MySQL字段约束及多表查询讲解三

前言:mysql的字段约束是以后必不可免的,下面主要写了四个:主键约束用于唯一且不能为空;非空约束即不能为空可以重复;唯一约束即可以为空但必须唯一;外键约束是让表与表之间有一定的关联;当然如何使用还看下文,多表就不在这总结了。如果你对前面的知识有所遗忘或感兴趣----MySQL数据库表的模糊/多行/分组/排序/分页查询以及字mysql数据类型的讲解---讲解二
7 mysql的字段约束
7.1 主键约束
主键约束:如果为一个列添加了主键约束,那么这个列就是主键,主键的特点是唯一且不能为空。
主键的作用是: 唯一的标识一条表记录(就像身份证号用于唯一的表示一个人一样)
添加主键约束,例如将id设置为主键:
(通常一张表中会有一个主键)
create table stu( id int primary key auto_increment,
);
关于主键自增:
(1)设置了主键自增后, 再往表中插入记录,就可以不用给主键赋值,直接插入一个null值即可
(2)设置了主键自增后, 也可以为id赋值,只要赋的值与已有的id值不冲突即可! 在底层会将 auto_increment变量的值和插入的id值进行比较, 如果插入的值较大, 将会将插入的值加1后赋值给auto_increment变量。
7.2 非空约束
非空约束:如果为一个列添加了非空约束,那么这个列的值就不能为空,但可以重复。
添加非空约束,例如为password添加非空约束:
create table user( password varchar(50) not null,
...
);
7.3 唯一约束
唯一约束:如果为一个列添加了唯一约束,那么这个列的值就必须是唯一的(即不能重复),但可以为空。
添加唯一约束,例如为username添加唯一约束及非空约束:
create table user( username varchar(50) unique not null,
...
);
7.4 外键约束
设置外键和不设置外键有什么区别?
如果不设置外键,两张表之间的对应关系就只有开发人员自己知道,数据库本身是不知道的,数据库不知道两张表存在对应关系,就不会帮我们维护这段关系。只有开发人员自己来维护。
如果设置了外键,就等同于通知数据库两张表(dept和emp)存在一定的对应关系(emp表中的dept_id列要严格参考dept表中的主键(id)),数据库知道并且会帮我们维护这段关系。
create table dept( id int,
name varchar(50)
...
);
create table emp(
id int,
name varchar(50),
dept_id int,
foreign key(dept_id) references dept(id)
);
8 表关系
常见的表关系有:
一对多(多对一)、一对一、多对多
总结:
一对多(多对一):在多的一方添加列(员工和部门)保存一的一方的主键作为外键,从而保存两张表之间的对应关系
一对一:在任意一张表中添加列保存另一方的主键作为外键,从而保存两张表之间的对应关系
多对多:不能在任意一方添加列保存另一方的主键。此时可以创建一张第三方的表,分别保存两张表的主键作为外键,从而保存多对多的对应关系。
多表查询
将db30库中的数据导入数据库
-- ------------------------------------- 创建db30库、dept表、emp表并插入记录
-- -----------------------------------
-- 删除db30库(如果存在)
drop database if exists db30;
-- 重新创建db30库
create database db30 charset utf8;
-- 选择db30库
use db30;
-- 删除部门表, 如果存在
drop table if exists dept;
-- 重新创建部门表, 要求id, name字段
create table dept(
id int primary key auto_increment, -- 部门编号
name varchar(20) -- 部门名称
);
-- 往部门表中插入记录
insert into dept values(null, "财务部");
insert into dept values(null, "人事部");
insert into dept values(null, "科技部");
insert into dept values(null, "销售部");
-- 删除员工表, 如果存在
drop table if exists emp;
-- 创建员工表(员工编号、员工姓名、所在部门编号)
create table emp(
id int primary key auto_increment, -- 员工编号
name varchar(20), -- 员工姓名
dept_id int -- 部门编号
);
-- 往员工表中插入记录
insert into emp values(null, "张三", 1);
insert into emp values(null, "李四", 2);
insert into emp values(null, "老王", 3);
insert into emp values(null, "赵六", 5);
9.1 连接查询
--42.查询部门和部门对应的员工信息
select * from dept, emp;
上面的查询叫做笛卡尔积查询:如果同时查询两张表,其中一张表有m条数据,另外一张表有n条数据,笛卡尔积查询的结果是 m*n 条
笛卡尔积查询的结果中有大量错误数据,我们通常不会直接使用。
但可以通过where子句、条件剔除错误数据,保留正确数据。
正确代码:
select * from dept, emp where dept.id=emp.dept_id;9.2左外连接查询
-- 43.查询所有部门和部门下的员工,如果部门下没有员工,员工显示为nullselect * from dept left join emp on dept.id=emp.dept_id;
左外连接查询:会将左边表中的所有记录都查询出来,右边表只显示和左边表对应的数据,如果左边表在右边没有对应数据,可以对应null值。
-- 也可以使用右外连接实现上面的查询select * from emp right join dept on emp.dept_id=dept.id;
9.3右外连接查询
-- 44.查询部门和所有员工,如果员工没有所属部门,部门显示为nullselect * from dept right join emp on dept.id=emp.dept_id;
右外连接查询:会将右边表中的所有记录都查询出来,左边表只显示和右边表对应的数据,如果右边表在左边没有对应数据,可以对应null值。
-- 也可以使用左外连接实现上面的查询:select * from emp left join dept on dept.id=emp.dept_id;
-- 查询所有的部门和对应的所有员工(既要显示所有部门,也要显示所有员工)
select * from emp full join dept on dept.id=emp.dept_id;
mysql不支持全外连接查询,但我们可以通过union(联合)查询来模拟:
select * from dept left join emp on dept.id=emp.dept_id
union
select * from dept right join emp on dept.id=emp.dept_id;
9.4子查询
子查询:将一条SQL语句的执行结果,作为另外一条SQL语句的条件进行查询,这样的查询就叫做子查询。
将对db40库导入数据库中
-- ------------------------------------- 创建db40库、dept表、emp表并插入记录
-- -----------------------------------
-- 删除db40库(如果存在)
drop database if exists db40;
-- 重新创建db40库
create database db40 charset utf8;
-- 选择db40库
use db40;
-- 创建部门表
create table dept( -- 创建部门表
id int primary key, -- 部门编号
name varchar(50), -- 部门名称
loc varchar(50) -- 部门位置
);
-- 创建员工表
create table emp( -- 创建员工表
id int primary key, -- 员工编号
name varchar(50), -- 员工姓名
job varchar(50), -- 职位
topid int, -- 直属上级
hdate date, -- 受雇日期
sal int, -- 薪资
bonus int, -- 奖金
dept_id int, -- 所在部门编号
foreign key(dept_id) references dept(id)
);
-- 往部门表中插入记录
insert into dept values ("10", "财务部", "北京");
insert into dept values ("20", "设计部", "上海");
insert into dept values ("30", "技术部", "广州");
insert into dept values ("40", "销售部", "深圳");
-- 往员工表中插入记录
insert into emp values ("1001", "王富国", "办事员", "1007", "1980-12-17", "800", 500, "20");
insert into emp values ("1003", "齐帅", "分析员", "1011", "1981-02-20", "1900", "300", "10");
insert into emp values ("1005", "王浪", "推销员", "1011", "1981-02-22", "2450", "600", "10");
insert into emp values ("1007", "冯松", "经理", "1017", "1981-04-02", "3675", 700, "20");
insert into emp values ("1009", "李政", "推销员", "1011", "1981-09-28", "1250", "1400", "10");
insert into emp values ("1011", "陈要", "经理", "1017", "1981-05-01", "3450", 400, "10");
insert into emp values ("1013", "张勇", "办事员", "1011", "1981-06-09", "1250", 800, "10");
insert into emp values ("1015", "程德祖", "分析员", "1007", "1987-04-19", "3000", 1000, "20");
insert into emp values ("1017", "韩悦", "董事长", null, "1981-11-17", "5000", null, null);
insert into emp values ("1019", "刘笑", "推销员", "1011", "1981-09-08", "1500", 500, "10");
insert into emp values ("1021", "范冰冰", "办事员", "1007", "1987-05-23", "1100", 1000, "20");
insert into emp values ("1023", "赵子龙", "经理", "1017", "1981-12-03", "950", null, "30");
insert into emp values ("1025", "雪雅", "分析员", "1023", "1981-12-03", "3000", 600, "30");
insert into emp values ("1027", "张大胆", "办事员", "1023", "1982-01-23", "1300", 400, "30");
-- 45.列出薪资比"刘笑"薪资高的所有员工,显示姓名、薪资
-- 查询"刘笑"的薪资select sal from emp where name="刘笑";
-- 查询薪资比"刘笑"薪资高的所有员工
select name, sal from emp
where sal > (select sal from emp where name="刘笑");
-- 46.列出与"雪雅"从事相同职位的所有员工,显示姓名、职位。
-- 求出雪雅的职位select job from emp where name="雪雅";
-- 求与"雪雅"从事相同职位的员工
select name, job from emp
where job=(select job from emp where name="雪雅");
-- 47.列出薪资比"技术部"部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
-- 求技术部门的最高薪资select max(sal) from emp where dept_id=30;
-- 连接查询员工表和部门表
select emp.name,sal,dept.name from emp, dept
where emp.dept_id=dept.id
and sal>(select max(sal) from emp where dept_id=30); -- 不准确
---------------------------------------------------------
select emp.name,sal,dept.name from emp left join dept
on emp.dept_id=dept.id
where sal>(select max(sal) from emp where dept_id=30);
9.5 多表查询
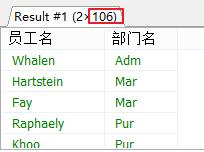
-- 48.列出在"设计部"任职的员工,假定不知道"设计部"的部门编号, 显示部门名称,员工名称
-- 关联查询两张表select dept.name, emp.name from emp,dept
where dept.id=emp.dept_id;
-- 求出在培优部的员工
select dept.name, emp.name from emp,dept
where dept.id=emp.dept_id and dept.name="设计部";
-- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
/* 将emp表既看作员工表, 也看做上级表 e1(员工表) e2(上级表) 查询的列: e1.name, e2.id, e2.name
查询的表: emp e1,emp e2
连接条件: e1.topid=e2.id
*/
select e1.name, e2.id, e2.name
from emp e1,emp e2
where e1.topid=e2.id;
select e1.name, e2.id, e2.name
from emp e1 left join emp e2
on e1.topid=e2.id; -- 左外,查询所有员工及对应上级
-- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
-- 求出每种职位的最低薪资分别是多少select job,min(sal) from emp group by job;
-- 求出最低薪资大于1500的职位
select job,min(sal) from emp group by job having min(sal)>1500;
-- 在分组之前过滤使用where,在分组之后过滤使用having
-- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
-- 对员工表按照部门分组(部门相同的员工为一组)select dept_id 部门编号, count(*) 部门人数, avg(sal) 平均薪资
from emp group by dept_id;
-- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
-- 连接查询部门表和员工表select d.id, d.name, d.loc from dept d, emp e
where emp.dept_id=dept.id;
-- 按照部门进行分组,统计每个部门的人数
select d.id, d.name, d.loc, count(*)
from dept d, emp e
where e.dept_id=d.id
group by d.name;
-- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
/*查询的列:e1.id, e1.name, d.name
查询的表:emp e1(员工表),dept d(部门表) emp e2(上级表)
连接条件:e1.dept_id=d.id, e1.topid=e2.id
筛选条件:e1.hdate<e2.hdate
*/
select e1.id, e1.name, d.name
from emp e1,dept d,emp e2
where e1.dept_id=d.id and e1.topid=e2.id
and e1.hdate<e2.hdate;
-- 54.列出每个部门薪资最高的员工信息,显示部门编号、最高薪资、员工姓名
-- 求出每个部门的最高薪资,显示部门编号和最高薪资select dept_id,max(sal) from emp group by dept_id;
-- 将上面的查询结果作为一张表 和 emp 表进行连接查询
select e.dept_id dept_id, t.max_sal sal, e.name name
from emp e, (select dept_id,max(sal) max_sal from emp group by dept_id) t
where e.sal=t.max_sal and e.dept_id=t.dept_id;
-- 查询没有部门的员工的最高信息,显示部门编号,最高薪资,员工姓名
select dept_id,sal,name from emp where
sal=(select max(sal) from emp where dept_id is null)
and dept_id is null;
select e.dept_id dept_id, t.max_sal sal, e.name name
from emp e, (select dept_id,max(sal) max_sal from emp group by dept_id) t
where e.sal=t.max_sal and e.dept_id=t.dept_id
union
select dept_id,sal,name from emp where
sal=(select max(sal) from emp where dept_id is null)
and dept_id is null;
在sql语句中where和having的区别
相同点:where和having都用于对表中的记录进行筛选过滤
不同点:
(1)where是在分组之前,对表中的记录进行筛选过滤。并且where中不能使用列别名(但可以使用表别名),也不能使用多行函数(count/max/min/sum/avg)
(2)having是在分组之后,对表中的记录进行筛选过滤,having中可以使用列别名、表别名、多行函数。
(3)通常情况,having可以替代where,但反过来不行(但有些情况下不能替换:在分组之前需要对记录进行过滤,分组之后还需要对数据进行过滤,此时不能使用having替换where)
到此对数据库的详细讲解也通过三篇博文,讲解清楚了,如果有问题,可以在评论区找我!!!
以上是 MySQL字段约束及多表查询讲解三 的全部内容, 来源链接: utcz.com/z/532787.html