SQL如何在时间序列中根据字段变化分组

将排序(一般按时间排)后的数据按某字段变化分组统计,也就是分组字段值与上一行的值比较,如果相同则分到与上一行同组,不同时则创建一个新组。
这个问题用SQL来做很难!
SQL的集合是无序的,早期SQL没有相邻行引用的方法。SQL2003标准中加入了窗口函数,能引用相邻行,但分组仍然非常困难,需要用子查询人为造出分组序号。
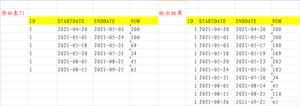
举个例子:查询人员某段时间所处城市,并列出起始和结束时间。现有数据库表footmark数据如下:
NAME
FOOTDATE
CITY
Tom
2020-01-02 08:30:00
Beijing
Tom
2020-01-03 08:30:00
Beijing
Tom
2020-01-04 13:30:05
Beijing
Tom
2020-01-04 16:36:00
Chengdu
Tom
2020-01-05 08:30:00
Chengdu
Tom
2020-01-06 12:30:00
Chengdu
Tom
2020-01-06 17:30:25
Beijing
Tom
2020-01-07 09:30:05
Beijing
Tom
2020-01-09 16:30:00
Beijing
…
…
…
要求最终分组统计的结果如下:
NAME
CITY
STARTDATE
ENDDATE
Tom
Beijing
2020-01-02 08:30:00
2020-01-04 13:30:05
Tom
Chengdu
2020-01-04 16:36:00
2020-01-06 12:30:00
Tom
Beijing
2020-01-06 17:30:25
2020-01-09 16:30:00
以Oracle为例,用SQL写出来是这样:
WITH A AS
( SELECT NAME, FOOTDATE, CITY,
CASE WHEN CITY=LAG(CITY) OVER (PARTITION BY NAME ORDER BY FOOTDATE) THEN 0 ELSE ROWNUM END FLAG
FROM FOOTMARK ORDER BY NAME, FOOTDATE),
B AS
( SELECT NAME, FOOTDATE, CITY,
MAX(FLAG) OVER (PARTITION BY NAME ORDER BY FOOTDATE) FLAG
FROM A),
C AS
( SELECT NAME, CITY, FLAG,
MIN(FOOTDATE) STARTDATE,
MAX(FOOTDATE) ENDDATE
FROM B
GROUP BY NAME, CITY, FLAG
ORDER BY NAME, FLAG )
SELECT NAME, CITY, STARTDATE, ENDDATE FROM C;
这里的FLAG就是人为造出的分组序号,这种SQL既难写又难懂。
对于这种按顺序分组,如果使用集算器的SPL语言就会简单很多,只需1行代码:
connect("mydb").query("SELECT * FROM FOOTMARK ORDER BY NAME,FOOTDATE").groups@o(NAME,CITY;min(FOOTDATE):STARTDATE,max(FOOTDATE):ENDDATE)
SPL基于有序集合实现,提供了按有序分组的选项@o,解决这个问题非常容易。
SPL提供了等值分组、有序分组、有序条件分组、序号分组、嵌套分组、大数据有序分组、大数据有序条件分组等多种分组方式,详情参考《分组子集》。
集算器 SPL 是解决 SQL 难题的专业脚本语言,它语法简单,符合自然思维,是天然分步、层次清晰的面向过程计算语言。它采用与数据库无关的统一语法,编写的算法可在数据库间无缝迁移。它是桌面级计算工具,即装即用,配置简单,调试功能完善,可设置断点、单步执行,每步执行结果都可查看。请参阅SQL 解题手
SPL也能很方便地嵌入到JAVA应用,可参考《Java 如何调用 SPL 脚本》。
具体使用方法可参考《如何使用集算器》。
以上是 SQL如何在时间序列中根据字段变化分组 的全部内容, 来源链接: utcz.com/z/533957.html