通过百度搜索抓取最新的电影和热门电影
之前可以使用豆瓣的 API 接口来获取数据,但是近年来豆瓣几乎都关闭了所有的 API,只能想想其他的办法了,搜索引擎应该是比较新的数据,我们可以抓取百度搜索引擎来实现我们的效果。
我使用的是 eggjs 作为后台,抓取的数据 24 小时更新一次,每次访问的时候先从缓存获取数据,如果没有就直接抓取百度的数据。
获取目标 HTML
在百度中搜索最新电影,大概是这个样子:

首先使用 curl 将我们要抓取的页面整个下载下来
let html = await this.ctx.curl(baiduUrl);html = html.data.toString();
分析 HTML
我们可以直接正则匹配上面截图的 html 代码,但是我发现如果电影名称长了,会自动转为省略号,并不是完整的名称,这种方式不好。
注意下面的页码翻页,应该是使用的 ajax 加载数据,我们可以从这里入手抓取我们想要的数据,通过浏览器调试工具:
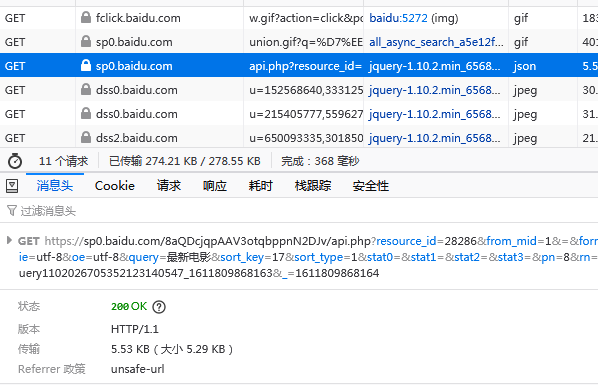
响应的结果:
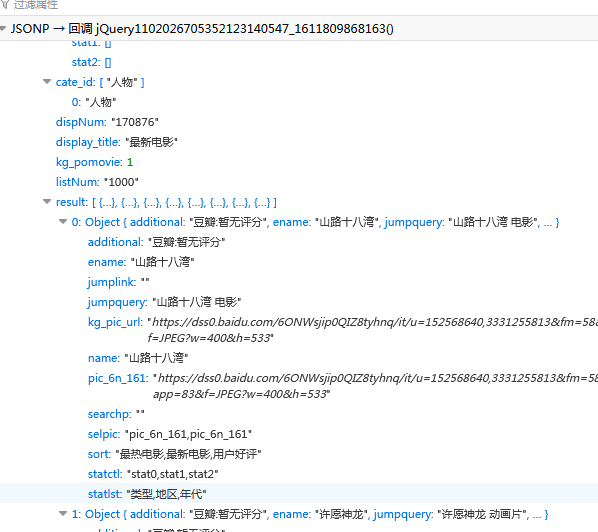
正是我们想要的结果,其中还包括了电影的封面和评分等信息,可谓相当的全面。
https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28286&from_mid=1&=&format=json&ie=utf-8&oe=utf-8&query=最新电影&sort_key=17&
sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=8&rn=8&
cb=jQuery1102026705352123140547_1611809868163&_=1611809868164
仔细查看上面的网址,发现有一个字符串(8aQDcjqpAAV3otqbppnN2DJv)不知道从什么地方获取,而且这个字符串肯定不是一直不变,在打开 HTML 查找,第 4000 多行有一个 JS 的配置:

但是后来我通过 服务端 去抓取网页的时候,这几个字段都是空的,可能是因为没有设置 user-agent 的原因吧,但是我发现了 fbtext 这个字段,这不就是我想要的名单吗?何必要搞其他分页之类的,直接上正则:
// 网页匹配let hotMove = [];
const regReturn = html.match(/fbtext: '(.*),'/gi);
if (regReturn) {
hotMove = regReturn[0].replace("fbtext: '", '').replace(",'", '').split(',');
}
完整的代码
async getBaiduMovie(type) { let baiduUrl = 'http://www.baidu.com/s?wd=最新电影';
if (type === 2) {
baiduUrl = 'http://www.baidu.com/s?wd=热门电影';
}
let html = await this.ctx.curl(baiduUrl);
html = html.data.toString();
let hotMove = [];
// 网页匹配
const regReturn = html.match(/fbtext: '(.*),'/gi);
if (regReturn) {
hotMove = regReturn[0].replace("fbtext: '", '').replace(",'", '').split(',');
}
return hotMove;
}
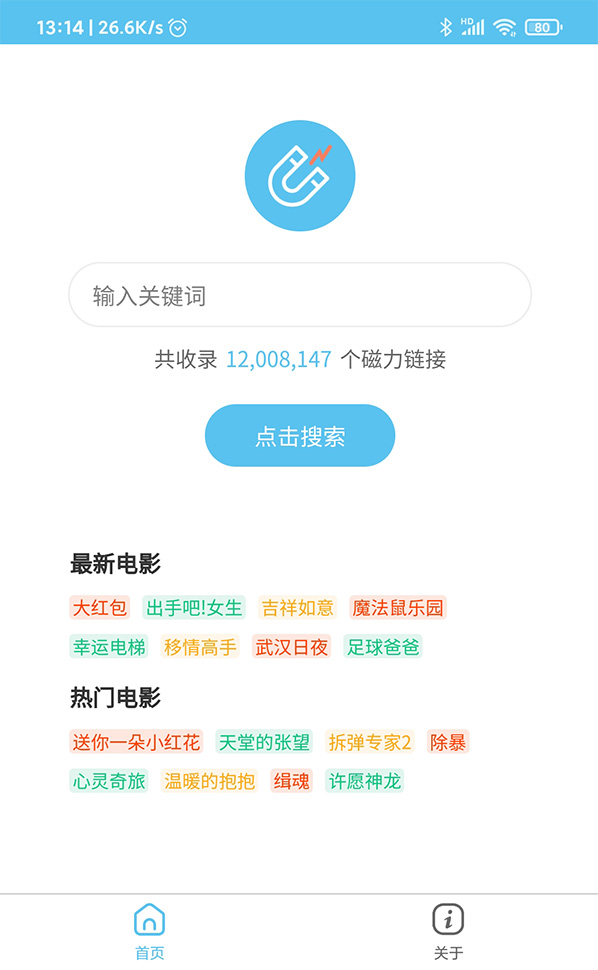
最终实现的效果
以上是 通过百度搜索抓取最新的电影和热门电影 的全部内容, 来源链接: utcz.com/p/232989.html