mongoDB实现分页的方法
mongoDB的分页查询是通过limit(),skip(),sort()这三个函数组合进行分页查询的。
下面这个是我的测试数据
db.test.find().sort({"age":1});

第一种方法
查询第一页的数据:db.test.find().sort({"age":1}).limit(2);

查询第二页的数据:db.test.find().sort({"age":1}).skip(2).limit(2);

查询其他页数以此类推。。。
第二种方法
查询第一页的数据:db.test.find().sort({"age":1}).limit(2);
跟上面的第一种方法一样的。
查询第二页的数据:
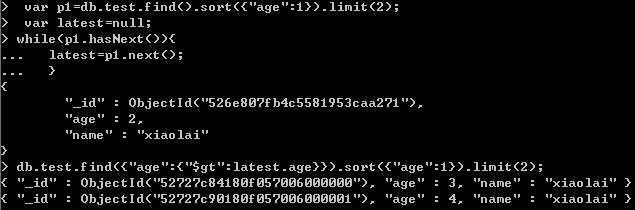
这个是获取第一页最后一条记录的值,然后排除前面的记录,就能获取到新的记录了
总结来说,如果数据量不是很大的话,可以使用第一种方法,毕竟比较简单,如果数据量比较大的话,使用第二种方法比较好,因为这样就可以不用到skip()这个函数,skip跳过太多的记录,效率有点低
经过认真的考虑,第二种方法确实不适合跳页,而且效率也不是很高
对于海量数据的话,我们要做些特殊的处理,
有以下2种方法
第一种方法

限制分页的页数,类似百度的百度的分页处理,只是显示前面的七百多条记录,这样的就不用考虑性能的问题了,毕竟一般人都只是翻到前面十页,就找到自己需要的了
后面的统计结果应该是估算出来的,根据查出来的这些记录所占的比例估算出总的记录数
第二种方法
我们可以这样做,假设是根据id排序的,我们可以id跟id所在的页数的序号存到redis/MemberCached中,
就像这样,假设每一页有10条记录
id page
1 1
2 1
。。。
10 1
11 2
12 2
。。。。
20 2
这样我们查第一页的时候就能直接取出十条数据
假设有1亿条数据,一条记录id占4个字节,其他信息的占一个字节,一条记录就占5个字节
1 0000 0000 *5/(1024*1024)=476MB
这种做法使用空间换时间,一般数据库查询的时间大多花在跟数据库的连接上,放在缓存中,可以大大加快查询的速度
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
以上是 mongoDB实现分页的方法 的全部内容, 来源链接: utcz.com/a/253657.html