玩转Redis老板带你深入理解分布式锁

老板:我们每天不都在经历分布式锁吗,我来给你回忆回忆。
小猿:好勒,瓜子板凳已备好。
本文结构
- 为什么要使用分布式锁
- 分布式锁有哪些特点
- 分布式锁流行算法及其优缺点
- 基本算法
- relock算法
- token算法
- 数据库排它锁、ZooKeeper分布式锁、Google的Chubby分布式锁
- 总结
1、为什么要使用分布式锁
这个问题应该拆分成以下2个问题回答。
1.1、为什么使用锁
保证在同一时刻共享资源只能被一个客户端访问;
根据锁用途分为以下两种:
- 共享资源只允许一个客户端操作;
- 共享资源允许多个客户端操作;
1.1.1、仅允许一个客户端访问
共享资源的操作不具备幂等性。
常见于 数据的修改、删除操作;
在上面的例子中,
人物事件 系统含义
经理A-N
多个线程
码农小猿-调高空调温度
非幂等共享资源
秘书的允许
获取锁
1.1.2、允许多个客户端操作
主要应用场景是:共享资源的操作具有幂等性;
如 数据的查询。
既然都具有幂等性了,为什么还需要分布式锁呢,通常是为了效率或性能,避免重复操作(尤其是消耗资源的操作)。例如我们常见的缓存方案。
在上面的例子中,
人物事件 | 系统含义
---|---
经理A-N | 多个线程
码农小猿-整理昨天的资料 | 幂等共享资源
秘书的允许 | 获取锁
自己存资料 | 缓存
由于此处的资源是幂等的,通常会将这类资源做缓存,这就是常见的锁+缓存架构。
常适用于 获取较为消耗资源(时间、内存、CPU等)的幂等资源,如:
- 查询用户信息;
- 查询历史订单;
当然,如果资源仅在一段时间范围内具有幂等性,这时候,架构就应该升级了:
锁+缓存+缓存失效/失效重新获取/缓存定时更新。
1.2、锁为什么需要分布式的?
还是以上面的缓存方案为例,此处略作变化。
人物事件 系统含义
系统A、B
彼此独立的系统
码农小猿-调高空调温度
非幂等共享资源
李秘书的允许
获取锁
王秘书的允许
获取锁
李秘书、王秘书信息绝对互通
单一锁升级为分布式锁
2、高级分布式锁有哪些特点?
2.1、互斥性
- 在任意时刻,仅允许有一个客户端获得锁;
PS:如果多个客户端都能同时获得锁,那锁就没意义了,共享资源的安全性也就无法保证了。
老板:当我在会议室接待客户A时,其他客户只有等待,你需要等到我空闲了才能把其他人带到我办公室。
小猿:明白。
接待客户(非幂等共享资源);等到老板空闲(获取锁)。
2.2、可重入性
- 客户端A获得了锁,只要锁没有过期,客户端A可以继续获得该锁。
锁在我这里,我还要继续使用,其他人不准抢。
这种特性可以很好的支持【锁续约】功能。
例如:客户端A获取锁,锁释放时间为10S,即将到达10S时,客户端A未完成任务,需要再申请5S。若锁没有可重入性,客户端A将无法续约,导致锁可能被其他客户端抢走。
小猿:受教了,老板3分钟后你还有一场面试。
老板:小猿啊,难得你这么好学,我很欣慰,我们的交流时间延10分钟吧,其他会议延后。
2.3、高性能
- 获取锁的效率应该足够高;
- 总不能让业务阻塞在获取锁上面吧?
小猿:好的,我已在钉钉申请将会议延长10分钟了;
老板:嗯,我已经接受会议邀请了;
小猿:老板你真高效。
2.4、高可用
分布式、微服务环境下,必须保证服务的高可用,否则轻则影响其他业务模块,重则引发服务雪崩。
老板:我手机24小时开机,有会议时联系不上我也可以联系我秘书。
2.5、支持阻塞和非阻塞式锁
- 获取锁失败,是直接返回失败,还是一直阻塞知道获取成功?
不同的业务场景有不同的答案。
例如:
锁阻塞性 示例
非阻塞式
常见的工单系统,员工A、B同时想操作订单1(抢单)。当员工A获得锁并如愿操作订单1;员工B获取锁失败,不能一直阻塞,应该告知失败,让员工B去做其他事,否则员工B就光明正大上班划水了。
阻塞式
打电话给老板审核方案,老板在通话中(获取锁失败),此时需要每隔一段时间就给老板打电话,直到联系上老板才行。谁让老板下了死命令今天必须审核通过呢,呜呜呜。
2.6、解锁权限
- 客户端仅能释放(解锁)自己加的锁;
常见的解决方案是,给锁加随机数(或ThreadID)。
老板:小猿啊,给你讲了这么多,都明白了吗?
笼子里的鹦鹉:明白啦,明白啦。
老板:闭嘴,我问的是小猿,只有小猿自己有资格回答。
2.7、避免死锁
- 加锁方异常终止无法主动释放锁;
常规做法是 加锁时设置超时时间,如果未主动释放锁,则利用Redis的自动过期被动释放锁。
秘书破门而入:老板,你们10分钟的会议已经到点了,隔壁的李总已经等不及了;
老板:一不留神就忘记时间了,我得去见李总了。
小猿:老板,我们还没聊完呢,,,
2.8、异常处理
- 常见的异常情况有Redis宕机、时钟跳跃、网络故障等;
小猿:不管出现哪种情况,我获取锁都会失败啊,这可怎么办呢?
PS:这就复杂了,需要根据具体的业务场景分析。对于必须同步处理的业务,则必须失败告警,对于允许延迟处理的业务可以考虑记录失败信息待其他系统处理。
3、分布式锁流行算法
3.1、基本方案SETNX
基于Redis的SETNX指令完成锁的获取;
3.1.1、获取锁 SET lock:resource_name random_value NX PX 30000
lock:resource_name:资源名字,加锁对象的唯一标记;
random_value:通常存储加锁方的唯一标记,如“UUID+ThreadID”;
NX:key不存在才设置,即锁未被其他人加锁才能加锁;
PX:锁超时时间;
当然,此种加锁方式是不支持“锁重入性”的。
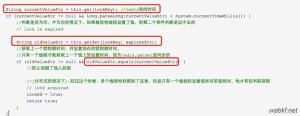
3.1.2、释放锁(LUA脚本)
checkValueThenDelete:检查解锁方是否是加锁方,是则允许解锁,否则不允许解锁;
伪代码是:
public class RedisTool { // 释放锁成功标记
private static final Long RELEASE_LOCK_SUCCESS = 1L;
/**
* 释放分布式锁
*
* @param jedis Redis客户端
* @param lockKey 锁标记
* @param lockValue 加锁方标记
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String lockValue) {
String script = "" +
"if redis.call("get", KEYS[1]) == ARGV[1] then" +
" return redis.call("del", KEYS[1]) " +
"else" +
" return 0 " +
"end";
// Collections.singletonList():用于只有一个元素的场景,减少内存分配
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(lockValue));
if (RELEASE_LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
3.2、Redlock算法
此算法由Redis作者antirez提出,作为一种分布式场景下的锁实现方案;
3.2.1、Redlock算法原理
【核心】大多数节点获取锁成功且锁依旧有效;
- Step1、获取当前时间(毫秒数);
- Step2、按序想N个Redis节点获取锁;
- Step2.1、设置随机字符串random_value;
- Step2.2、设置锁过期时间;
- Note1:获取锁需设置超时时间(防止某个节点不可用),且timeout应远小于锁有效时间(几十毫秒级);
- Note2:某节点获取锁失败后,立即向下一个节点获取锁(任何类型失败,包含该节点上的锁已被其他客户端持有);
- Step3、计算获取锁的总耗时totalTime;
- Step4、获取锁成功
- 获取锁成功:客户端从大多数节点(>=N/2+1)成功获取锁,且totalTime不超过锁的有效时间;
- 重新计算锁有效时间:最初锁有效时间减3.1计算的获取锁消耗的时间;
- Step5、获取锁失败
- 获取失败后应立即向【所有】客户端发起释放锁(Lua脚本);
- Step6、释放锁
- 业务完成后应立即向【所有】客户端发起释放锁(Lua脚本);
3.2.2、Redlock算法优点
- 可用性高,大多数节点正常即可;
- 单Redis节点的分布式锁在failover时锁失效问题不复存在;
3.2.3、Redlock算法问题点
- Redis节点崩溃将影响锁安全性
A、节点崩溃前锁未持久化,节点重启后锁将丢失;
B、Redis默认AOF持久化是每秒刷盘(fsync)一次,最坏情况将丢失1秒的数据;
- 需避免时钟跳跃;
A、管理员手动修改时钟;
B、使用[不会跳跃调整系统时钟]的ntpd(时钟同步)程序,对时钟修改通过多次微调实现;
- 客户端阻塞导致锁过期,导致共享资源不安全;
- 如果获取锁消耗时间较长,导致效时间很短,是否应该立即释放锁?多段才算短?
3.3、带fencing token的实现
分布式系统专家Martin Kleppmann讨论提出RedLock存在安全性问题;
3.3.1、神仙之战
Martin Kleppmann认为Redis作者antirez提出的RedLock算法有安全性问题,双方在网络上多轮探讨交锋。Martin指出RedLock算法的核心问题点如下:
- 锁过期或者网络延迟将导致锁冲突:
A、客户端A进程pause》锁过期》客户端B持有锁》客户端A恢复并向共享资源发起写请求;
B、网络延迟也会产生类似效果;
- RedLock安全性对系统时钟有强依赖;
3.3.2、fencing token算法原理
- fencing token是一个单调递增的数字,当客户端成功获取锁时随同锁一起返回给客户端;
- 客户端访问共享资源时带上token;
- 共享资源服务检查token,拒绝延迟到来的请求;
3.3.3、fencing token算法问题点
- 需要改造共享资源服务;
- 如果资源服务也是分布式,如何保证token在多个资源服务节点递增;
- 2个fencing token到达资源服务的顺序颠倒,服务检查将异常;
- 【antirez】既然存在fencing机制保持资源互斥访问,为什么还需要分布式锁且要求強安全性呢;
3.4、其他分布式锁
3.4.1、数据库排它锁
- 获取锁(select for update ,悲观锁);
- 处理业务逻辑;
- 释放锁(connection.commit());
- 注意:InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。So 必须给lock_name加索引。
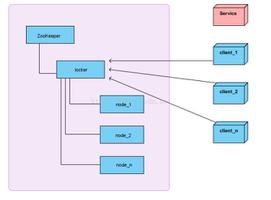
3.4.2、ZooKeeper分布式锁
- 客户端创建znode节点,创建成功则获取锁成功;
- 持有锁的客户端访问共享资源完成后删除znode;
- znode创建成ephemeral(znode特性),保证创建znode的客户端崩溃后,znode会被自动删除;
- 【问题】Zookeeper基于客户端与Zookeeper某台服务器维护Session,Session依赖定期心跳(heartbeat)维持。Zookeeper长时间收不到客户端心跳,就任务Session过期,这个Session所创建的所有ephemeral类型的znode节点都将被删除。
3.4.3、Google的Chubby分布式锁
- sequencer机制(类似fencing token)缓解延迟导致的问题;
- 锁持有者可随时请求一个sequencer;
- 客户端操作资源时将sequencer传给资源服务器;
- 资源服务器检查sequencer有效性;
- ①调用Chubby的API(CheckSequencer)检查;
- ②对比检查客户端、资源服务器当前观察到的sequencer(类似fencing token);
- ③lock-delay:允许客户端为持有锁指定一个lock-delay延迟时间,Chubby发现客户端失去联系时,在lock-delay时间内组织其他客户端获取锁;
4、总结
4.1、我们该使用怎样的分布式锁算法?
- 技术都是为业务服务的,避免选择“高大上”的炫技;
- 依托业务场景,尽可能选择最简单的做法;
- 最简单的分布式锁导致偶发性异常如何处理呢?
- 建议增加额外的机制甚至人工介入保证业务准确性,通常这部分成本低于复杂的分布式锁的开发、运维成本。
4.2、分布式锁的另类玩法
- “分而治之”经久不衰:
- 如果共享资源本身可以拆分,那就分开处理吧。
- 比如电商系统防止超卖,假设有10000个口罩将被秒杀,常规做法是一个锁控制所有资源。另类玩法就是将10000个口罩交由20个锁控制,整体性能瞬间提升几十倍。
- PS:此处超卖仅是举例,真实场景下的秒杀超卖有更加复杂的场景,慎重。
敬请关注后续《玩转Redis》系列文章。
>祝君好运!
Life is all about choices!
将来的你一定会感激现在拼命的自己!
【CSDN】【GitHub】【OSCHINA】【掘金】【语雀】【微信公众号】
以上是 玩转Redis老板带你深入理解分布式锁 的全部内容, 来源链接: utcz.com/z/532999.html