
谈谈Elasticsearch
什么是Elasticsearch?
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
介绍那儿有几个关键字:
实时
分布式
搜索
分析
于是我们就得知道Elasticsearch是怎么做到实时的,Elasticsearch的架构是怎么样的(分布式)。存储、搜索和分析(得知道Elasticsearch是怎么存储、搜索和分析的)
为什么要用Elasticsearch
在学习一项技术之前,必须先要了解为什么要使用这项技术。所以,为什么要使用Elasticsearch呢?我们在日常开发中,数据库也能做到(实时、存储、搜索、分析)。
相对于数据库,Elasticsearch的强大之处就是可以模糊查询。
有的同学可能就会说:我数据库怎么就不能模糊查询了??我反手就给你写一个SQL:
select * from user where name like '%Java%'的确,这样做的确可以。但是要明白的是:name like %Java%这类的查询是不走索引的,不走索引意味着:只要你的数据库的量很大(1亿条),你的查询肯定会是秒级别的.
而且,即便给你从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给你,往往你需要的数据量并没有这么多,可能50条记录就足够了。
而Elasticsearch是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
下面我们就来学学为什么Elasticsearch可以做到上面的几点。
Elasticsearch的数据结构
众所周知,你要在查询的时候花得更少的时间,你就需要知道他的底层数据结构是怎么样的;举个例子:
- 树型的查找时间复杂度一般是O(logn)
- 链表的查找时间复杂度一般是O(n)
- 哈希表的查找时间复杂度一般是O(1)
....不同的数据结构所花的时间往往不一样,你想要查找的时候要快,就需要有底层的数据结构支持
从上面说Elasticsearch的模糊查询速度很快,那Elasticsearch的底层数据结构是什么呢?我们来看看。
Elasticsearch的索引是倒排索引。
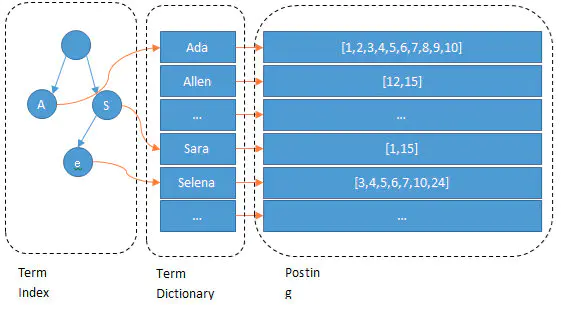
我们输入一段文字,Elasticsearch会根据分词器对我们的那段文字进行分词(也就是图上所看到的Ada/Allen/Sara..),这些分词汇总起来我们叫做Term Dictionary,而我们需要通过分词找到对应的记录,这些文档ID保存在PostingList
在Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个Term Dictionary
由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是Elasticsearch还抽了一层叫做Term Index,这层只存储 部分词的前缀,Term Index会存在内存中(检索会特别快)
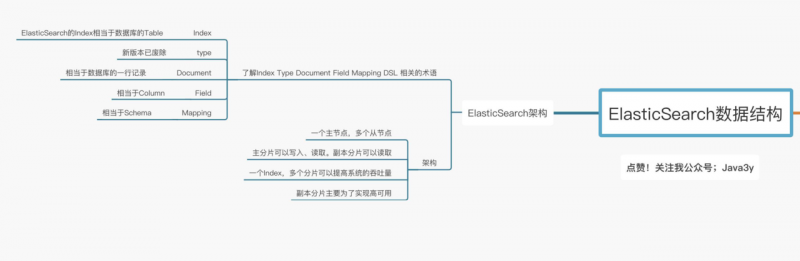
Elasticsearch的术语和架构
在讲解Elasticsearch的架构之前,首先我们得了解一下Elasticsearch的一些常见术语。
- Index:Elasticsearch的Index相当于数据库的Table
- Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type--有点类似于消息队列一个topic下多个group的概念)
- Document:Document相当于数据库的一行记录
- Field:相当于数据库的Column的概念
- Mapping:相当于数据库的Schema的概念
- DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
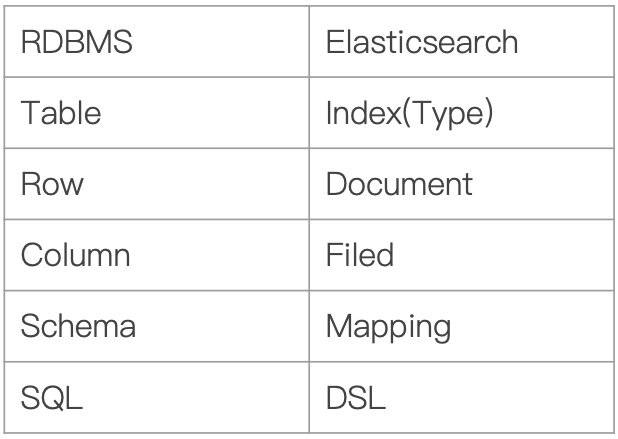
相信大家看完上面的对比图,对Elasticsearch的一些术语就不难理解了。那Elasticsearch的架构是怎么样的呢?下面我们来看看:
一个Elasticsearch集群会有多个Elasticsearch节点,所谓节点实际上就是运行着Elasticsearch进程的机器。
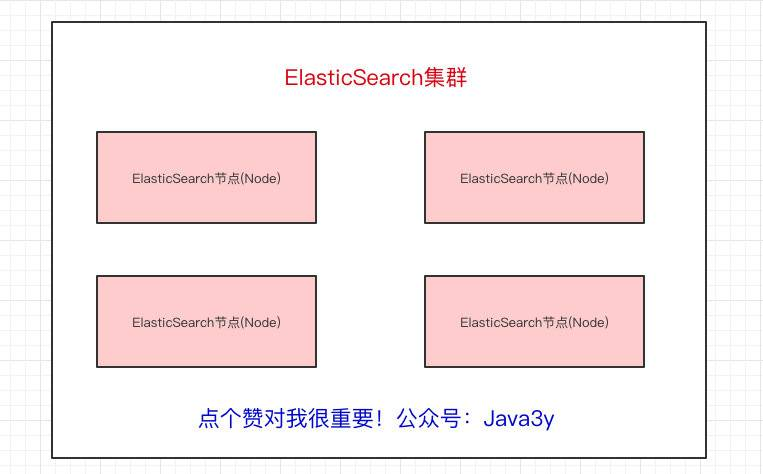
在众多的节点中,其中会有一个Master Node,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。
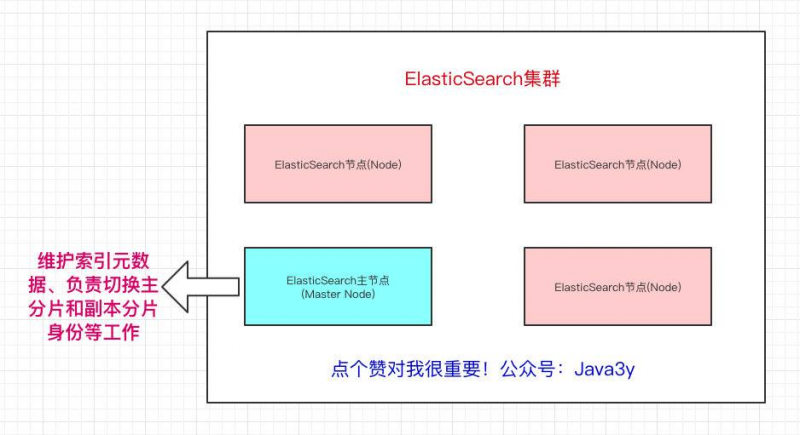
从上面我们也已经得知,Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
比如现在我集群里边有4个节点,我现在有一个Index,想将这个Index在4个节点上存储,那我们可以设置为4个分片。这4个分片的数据合起来就是Index的数据
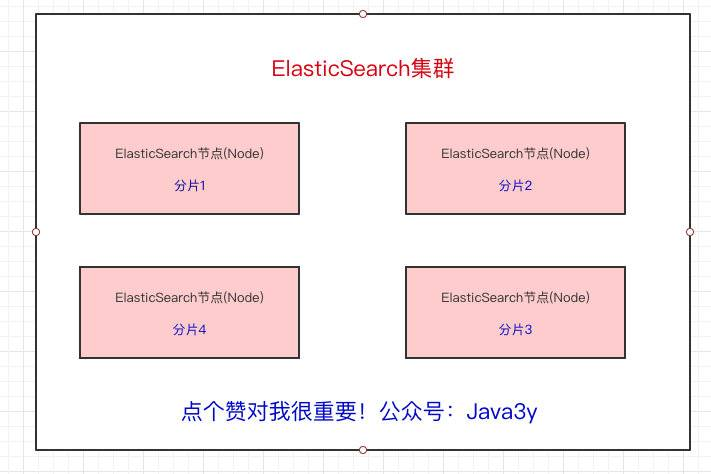
为什么要分片?原因也很简单:
- 如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
现在问题来了,如果某个节点挂了,那部分数据就丢了吗?显然Elasticsearch也会想到这个问题,所以分片会有主分片和副本分片之分(为了实现高可用)
数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。
Index需要分为多少个分片和副本分片都是可以通过配置设置的
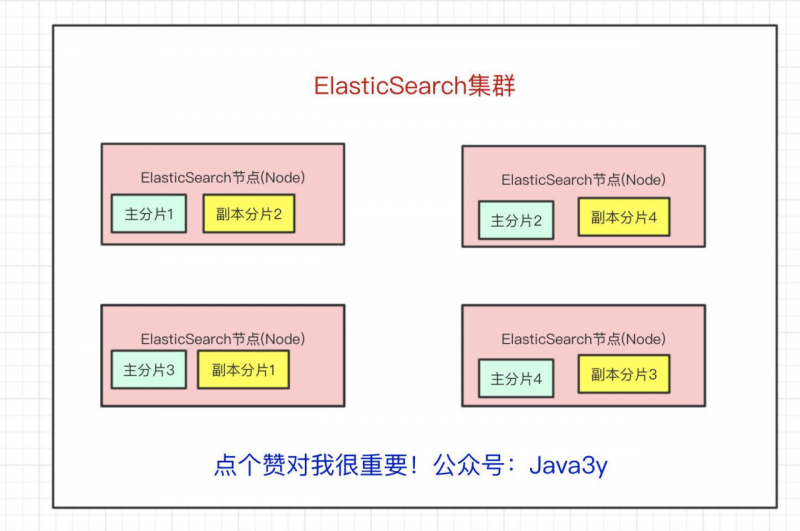
如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
到这里我们可以简单总结一下Elasticsearch的架构了:
Elasticsearch 写入的流程
上面我们已经知道当我们向Elasticsearch写入数据的时候,是写到主分片上的,我们可以了解更多的细节。
客户端写入一条数据,到Elasticsearch集群里边就是由节点来处理这次请求:
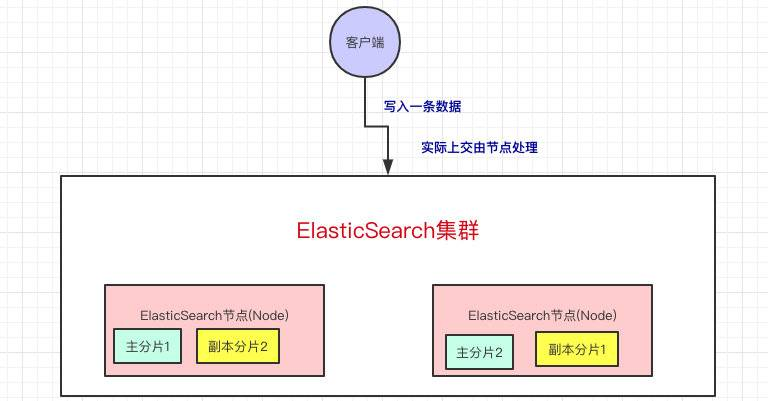
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
- coodinate(协调)节点通过hash算法可以计算出是在哪个主分片上,然后路由到对应的节点
- shard = hash(document_id) % (num_of_primary_shards)
路由到对应的节点以及对应的主分片时,会做以下的事:
首先我们从分布式集群的角度分析下写入,采用系统默认的参数来说明
假设集群有三个节点,都存储数据,indexA 有5个分片,2个复制集。
数据如下分布:
Node1: shard1
Node2: shard2,shard3,shard1-R1(shard1的复制集)
Node3: shard4,shard5,shard-R2(shard1的复制集)
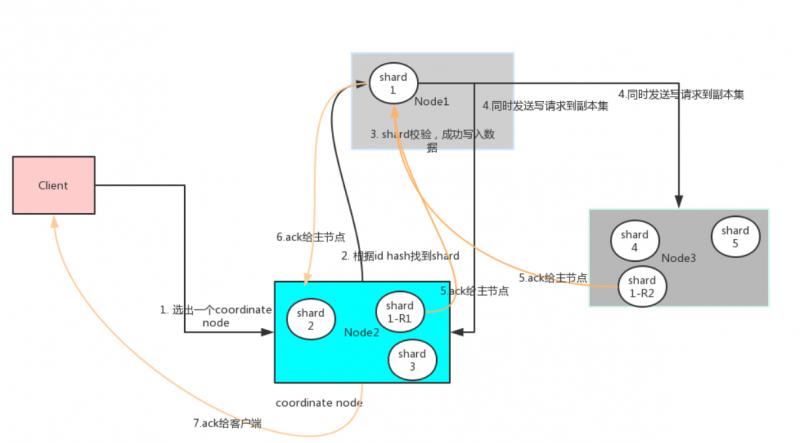
- 首先客户端根据配置的连接节点,通过轮询方式连接到一个coordinate节点。
coordinate节点不是很master/client/data节点一个维度的描述,它就是指处理客户端请求的节点。这个描述和cassandra的coordinate节点是一个概念。集群中所有的节点都可以是coordinate节点。
coodinate节点通过hash算法计算出数据在shard1上shard = hash(document_id) % (num_of_primary_shards),然后根据节点上维护的shard信息,将请求发送到node1上。
node1 对索引数据进行校验,然后写入到shard中。具体细节见下一节写入到shard
主节点数据写入成功后,将数据并行发送到副本集节点Node2,Node3。
Node2,Node3写入数据成功后,发送ack信号给shard1主节点Node1。
ode1发送ack给coordinate node
coordinate node发送ack给客户端。
整个过程coordinate node部分类似cassandra,主shard节点和副本集受master-slave模式影响,必须有master决定写入成功与否,和mysql类似的。
写入shard
上面第三步骤,shard内写入还需要详细分析下
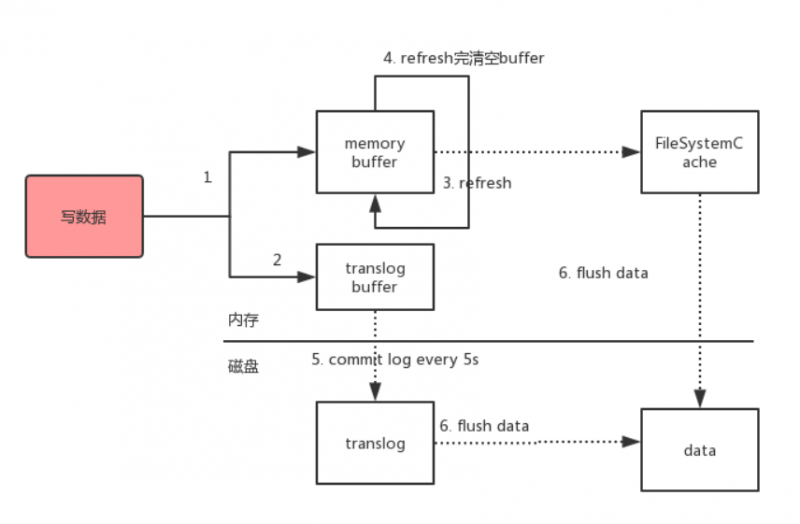
- 数据写入到内存buffer
- 同时写入到数据到translog buffer
- 每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了
- refresh完,memory buffer就清空了。
- 每隔5s中,translog 从buffer flush到磁盘中
- 定期/定量从FileSystemCache中,结合translog内容flush index到磁盘中。做增量flush的。
各种数据库的单节点写入过程大同小异,一般都是写内存,记录操作日志(防止节点宕机,内存中的数据丢失)然后flush到磁盘,有个线程不断的merge 数据块。不过是写入的数据格式不同。
1、Buffer(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用。比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
2、Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
所以写入到buffer中的数据,还是原始数据,还没有索引,搜索不到的。只有到Cache中还可以。
常见面试题
ES与Lucence的区别:
分布式搜索引擎:ES可以自动将海量数据分散到多台服务器上去存储和检索
Lucene:单机应用,最多只能处理单台服务器可以处理的数据量
区别:Lucence实现起来比较复杂,对比而言,ES是基于lucence的,对lucence进行了简化,提供了简单易用的restful api接口,支持分布式。
ES的分布式架构原理能说一下吗?
Es设计理念就是分布式搜索引擎,底层还是Lucence,核心思想就是在多台机器上启动多个es实例,组成一个es集群。es中存储数据的基本单位是索引,这个索引
可以拆分成多个shard,每个shard存储部分数据,每个shard都有一个primary shard,负责写入数据,相应的每个primary shard可能有几个replica shard(只负责读),primary
shard 写入数据后,会将数据同步到replica shard上去。es集群有多个节点,会自动选举一个节点为master节点。同时将宕机所对应的存活于其他节点的replica shard
提升为 primary shard。
ES写入数据的工作原理是什么?
写入数据时首先将数据随机发送到一个节点上,这个节点成为cooridinate shard,这个协调节点会进行hash路由,将数据发送到
对应的节点上的primary shard,同时primary 将数据同步给replica shard上。写完成功后,协调节点返回客户端成功。
ES在大数据(几亿)下如何提高查询效率:
首先ES优化不是能够通过调参数能够解决的
我们自己的生产环境实践经验,所以说我们当时的策略,是仅仅在es中就存少量的数据,就是你要用来搜索的那些索引,内存留给filesystem cache的,
就100G,那么你就控制在100gb以内,相当于是,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在1秒以内
缓存预热:
哪怕是你就按照上述的方案去做了,es集群中每个机器写入的数据量还是超过了filesystem cache一倍,比如说你写入一台机器60g数据,
结果filesystem cache就30g,还是有30g数据留在了磁盘上。
对于那些你觉得比较热的,经常会有人访问的数据,最好做一个专门的缓存预热子系统,就是对热数据,每隔一段时间,
你就提前访问一下,让数据进入filesystem cache里面去。这样期待下次别人访问的时候,一定性能会好一些。
冷热分离:
你最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,
这样可以确保热数据在被预热之后,尽量都让他们留在filesystem os cache里,别让冷数据给冲刷掉。
参考文章:
juejin.im/post/5e264b…
www.cnblogs.com/stoneFang/p…
以上是 谈谈Elasticsearch 的全部内容, 来源链接: utcz.com/a/29805.html








