浅谈Mysql多表连接查询的执行细节
先构建本篇博客的案列演示表:
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
create table b(b1 int primary key, b2 int); --有主键索引
create table d(d1 int, d2 int); --没有索引
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
insert into d values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
驱动表如何选择?
驱动表的概念是指多表关联查询时,第一个被处理的表,使用此表的记录去关联其他表。驱动表的确定很关键,会直接影响多表连接的关联顺序,也决定了后续关联时的查询性能。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。改变驱动表就意味着改变连接顺序,只有在不会改变最终输出结果的前提下才可以对驱动表做优化选择。在外连接情况下,很多时候改变驱动表会对输出结果有影响,比如left join的左边表和right join的右边表,驱动表选择join的左边或者右边最终输出结果很有可能会不同。
用结果集来选择驱动表,那结果集是什么?如何计算结果集?mysql在选择前会根据where里的每个表的筛选条件,相应的对每个可作为驱动表的表做个结果记录预估,预估出每个表的返回记录行数,同时再根据select里查询的字段的字节大小总和做乘积:
每行查询字节数 * 预估的行数 = 预估结果集
通过where预估结果行数,遵循以下规则:
- 如果where里没有相应表的筛选条件,无论on里是否有相关条件,默认为全表
- 如果where里有筛选条件,但是不能使用索引来筛选,那么默认为全表
- 如果where里有筛选条件,而且可以使用索引,那么会根据索引来预估返回的记录行数
我们以上述创建的表为基础,用如下sql作为案列来演示:
select a.*,c.c2 from a join c on a.a2=c.c2 where a.a1>5 and c.c1>5;
通过explain查看其执行计划:

explain显示结果里排在第一行的就是驱动表,此时表c为驱动表。
如果将sql修改一下,将select 里的条件c.c2 修改为 c.* :
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>5 and c.c1>5;
通过explain查看其执行计划:

此时驱动表还是c,按理来说 c.* 的数据量肯定是比 a.*大的,似乎结果集大小的规则在这里没有起作用。
此情形下如果用a作为驱动表,通过索引c2关联到c表,那么还需要再回表查询一次,因为仅仅通过c2获取不到c.*的数据,还需要通过c2上的主键c1再查询一次。而上一个sql查询的是c2,不需要额外查询。同时因为a表只有两个字段,通过a2索引能够直接获得a.*,不需要额外查询。
综上所述,虽然使用c表来驱动,结果集大一些,但是能够减少一次额外的回表查询,所以mysql认为使用c表作为驱动来效率更高。
结果集是作为选择驱动表的一个主要因素,但不是唯一因素。
两表关联查询的内在逻辑是怎样的?
mysql表与表之间的关联查询使用Nested-Loop join算法,顾名思义就是嵌套循环连接,但是根据场景不同可能有不同的变种:比如Index Nested-Loop join,Simple Nested-Loop join,Block Nested-Loop join, Betched Key Access join等。
- 在
使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法; - 在
未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法;
我们先来看有索引的情形,使用的是博客刚开始时建立的表,sql如下:
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>4;
通过explain查看其执行计划:

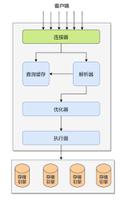
首先根据第一步的逻辑来确定驱动表a,然后通过a.a1>4,a.来查询一条记录a1=5,将此记录的c2关联到c表,取得c2索引上的主键c1,然后用c1的值再去聚集索引上查询c.*,组成一条完整的结果,放入net buffer,然后再根据条件a.a1>4,a. 取下一条记录,循环此过程。过程图如下:
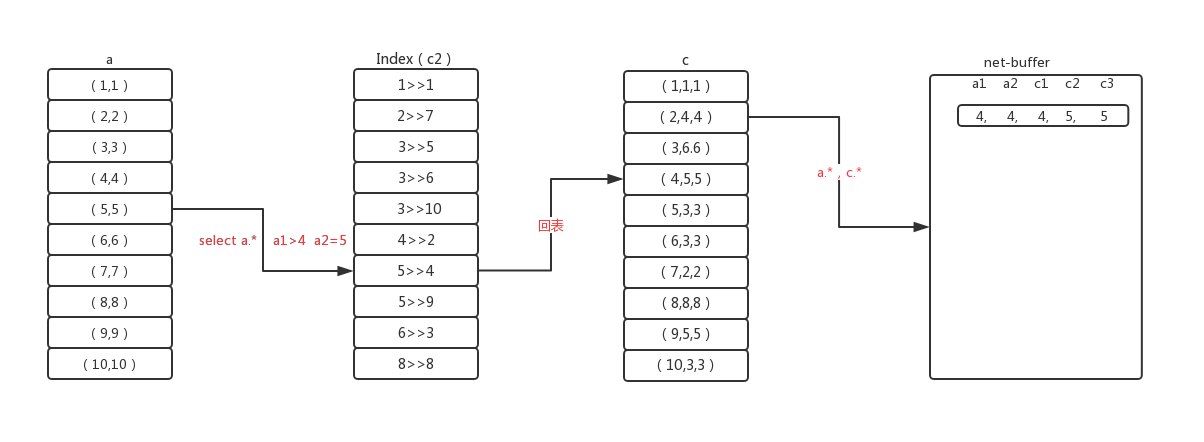
通过索引关联被驱动表,使用的是Index Nested-Loop join算法,不会使用msyql的join buffer。根据驱动表的筛选条件逐条地和被驱动表的索引做关联,每关联到一条符合的记录,放入net-buffer中,然后继续关联。此缓存区由net_buffer_length参数控制,最小4k,最大16M,默认是1M。 如果net-buffer满了,将其发送给client,清空net-buffer,继续上一过程。
通过上述流程知道,驱动表的每条记录在关联被驱动表时,如果需要用到索引不包含的数据时,就需要回表一次,去聚集索引上查询记录,这是一个随机查询的过程。每条记录就是一次随机查询,性能不是非常高。mysql对这种情况有选择的做了优化,将这种随机查询转换为顺序查询,执行过程如下图:
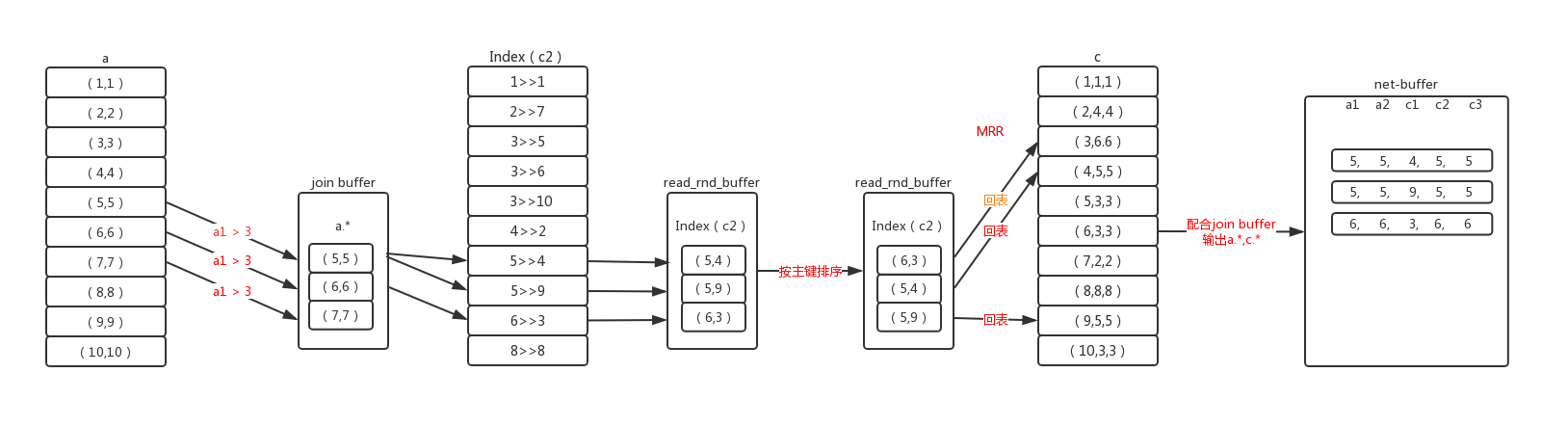
此时会使用Batched Key Access join 算法,顾名思义,就是批量的key访问连接。
逐条的根据where条件查询驱动表,将符合记录的数据行放入join buffer,然后根据关联的索引获取被驱动表的索引记录,存入read_rnd_buffer。join buffer和read_rnd_buffer都有大小限制,无论哪个到达上限都会停止此批次的数据处理,等处理完清空数据再执行下一批次。也就是驱动表符合条件的数据可能不能够一次处理完,而要分批次处理。
当达到批次上限后,对read_rnd_buffer里的被驱动表的索引按主键做递增排序,这样在回表查询时就能够做到近似顺序查询:
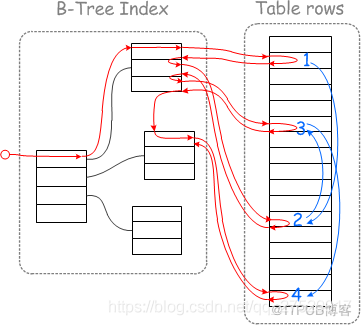
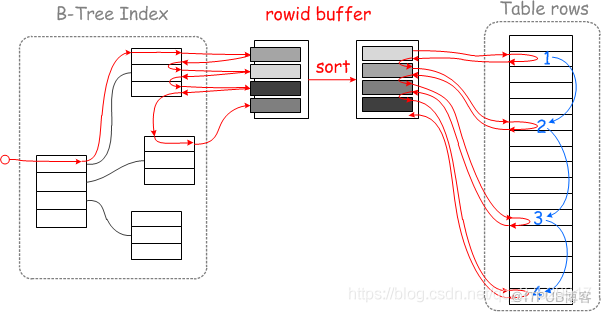
如上图,左边是未排序前的随机查询示意图,右边是排序后使用MRR( Multi-Range Read)的顺序查询示意图。
因为mysql的InnoDB引擎的数据是按聚集索引来排列的,当对非聚集索引按照主键来排序后,再用主键去查询就使得随机查询变为顺序查询,而计算机的顺序查询有预读机制,在读取一页数据时,会向后额外多读取最多1M数据。此时顺序读取就能排上用场。
BKA算法在需要对被驱动表回表的情况下能够优化执行逻辑,如果不需要会表,那么自然不需要BKA算法。
如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前先设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
前两个参数的作用是要启用 MRR(Multi-Range Read)。这么做的原因是,BKA 算法的优化需要依赖于MRR,官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。)
最后再用explain查看开启参数后的执行计划:

上述都是有索引关联被驱动表的情况,接下来我们看看没有索引关联被驱动表的情况。
没有使用索引关联,那么最简单的Simple Nested-Loop join,就是根据where条件,从驱动表取一条数据,然后全表扫面被驱动表,将符合条件的记录放入最终结果集中。这样驱动表的每条记录都伴随着被驱动表的一次全表扫描,这就是Simple Nested-Loop join。
当然mysql没有直接使用Simple Nested-Loop join,而是对其做了一个优化,不是逐条的获取驱动表的数据,而是多条的获取,也就是一块一块的获取,取名叫Block Nested-Loop join。每次取一批数据,上限是达到join buffer的大小,然后全表扫面被驱动表,每条数据和join buffer里的所有行做匹配,匹配上放入最终结果集中。这样就极大的减少了扫描被驱动表的次数。
BNL(Block Nested-Loop join) 和 BKA(Batched Key Access join)的流程有点类似, 但是没有read_rnd_buffer这个步骤。
示例sql如下:
select a.*, d.* from a join d on a.a2=d.d2 where a.a1>7;
用explain查看其执行计划:

多表连接如何执行?是先两表连接的结果集然后关联第三张表,还是一条记录贯穿全局?
其实看连接算法的名称:Nested-Loop join,嵌套循环连接,就知道是多表嵌套的循环连接,而不是先两表关联得出结果,然后再依次关联的形式,其形式类似于下面这样:
for row1 in table1 filtered by where{
for row2 in table2 associated by table1.index1 filtered by where{
for row3 in table3 associated by table2.index2 filtered by where{
put into net-buffer then send to client;
}
}
}
对于不同的join方式,有下列情况:
Index Nested-Loop join:
sql如下:
select a.*,b.*,c.* from a join c on a.a2=c.c2 join b on c.c2=b.b2 where b.b1>4;
通过explain查看其执行计划:

其内部执行流程如下:
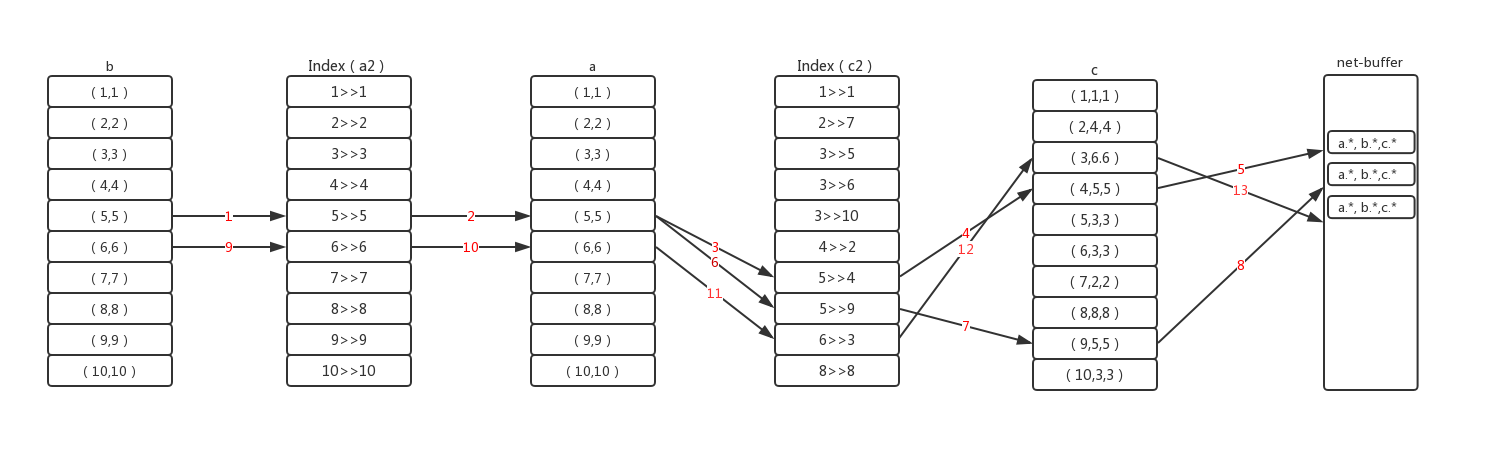
执行前mysql执行器会确定好各个表的关联顺序。首先通过where条件,筛选驱动表b的第一条记录b5,然后将用此记录的关联字段b2与第二张表a的索引a2做关联,通过Btree定位索引位置,匹配的索引可能不止一条。当匹配上一条,查看where里是否有a2的过滤条件且条件是否需要索引之外的数据,如果要则回表,用a2索引上的主键去查询数据,然后做判断。通过则用join后的信息再用同样的方式来关联第三章表c。
Block Nested-Loop join 和 Batched Key Access join : 这两个关联算法和Index Nested-Loop join算法类似,不过因为他们能使用join buffer,所以他们可以每次从驱动表筛选一批数据,而不是一条。同时每个join关键字就对应着一个join buffer,也就是驱动表和第二张表用一个join buffer,得到的块结果集与第三章表用一个join buffer。
本篇博客主要就是讲述上述三个问题,如何确定驱动表,两表关联的执行细节,多表关联的执行流程。
到此这篇关于浅谈Mysql多表连接查询的执行细节的文章就介绍到这了,更多相关Mysql多表连接查询内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 浅谈Mysql多表连接查询的执行细节 的全部内容, 来源链接: utcz.com/p/231175.html