利用MongoDB中oplog机制实现准实时数据的操作监控
前言
最近有一个需求是要实时获取到新插入到MongoDB的数据,而插入程序本身已经有一套处理逻辑,所以不方便直接在插入程序里写相关程序,传统的数据库大多自带这种触发器机制,但是Mongo没有相关的函数可以用(也可能我了解的太少了,求纠正),当然还有一点是需要python实现,于是收集整理了一个相应的实现方法。
一、引子
首先可以想到,这种需求其实很像数据库的主从备份机制,从数据库之所以能够同步主库是因为存在某些指标来做控制,我们知道MongoDB虽然没有现成触发器,但是它能够实现主从备份,所以我们就从它的主从备份机制入手。
二、OPLOG
首先,需要以master模式来打开mongod守护,命令行使用–master,或者配置文件增加master键为true。
此时,我们可以在Mongo的系统库local里见到新增的collection——oplog,此时oplog.$main里就会存储进oplog信息,如果此时还有充当从数据库的Mongo存在,就会还有一些slaves的信息,由于我们这里并不是主从同步,所以不存在这些集合。
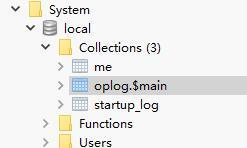
再来看看oplog结构:
"ts" : Timestamp(6417682881216249, 1), 时间戳
"h" : NumberLong(0), 长度
"v" : 2,
"op" : "n", 操作类型
"ns" : "", 操作的库和集合
"o2" : "_id" update条件
"o" : {} 操作值,即document
这里需要知道op的几种属性:
insert,'i'
update, 'u'
remove(delete), 'd'
cmd, 'c'
noop, 'n' 空操作
从上面的信息可以看出,我们只要不断读取到ts来做对比,然后根据op即可判断当前出现的是什么操作,相当于使用程序实现了一个从数据库的接收端。
三、CODE
在Github上找到了别人的实现方式,不过它的函数库太老旧,所以在他的基础上进行修改。
Github地址:https://github.com/RedBeard0531/mongo-oplog-watcher
mongo_oplog_watcher.py如下:
#!/usr/bin/python
import pymongo
import re
import time
from pprint import pprint # pretty printer
from pymongo.errors import AutoReconnect
class OplogWatcher(object):
def __init__(self, db=None, collection=None, poll_time=1.0, connection=None, start_now=True):
if collection is not None:
if db is None:
raise ValueError('must specify db if you specify a collection')
self._ns_filter = db + '.' + collection
elif db is not None:
self._ns_filter = re.compile(r'^%s\.' % db)
else:
self._ns_filter = None
self.poll_time = poll_time
self.connection = connection or pymongo.Connection()
if start_now:
self.start()
@staticmethod
def __get_id(op):
id = None
o2 = op.get('o2')
if o2 is not None:
id = o2.get('_id')
if id is None:
id = op['o'].get('_id')
return id
def start(self):
oplog = self.connection.local['oplog.$main']
ts = oplog.find().sort('$natural', -1)[0]['ts']
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter, tailable=True)
while True:
for op in cursor:
ts = op['ts']
id = self.__get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)
def all_with_noop(self, ns, ts, op, id, raw):
if op == 'n':
self.noop(ts=ts)
else:
self.all(ns=ns, ts=ts, op=op, id=id, raw=raw)
def all(self, ns, ts, op, id, raw):
if op == 'i':
self.insert(ns=ns, ts=ts, id=id, obj=raw['o'], raw=raw)
elif op == 'u':
self.update(ns=ns, ts=ts, id=id, mod=raw['o'], raw=raw)
elif op == 'd':
self.delete(ns=ns, ts=ts, id=id, raw=raw)
elif op == 'c':
self.command(ns=ns, ts=ts, cmd=raw['o'], raw=raw)
elif op == 'db':
self.db_declare(ns=ns, ts=ts, raw=raw)
def noop(self, ts):
pass
def insert(self, ns, ts, id, obj, raw, **kw):
pass
def update(self, ns, ts, id, mod, raw, **kw):
pass
def delete(self, ns, ts, id, raw, **kw):
pass
def command(self, ns, ts, cmd, raw, **kw):
pass
def db_declare(self, ns, ts, **kw):
pass
class OplogPrinter(OplogWatcher):
def all(self, **kw):
pprint (kw)
print #newline
if __name__ == '__main__':
OplogPrinter()
首先是实现一个数据库的初始化,设定一个延迟时间(准实时):
self.poll_time = poll_time
self.connection = connection or pymongo.MongoClient()
主要的函数是start() ,实现一个时间的比对并进行相应字段的处理:
def start(self):
oplog = self.connection.local['oplog.$main']
#读取之前提到的库
ts = oplog.find().sort('$natural', -1)[0]['ts']
#获取一个时间边际
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter)
#对此时间之后的进行处理
while True:
for op in cursor:
ts = op['ts']
id = self.__get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
#可以指定处理插入监控,更新监控或者删除监控等
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)
循环这个start函数,在all_with_noop这里就可以编写相应的监控处理逻辑。
这样就可以实现一个简易的准实时Mongo数据库操作监控器,下一步就可以配合其他操作来对新入库的程序进行相应处理。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对的支持。
以上是 利用MongoDB中oplog机制实现准实时数据的操作监控 的全部内容, 来源链接: utcz.com/a/253653.html