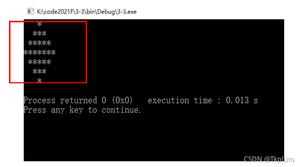
python 数组 不断更新最后输出代码优化
题目描述
需要对配置文件的多个行进行批处理操作,当遇到非 [USER前缀的字符时,用最近一个以[USER前缀的字符串做替代,由于[USER之间的值多少不一,只能逐次更新,最后输出一个最终的数组。但是感觉代码可以写的更简洁,暂时没有好的思路。
题目来源及自己的思路

相关代码
粘贴代码文本(请勿用截图)
import numpy as np
def main():
with open(r'D:python_softwareSKstudytmp2_tmp.txt',encoding='utf-8-sig') as f: L = f.readlines()
S = np.array(L)
S1 = []
S2 = []
S3 = []
S4 = []
S5 = []
S6 = []
S7 = []
S8 = []
S9 = []
for i,value in enumerate(S):
if str(value).startswith('[USER'):
S1.append(value)
else:
S1.append(S[i-1])
for j,value in enumerate(S1):
if str(value).startswith('[USER'):
S2.append(value)
else:
S2.append(S1[j-1])
for k, value in enumerate(S2):
if str(value).startswith('[USER'):
S3.append(value)
else:
S3.append(S2[k-1])
for l, value in enumerate(S3):
if str(value).startswith('[USER'):
S4.append(value)
else:
S4.append(S3[l-1])
for m, value in enumerate(S4):
if str(value).startswith('[USER'):
S5.append(value)
else:
S5.append(S4[m-1])
for n, value in enumerate(S5):
if str(value).startswith('[USER'):
S6.append(value)
else:
S6.append(S5[n-1])
for o, value in enumerate(S6):
if str(value).startswith('[USER'):
S7.append(value)
else:
S7.append(S6[o-1])
for p, value in enumerate(S7):
if str(value).startswith('[USER'):
S8.append(value)
else:
S8.append(S7[p-1])
for q, value in enumerate(S8):
if str(value).startswith('[USER'):
S9.append(value)
else:
S9.append(S8[q-1])
for x,value in enumerate(S9):
print(value, end='')
if name == '__main__':
main()你期待的结果是什么?实际看到的错误信息又是什么?
有更优化的代码,减少代码量
回答:
last_user = Noneresult = []
for line in f:
if line.startswith("[USER"):
last_user = line
result.append(last_user)
以上是 python 数组 不断更新最后输出代码优化 的全部内容, 来源链接: utcz.com/a/160170.html