大数据Hadoop之——数据采集存储到HDFS实战(Python版本)

要实现这个示例,必须先安装好hadoop和hive环境,环境部署可以参考我之前的文章:
大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
大数据Hadoop之——数据仓库Hive
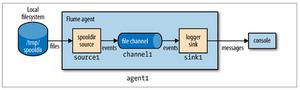
【流程图如下】
【示例代码如下】
#!/usr/bin/env python# -*- coding: utf-8 -*-
# @Author : liugp
# @File : Data2HDFS.py
"""
# pip install sasl可能安装不成功
pip install sasl
# 可以选择离线安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#sasl
pip install sasl-0.3.1-cp37-cp37m-win_amd64.whl
pip install thrift
pip install thrift-sasl
pip install pyhive
pip install hdfs
"""
from selenium import webdriver
from pyhive import hive
from hdfs import InsecureClient
class Data2HDFS:
def __init__(self):
# 第一个步,连接到hive
conn = hive.connect(host="192.168.0.113", port=11000, username="root", database="default")
# 第二步,建立一个游标
self.cursor = conn.cursor()
self.fs = InsecureClient(url="http://192.168.0.113:9870/", user="root", root="/")
"""
采集数据
"""
def collectData(self):
try:
driver = webdriver.Edge("../drivers/msedgedriver.exe")
# 爬取1-3页数据,可自行扩展
id = 1
local_path = "./data.txt"
with open(local_path, "w", encoding="utf-8") as f:
for i in range(1, 2):
url = "https://ac.qq.com/Comic/index/page/" + str(i)
driver.get(url)
# 模拟滚动
js = "return action=document.body.scrollHeight"
new_height = driver.execute_script(js)
for i in range(0, new_height, 10):
driver.execute_script("window.scrollTo(0, %s)" % (i))
list = driver.find_element_by_class_name("ret-search-list").find_elements_by_tag_name("li")
data = []
for item in list:
imgsrc = item.find_element_by_tag_name("img").get_attribute("src")
author = item.find_element_by_class_name("ret-works-author").text
leixing_spanlist = item.find_element_by_class_name("ret-works-tags").find_elements_by_tag_name(
"span")
leixing = leixing_spanlist[0].text + "," + leixing_spanlist[1].text
neirong = item.find_element_by_class_name("ret-works-decs").text
gengxin = item.find_element_by_class_name("mod-cover-list-mask").text
itemdata = {"id": str(id), "imgsrc": imgsrc, "author": author, "leixing": leixing, "neirong": neirong,
"gengxin": gengxin}
print(itemdata)
line = itemdata["id"] +"," + itemdata["imgsrc"] +"," + itemdata["author"] + "," + itemdata["leixing"] + "," + itemdata["neirong"] + itemdata["gengxin"] + "
"
f.write(line)
id+=1
data.append(itemdata)
# 上传文件,
d2f.uplodatLocalFile2HDFS(local_path)
except Exception as e:
print(e)
"""创建hive表"""
def createTable(self):
# 解决hive表中文乱码问题
"""
mysql -uroot -p
use hive数据库
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
commit;
:return:
"""
self.cursor.execute("CREATE TABLE IF NOT EXISTS default.datatable (
id INT COMMENT "ID",
imgsrc STRING COMMENT "img src",
author STRING COMMENT "author",
leixing STRING COMMENT "类型",
neirong STRING COMMENT "内容",
gengxin STRING COMMENT "更新"
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
COLLECTION ITEMS TERMINATED BY "-"
MAP KEYS TERMINATED BY ":"
LINES TERMINATED BY "
"")
"""
将本地文件推送到HDFS上
"""
def uplodatLocalFile2HDFS(self, local_path):
hdfs_path = "/tmp/test0508/"
self.fs.makedirs(hdfs_path)
# 如果文件存在就必须先删掉
self.fs.delete(hdfs_path + "/" + local_path)
print(hdfs_path, local_path)
self.fs.upload(hdfs_path, local_path)
"""
将HDFS上的文件load到hive表
"""
def data2Hive(self):
# 先清空表
self.cursor.execute("truncate table datatable")
# 加载数据,这里的路径就是HDFS上的文件路径
self.cursor.execute("load data inpath "/tmp/test0508/data.txt" into table datatable")
self.cursor.execute("select * from default.datatable")
print(self.cursor.fetchall())
if __name__ == "__main__":
d2f = Data2HDFS()
# 收集数据
d2f.collectData()
# 创建hive表
# d2f.createTable()
# 将数据存储到HDFS
d2f.data2Hive()
【温馨提示】hiveserver2的默认端口是10000,我是上面写的11000端口,是因为我配置文件里修改了,如果使用的是默认端口,记得修改成10000端口,还有就是修改成自己的host地址。这个只是一种实现方式,还有其它方式。
如果小伙伴有疑问的话,欢迎给我留言,后续会更新更多关于大数据的文章,请耐心等待~
以上是 大数据Hadoop之——数据采集存储到HDFS实战(Python版本) 的全部内容, 来源链接: utcz.com/z/536563.html