MySQL高性能索引策略和查询性能优化

前缀索引和索引选择性
有时候需要索引很长的字符,这会让索引变得大且慢。一个策略是模拟哈希索引。
通常可以索引开始的部分字符,这样可以大大解约索引空间,提高索引效率。但这样会降低索引的选择性。
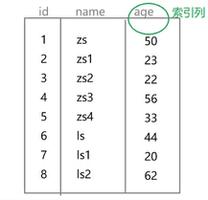
索引的选择性:不重复的索引值(也成为基数)和数据表的记录总数比值。索引的选择性越高则查询效率越高,因为选择性高的索引可以在查找时过滤更多的行。唯一索引的选择性为1,是选择性最好的。
前缀索引是一种能使索引更小更快的办法,但也有缺点:
MySQL无法使用ORDER BY和GROUP BY,也无法使用覆盖扫描。
聚簇索引
聚簇索引并不是一种单独的索引类型,是一种数据存储方式。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页。
聚簇:数据行和相邻的键值紧凑的存储在一起。
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。
如果没有这样的索引,会隐式定义一个主键作为聚簇索引。
聚簇索引的缺点
插入速度严重依赖插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,最好使用OPYIMIZE TABLE重新组织表。
基于聚簇索引的表在插入新行,或者主键被迁移时,可能会“页分裂”。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这是一次页分裂操作。页分裂会导致表占用更多的磁盘空间。
覆盖索引
通常大家会根据查询的WHERE条件创建合适的索引,设计优秀的索引也可以使用索引来直接获取列的数据。
如果索引的叶子结点已经包含要查询的数据,那还要什么必要再回表查询呢?如果一个索引包含所有需要查询的字段的值,我们称之为“覆盖索引”。
延迟关联
使用inner join做子查询。在查询的第一个阶段可以使用覆盖索引。虽然无法使用索引覆盖整个查询,但比完全无法利用索引覆盖的好。
冗余和重复索引
索引越大越多,插入数据越慢。
可以使用Percona Toolkit中的pt-duplicate-key-checker分析表结构找出冗余的索引。
单表建多少个索引才合适?
大表,主键有一个唯一索引。再有一到两个组合索引,最多三个索引足够用了。
索引数量不能超过4个/表。
一切服从应用需要。在一张表上创建多少索引,创建什么样的索引,并无一定之规。不能说一张表上有了 7个索引,就不能再创建第 8个索引了。
索引的多少取决于具体的业务场景。
在oltp中,表经常需要insert等,那么索引不能过多,一般超过3个就会对性能有影响。
在olap中如果表只是用于查询,那么建多个索引也无妨。
索引和锁
索引可以让查询锁定更少的行。但是,如果索引无法过滤掉无效的行,那么在InnoDB检索到数据并返回给服务器层以后,MySQL才能用那个用WHERE子句,这时已经无法避免锁定行了:InnoDB已经锁定了这些行。
mysql> select actor_id from sakila.actor where actor_id < 5 and actor_id <> 1 for update;
虽然这条查询返回的是2,3,4,但是实际上获取了1-4的排他锁。
话句话说,存储引擎的操作是“找小于5的记录”,服务器并没有告诉InnoDB可以过滤第1行的WHERE条件。注意到EXPLAIN的Extra列出现了“Using where”,这表示MySQL将存储引擎返回行以后再应用WHERE过滤条件。
using where 代表MYSQL服务器层在存储引擎层返回行以后再应用WHERE过滤条件
性能优化">查询性能优化
对于性能低下的查询,通过两个步骤来分析非常有效:
1、确认应用程序是否在检索大量超过需要的数据。这意味着访问了过多的行或者是过多的列。
2、确认MySQL服务器层是否在分析大量超过需要的数据行。
比如使用 * 来返回全部列,其实有些列是用不到的,应该精简,或者说重复查询相同改的数据,这应该把这种数据放到缓存里,下次查先从缓存取,热点数据每次取可以给加过期时间。
确认EXPLAIN中扫描的行数和访问类型
在EXPLAIN中的type列是访问类型,从全表扫描、索引扫描、范围扫描、唯一索引查询、常数引用(全索范唯),他们的查询速度是从慢到快。
Re
《高性能MySQL》
以上是 MySQL高性能索引策略和查询性能优化 的全部内容, 来源链接: utcz.com/z/536001.html