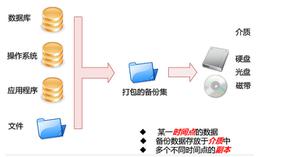
从简单实现mysql自动化备份说起

解决办法
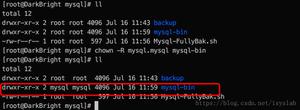
以 linux 上的 mysql 为例
- 手续编写备份脚本。
mysqldump -uname -p****** databasename > /databak/fileName.sql编写完 mysql 的备份脚本,需要手动测试一遍,看看脚本是否可行,如果可行,则可以进入下一步。然后可能需要设置一下备份的文件名、然后是否需要删除多日之前的备份等。
以下是个完整的例子,当然还能够继续完善,你可以根据自己的要求设置自己的规则。比如压缩、存储路径等等。
echo "===备份开始==="mysqldump -uname -p****** databasename | gzip > /databak/filename_$(date +%Y%m%d_%H%M%S).sql.gz
#删除10天前备份的数据
find /databak -mtime +7 -name "*.gz" -exec rm -rf {} ;
echo "===备份成功==="
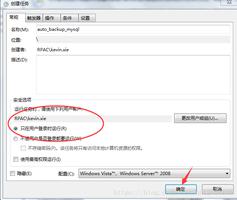
- 设置定时任务 linux 的定时任务设置时通过 crontab 组件来实现,
crontab -e#录入需要执行的任务
//每天凌晨1:30分执行一次
30 1 * * * /databak/databak.sh
crontab表达式的功能很强大,这个自己根据要求查API编写。
CRON表达式在线工具
注意:有些 linux 服务器版本中没有自带 crontab 组件,这个时候需要安装组件
#安装组件yum install -y vixie-cron
#启动组件
service crond start
- 测试
可以先将表达式设置为一分钟执行一次,同时通过 echo 加入输出日志,看任务是否定时执行,如果正常输出,则说明任务正常。
- 测试数据库完整性,将备份下拉的数据库还原,看看是否正常。
说明:winserver 的处理方式和 linux 原理是一样的,只是 linux
是通过 crontab 表达式,winserver 是通过任务执行计划来控制脚本执行。
总结
- 在系统架构师时,要提前规划服务器的架构,如果条件允许尽量用专用服务器,专用服务器的参数设置、备份机制都是比较合理的。当然规划过程中同样需要考虑个性化的需求。
- 整个过程需要熟悉定时任务基本原理, crontab 表达式的书写。这些都是比较底层的东西。我们在做一个简单的任务过程中需要慢慢的扩展自己的知识面。
- 从这件事的过程中,你可以发现技术的东西是相同的,例如 linux 和 winserver 的定时任务,又比如 crontab 表达式,linux 和 java(spring) 以及 java(quartz)大致也是类似的。又比如 mysql 的备份和其他数据也大致相同。所以在学习的路上要真正掌握这些东西,善于总结。
最后
如果觉得有帮助,关注公众号:科比可比克 ,我会定期分享一些工作中的一些想法。
以上是 从简单实现mysql自动化备份说起 的全部内容, 来源链接: utcz.com/z/533087.html