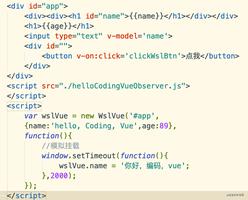
Redis学习笔记(三)字典

Redis的字典使用哈希表作为底层实现,一个哈希表中可以有多个哈希表节点,而每个哈希节点就保存在字典中的一个键值对。
redis字典所用的哈希表由disht结构定义。
typedef struct dictht{dictEntry
**table;//哈希表数组unsigned long size;//哈希表大小
unsigned long sizemask;//哈希表大小掩码,用于计算索引值 ,总是等于size -1
unsigned long used;//该哈希表已有节点数量
}
table 属性是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针,每个dictEntry结构保存着一个键值对。其他的属性不多说。
哈希表节点
哈希表节点使用dictEntry结构标识,每个dictEntry保存一个键值对。
typedef struct dictEntry{void *key;//键union{
void *val;
uint64_tu64"
int64_ts64"
} v;//值
struct dictEntry *next;//指向下个哈希节点,形成链表
} ductEntry;
*next 属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,解决键冲突的问题。所以,每一个哈希索引为一个单向链表。
Redis中的字典由dict结构表示:
typedef struct dict{dictType
*type;//类型特定函数void *orivdata;//私有数据
dictht ht[2];//哈希表
int trehashidx;//rehash 索引 ,当rehash不再进行时,值为-1
} dict;
Redis计算哈希值和索引值的方法:
hash = dict->type->hashFunction(key);index
= hash & dict->ht[x].sizemask;
解决键冲突:
当两个或两个一个数量的键被分配到了哈希表数组的同一个索引上面时,为我们称作这些键发生冲突。Redis的哈希表使用链地址法来解决冲突,每个哈希表节点的next指针构成了一个单向链表,以此来解决键冲突。
另外由于链表没有指向链表结尾的指针,为考虑速度,每次将新加的节点放到链表表头位置(复杂度为O(1))。
Rehash
随着哈希表保存的键增多或减少,为了让哈希表的负载因子维持在一个合理的范围内,程序会对哈希表的小小进行rehash(重新散列)。
1、为字典表的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作以及ht[0]包含的键值对数量
(1)如果执行扩展,ht[1] =第一个>=ht[0].used * 2 的2的n次方幂。
(2)如果收缩 ht[1] = 第一个>=ht[0].used 的2的n次方幂
2、h[0] 迁移至h[1]。
3、清空h[0],将h[1]设置为h[0],新建h[1]。
渐进式rehash
字典表同时使用ht[0],ht[1],ht[0]通过索引计数器分批量的迁移至ht[1],为解决ht[0]所持有的键值对量太大的问题。
不为别的,每天学一点,总会有收获。
说明:尊重作者知识产权,文中内容参考《Redis设计与实现》,仅在此做学习与大家分享。
以上是 Redis学习笔记(三)字典 的全部内容, 来源链接: utcz.com/z/533592.html