=100, q=5, step=5, epoch=30
metapath2vec:meta="3-2-1-0"(词语-子词-单字-拼音), step=5, epoch=30
word2vec: learning_rate=[(linear, 0.02, 0.0001)], window_size=5, epoch=20
从实验对比效果可以发现,combination style 的构图方式由于仅考虑库内词表的排列组合,图的规模最小(一千万节点),与检索词之间距离最近的都是同音词,但同音词间的排序未考虑单字构成上的相似度,拼音节点作为相似度排序的分界点,之后的子词节点相似度急剧下滑,总体效果相对欠佳。
metapath2vec 获得的词表规模相比 combination style 大但比 node2vec 小(两千多万节点),相似词语更偏好子词节点,且各近邻词语间的区分度较差。
这一结果可能与游走方式有关,一方面,metapath定义的游走方式较为固定,若仅采用“词语-子词-单字-拼音”的方式进行游走,实际业务图上存在较多词语(二字词语)没有子词而只能连接单字的场景(此时对应的metapath应该为“词语-单字-拼音”),这些metapath在采样时就会丢失,造成节点采样失衡,另一方面由于子词节点在游走过程中始终同词语节点共现,所以子词节点的相似度整体相对较高。由于metapath2vec 训练结果区分度差的特性,使得获得的词嵌入在下游任务中的表现并不理想。
node2vec 深度优先搜索和宽度优先搜索效果接近,二者获得的词表规模相同(近三千万节点),针对特定检索词返回的排序结果也很接近。
相对而言,深度优先搜索获得的结果可以匹配到编辑距离更大的子词,模型的容错边界被外推到更大的范围;宽度优先搜索获得的近邻词语间的区分度更加平滑,对下游任务的应用更加友好。而对于编辑距离相同的子词对,由于都考虑了n-gram词序信息,两种搜索方式返回的子词对的相对排序也基本相同。
整体而言,相对于上面提到的两种构图和游走方式,node2vec 模型获得的词向量效果相对更好,且宽度优先搜索的结果更符合业务需求。
五、总结
本文回顾了NLP领域当前主要的文本分布式表示学习方法,针对中文搜索场景下同音词、易混词等文本的相似匹配问题,尝试从图计算的角度提出一种词向量训练方法,使得模型学习到的词向量在中文词形学角度相近的词语在向量空间中也拥有较近的距离。
通过对比 combination style 和 fasttext style 两种不同的构图方式以及 node2vec 深度优先、node2vec 宽度优先和 metapath2vec 三种不同的边采样方法得到的词嵌入在业务应用中的效果,探索了图计算在文本表示学习中的应用,为提升业务效果提供了积极的帮助。
目前这一工作已经应用于腾讯云企业画像产品搜索业务中。未来我们会在相关方面进行更多尝试和探索,例如考虑加入笔画对单字构造建模,以期借此提升错别字的相似匹配效果;考虑采用GCN/GraphSAGE/GAT等图神经网络建模,以期提升词嵌入质量等,也欢迎业内同学提供更多思路,批评指正。
参考文献:
[1] Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155.
[2] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
[3] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[4] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
[5] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[6] Cao S, Lu W, Zhou J, et al. cw2vec: Learning chinese word embeddings with stroke n-gram information[C]//Thirty-second AAAI conference on artificial intelligence. 2018.
[7] Yin R, Wang Q, Li P, et al. Multi-granularity chinese word embedding[C]//Proceedings of the 2016 conference on empirical methods in natural language processing. 2016: 981-986.
[8] Xu J, Liu J, Zhang L, et al. Improve chinese word embeddings by exploiting internal structure[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 1041-1050.
[9] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. arXiv preprint arXiv:1607.01759, 2016.
[10] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 2014: 701-710.
[11] Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 855-864.
[12] Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th international conference on world wide web. 2015: 1067-1077.
[13] Dong Y, Chawla N V, Swami A. metapath2vec: Scalable representation learning for heterogeneous networks[C]//Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2017: 135-144.
以上是 图计算黑科技:打开中文词嵌入训练实践新模式 的全部内容, 来源链接: utcz.com/a/32230.html