python pandas 根据某列分组,统计其对应列累加值
大家好,今天尝试用python处理这样的问题,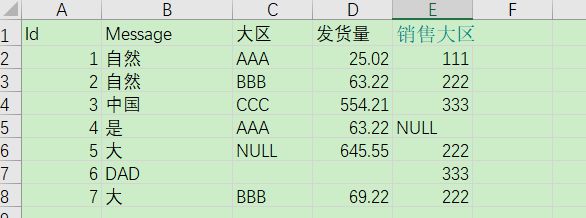
根据 销售大区分组 累加对应的发货量,并将发货量结果取整。有大区的值为NULL或者为空,希望能跳过不统计。输出的csv文件需要有大区+销售大区+发货量+Message
做了尝试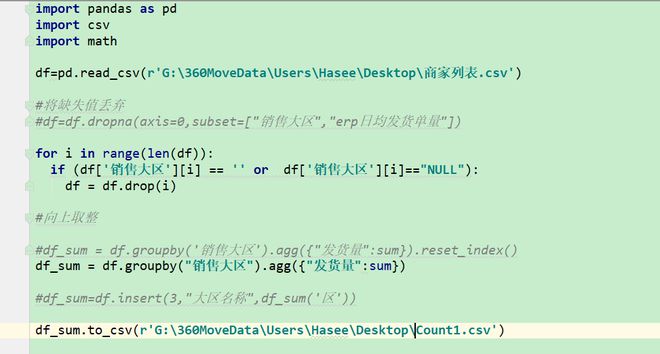
结果:
`
import pandas as pd
import csv
import math
df=pd.read_csv(r'G:\360MoveData\Users\Hasee\Desktop\商家列表.csv')
#将缺失值丢弃
#df=df.dropna(axis=0,subset=["销售大区","erp日均发货单量"])
for i in range(len(df)):
if (df['销售大区'][i] == '' or df['销售大区'][i]=="NULL"):
df = df.drop(i)
#向上取整
#df_sum = df.groupby('销售大区').agg({"发货量":sum}).reset_index()
df_sum = df.groupby("销售大区").agg({"发货量":sum})
#df_sum=df.insert(3,"大区名称",df_sum('区'))
df_sum.to_csv(r'G:\360MoveData\Users\Hasee\Desktop\Count1.csv')
`
问题
1.不知道怎么把大区列添加进去。
2.想用math.ceil()对销售大区和货单量值取整,不知怎么添加进去。
3.第一行为0.0,应该是NULL值和空值引起的,怎么避免。
以上是 python pandas 根据某列分组,统计其对应列累加值 的全部内容, 来源链接: utcz.com/a/162849.html