python爬虫遇到动态加密怎么办?爬取某点评网站内容
![python爬虫遇到动态加密怎么办?爬取某点评网站内容[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2986211544_1.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于早起Python ,作者刘早起
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542在前几天针某点评商家搜索页面的字体反爬给出了解决方案,但是还有一个问题,那就是当时给出的方法是下载对应的woff字体文件,然后建立加密字体与编码之间的映射关系来进行破解。
但是有一个问题就是不同页面的字体文件,是动态加载的,换句话说就是你在这个页面建立的映射关系,换一个页面就不能用了。
那就没有解决办法了吗?其实也不难,或者说对方还是给了很清晰的思考方向,因为,虽然每一个页面的字体是动态加载的,但是这个动态仅针对字体解析后编码的变化,字体内部顺序是没有变化的,也就是如下图所示
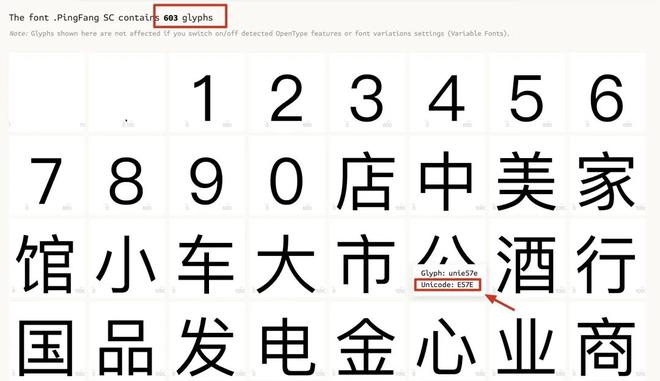
每两个页面中,仅仅是字体编码发生了改变,而字体的位置顺序并没有改变,所以我们只需要在解析每一页的数据之前,先提取页面中CSS样式,再从CSS内容中定位到字体文件存储链接,之后就是请求这一页对应的字体文件并解析构造匹配字典,后面的步骤就和上一篇文章一样了。
那我们开始,目标是爬取某城市指定美食的全部商家信息,比如定位广州搜索沙县小吃,之后爬取全部的搜索页面。
首先就是构造全部的URL,由于每一页的URL是有一定规律的,所以这一步很简单,从第一页中提取全部页数然后按照规律添加到url_list中即可,而这个数据没有被加密
所以这部分代码可以这样写
def get_url(url):
headers = {
"Host": "www.dianping.com",
"Referer":f"{url}",
"User-Agent":ua.random,
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1"
}
r = requests.get(url = url,headers = headers,proxies = get_ip())
soup = BeautifulSoup(r.text)
page_num = int(soup.find_all("a",class_ = "PageLink")[-1].text)
url_list = [url + f"/p{i+1}" for i in range(page_num)]
return url_list
这部分代码不难理解构造请求——解析页面——提取页数——模拟URL,其中get_ip()必须要返回一个可以使用的ip,不论你是用免费的还是付费的代理,在这里不做详细讲解。
搞定URL之后,我们来到最关键的步骤,写一个函数,传进来一个页面返回该页的文字匹配字典,那么第一步就是把字体拿下来,下面四行代码即可搞定
css_url = "http://" + re.search(r"s3plus.meituan.net/(.*?)/svgtextcss/(.*?).css", page.text).group(0) #拿到css文件css_value = requests.get(css_url).text
addr_font = "http:" + re.search(r"address(.*?).woff", css_value).group(0).split(",")[-1][5:]
price_font = "http:" + re.search(r"shopNum(.*?).woff", css_value).group(0).split(",")[-1][5:]
简单来看一下这段代码,我们传入一个请求后得到的page后
“
第一行代码使用正则表达式提取字体所在的css链接
第二行代码使用requests请求css内容
最后两行代码使用正则提取woff字体文件所在URL
”
如果你传进去的页面是正常的,那么现在我们就有地址、均价字段的字体所在URL,下面就可以使用requests将这两个字体文件下载并保存在本地,代码如下
x = requests.get(addr_font).contentwith open("addr.woff","wb+") as f:
f.write(x)
x = requests.get(price_font).content
with open("price.woff","wb+") as f:
f.write(x)
现在工作目录下就有两个字体文件,之后就按照上一篇文章介绍的字体加密破解方法操作即可。所以这部分完整代码如下:
def get_font(page): """
接收请求后的页面
返回该页url字体woff文件对应的两个字典文件
"""python
css_url = "http://" + re.search(r"s3plus.meituan.net/(.*?)/svgtextcss/(.*?).css", page.text).group(0) #拿到css文件
css_value = requests.get(css_url).text
addr_font = "http:" + re.search(r"address(.*?).woff", css_value).group(0).split(",")[-1][5:]
price_font = "http:" + re.search(r"shopNum(.*?).woff", css_value).group(0).split(",")[-1][5:]
#下载字体保存到本地
x = requests.get(addr_font).content
with open("addr.woff","wb+") as f:
f.write(x)
x = requests.get(price_font).content
with open("price.woff","wb+") as f:
f.write(x)
#解析字体
font_addr = TTFont("addr.woff")
font1 = font_addr.getGlyphOrder()[2:]
font1 = [font1[i][-4:] for i in range(len(font1))]
font_price = TTFont("price.woff")
font2 = font_price.getGlyphOrder()[2:]
font2 = [font2[i][-4:] for i in range(len(font2))]
font3 = ["1", "2", "3", "4", "5", "6", "7", "8",
"9", "0", "店", "中", "美", "家", "馆", "小", "车", "大",
"市", "公", "酒", "行", "国", "品", "发", "电", "金", "心",
"业", "商", "司", "超", "生", "装", "园", "场", "食", "有",
"新", "限", "天", "面", "工", "服", "海", "华", "水", "房",
"饰", "城", "乐", "汽", "香", "部", "利", "子", "老", "艺",
"花", "专", "东", "肉", "菜", "学", "福", "饭", "人", "百",
"餐", "茶", "务", "通", "味", "所", "山", "区", "门", "药",
"银", "农", "龙", "停", "尚", "安", "广", "鑫", "一", "容",
"动", "南", "具", "源", "兴", "鲜", "记", "时", "机", "烤",
"文", "康", "信", "果", "阳", "理", "锅", "宝", "达", "地",
"儿", "衣", "特", "产", "西", "批", "坊", "州", "牛", "佳",
"化", "五", "米", "修", "爱", "北", "养", "卖", "建", "材",
"三", "会", "鸡", "室", "红", "站", "德", "王", "光", "名",
"丽", "油", "院", "堂", "烧", "江", "社", "合", "星", "货",
"型", "村", "自", "科", "快", "便", "日", "民", "营", "和",
"活", "童", "明", "器", "烟", "育", "宾", "精", "屋", "经",
"居", "庄", "石", "顺", "林", "尔", "县", "手", "厅", "销",
"用", "好", "客", "火", "雅", "盛", "体", "旅", "之", "鞋",
"辣", "作", "粉", "包", "楼", "校", "鱼", "平", "彩", "上",
"吧", "保", "永", "万", "物",
以上是 python爬虫遇到动态加密怎么办?爬取某点评网站内容 的全部内容, 来源链接: utcz.com/z/537666.html