Hbase架构剖析

HBase隶属于hadoop生态系统,它参考了谷歌的BigTable建模,实现的编程语言为 Java, 建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它仅能通过主键(row key)和主键的range来检索数据,主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。Hbase数据库中的表一般有这样的特点:
- 大: 一个表可以有上亿行,上百万列
- 面向列: 面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏: 对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
目录:
- 系统架构
- 数据模型
- RegionServer
- nameSpace
- HBase寻址
- write
- Compaction
- splite
- read
系统架构:
HBase采用Master/Slave架构搭建集群,由HMaster节点、HRegionServer节点、ZooKeeper集群组成,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NN、DN等,总体结构如下(注意:在hadoop(四): 本地 hbase 集群配置 Azure Blob Storage 介绍过,也可以将底层的存储配置为 Azure Blob Storage 或 Amazon Web Services),图A较清楚表达各组件之间的访问及内部实现逻辑,图B更直观表达hbase 与 hadoop hdfs 部署结构及 hadoop NN 和 HMaster 的 SPOF 解决方案
架构图A
架构图B
- Client的主要功能:
- 使用HBase的RPC机制与HMaster和HRegionServer进行通信
- 对于管理类操作,Client与HMaster进行RPC
- 对于数据读写类操作,Client与HRegionServer进行RPC
- Zookeeper功能:
- 通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- 实时监控Region server的上线和下线信息,并实时通知给Master
- 存贮所有Region的寻址入口和HBase的schema和table元数据
- Zookeeper的引入实现HMaster主从节点的failover
详细工作原理如下图:
- 在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点失效,则HMaster会收到通知,并做相应的处理
- HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机
- 在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点,如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点
- HMaster功能:
- 管理HRegionServer,实现其负载均衡
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上
- 监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)
- 处理schema更新请求 (创建、删除、修改Table的定义), 如下图:
- HRegionServer功能:
- Region server维护Master分配给它的region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
- 小结:
- client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低
- HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化
数据模型:
- Table: 与传统关系型数据库类似,HBase以表(Table)的方式组织数据,应用程序将数据存入HBase表中
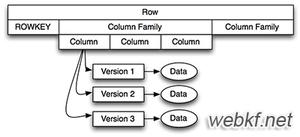
- Row: HBase表中的行通过 RowKey 进行唯一标识,不论是数字还是字符串,最终都会转换成字段数据进行存储;HBase表中的行是按RowKey字典顺序排列
- Column Family: HBase表由行和列共同组织,同时引入列族的概念,它将一列或多列组织在一起,HBase的列必须属于某一个列族,在创建表时只需指定表名和至少一个列族
- Cell: 行和列的交叉点称为单元格,单元格的内容就是列的值,以二进制形式存储,同时它是版本化的
- version: 每个cell的值可保存数据的多个版本(到底支持几个版本可在建表时指定),按时间顺序倒序排列,时间戳是64位的整数,可在写入数据时赋值,也可由RegionServer自动赋值
- 注意:
- HBase没有数据类型,任何列值都被转换成字符串进行存储
- 与关系型数据库在创建表时需明确包含的列及类型不同,HBase表的每一行可以有不同的列
- 相同RowKey的插入操作被认为是同一行的操作。即相同RowKey的二次写入操作,第二次可被可为是对该行某些列的更新操作
- 列由列族和列名连接而成, 分隔符是冒号,如 d:Name (d: 列族名, Name: 列名)
- 以一个示例来说明关系型数据表和HBase表各自的解决方案(示例:博文及作者),关系型数据库表结构设计及数据如下图:
表结构设计
示例数据
用HBase设计表结构如下图:
存储示例数据如下:
- 小结:
- HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描
- 在表创建时只需声明表名和至少一个列族名,每个Column Family为一个存储单元,在下节物理模型会详细介绍
- 在上例中设计了一个HBase表blog,该表有两个列族:article和author,但在实际应用中强烈建议使用单列族
- Column不用创建表时定义即可以动态新增,同一Column Family的Columns会群聚在一个存储单元上,并依Column key排序,因此设计时应将具有相同I/O特性的Column设计在一个Column Family上以提高性能。注意:这个列是可以增加和删除的,这和我们的传统数据库很大的区别。所以他适合非结构化数据
- HBase通过row和column确定一份数据,这份数据的值可能有多个版本,不同版本的值按照时间倒序排序,即最新的数据排在最前面,查询时默认返回最新版本。如上例中row key=1的author:nickname值有两个版本,分别为1317180070811对应的“一叶渡江”和1317180718830对应的“yedu”(对应到实际业务可以理解为在某时刻修改了nickname为yedu,但旧值仍然存在)。Timestamp默认为系统当前时间(精确到毫秒),也可以在写入数据时指定该值
- 每个单元格值通过4个键唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value, 例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’ 1317180718830’}索引到的唯一值是“yedu”
- 存储类型:
- TableName 是字符串
- RowKey 和 ColumnName 是二进制值(Java 类型 byte[])
- Timestamp 是一个 64 位整数(Java 类型 long)
- value 是一个字节数组(Java类型 byte[])
RegionServer:
- HRegionServer一般和DN在同一台机器上运行,实现数据的本地性,如图B。HRegionServer包含多个HRegion,由WAL(HLog)、BlockCache、MemStore、HFile组成,如图A,其中图A是0.94-的架构图,图B是0.96+的新架构图
图A
图B
- WAL(Write Ahead Log):它是HDFS上的一个文件,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中
- 采用这种模式,可以保证HRegionServer宕机后,依然可以从该Log文件中读取数据,Replay所有的操作,来保证数据的一致性
- 一个HRegionServer只有一个WAL实例,即一个HRegionServer的所有WAL写都是串行,这当然会引起性能问题,在HBase 1.0之后,通过HBASE-5699实现了多个WAL并行写(MultiWAL),该实现采用HDFS的多个管道写,以单个HRegion为单位
- Log文件会定期Roll出新的文件而删除旧的文件(那些已持久化到HFile中的Log可以删除)。WAL文件存储在/hbase/WALs/${HRegionServer_Name}的目录中
- BlockCache(图B):是一个读缓存,将数据预读取到内存中,以提升读的性能
- HBase中提供两种BlockCache的实现:默认on-heap LruBlockCache和BucketCache(通常是off-heap)。通常BucketCache的性能要差于LruBlockCache,然而由于GC的影响,LruBlockCache的延迟会变的不稳定,而BucketCache由于是自己管理BlockCache,而不需要GC,因而它的延迟通常比较稳定,这也是有些时候需要选用BucketCache的原因
- HRegion:是一个Table中的一个Region在一个HRegionServer中的表达,是Hbase中分布式存储和负载均衡的最小单元
- 一个Table拥有一个或多个Region,分布在一台或多台HRegionServer上
- 一台HRegionServer包含多个HRegion,可以属于不同的Table
- 见图A,HRegion由多个Store(HStore)构成,每个HStore对应了一个Table在这个HRegion中的一个Column Family,即每个Column Family就是一个集中的存储单元
- HStore是HBase中存储的核心,它实现了读写HDFS功能,一个HStore由一个MemStore 和0个或多个StoreFile组成
- MemStore:是一个写缓存(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,会 写入MemStore中,由MemStore根据一定的算法将数据Flush到底层HDFS文件中(HFile),通常每个HRegion中的每个 Column Family有一个自己的MemStore
- HFile(StoreFile): 用于存储HBase的数据(Cell/KeyValue)。在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列
- 小结:
- Table中的所有行都按照row key的字典序排列,Table 在行的方向上分割为多个Hregion,如下图1
- region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion,如下图2
图1
图2
3、HRegion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的,如下图
4、HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile组成,如下图,说明:StoreFile以HFile格式保存在HDFS上
nameSpace:
- 在HBase中,namespace命名空间指对一组表的逻辑分组,类似RDBMS中的database,方便对表在业务上划分。
- Apache HBase从0.98.0, 0.95.2两个版本开始支持namespace级别的授权操作,HBase全局管理员可以创建、修改和回收namespace的授权
- HBase系统默认定义了两个缺省的namespace,见如下图的目录结构:
- hbase:系统内建表,包括namespace和meta表
- default:用户建表时未指定namespace的表都创建在此
HBase寻址:
- 本节主要讨论的问题:Client访问用户数据时如何找到某个row key所在的region?
- 0.94- 版本 Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,如下图:
- 0.96+ 删除了root 表,改为zookeeper里面的文件,如下图 A, 以读为例,寻址示意图如B
图A
图B
Write:
- 当客户端发起一个Put请求时,首先根据RowKey寻址,从hbase:meta表中查出该Put数据最终需要去的HRegionServer
- 客户端将Put请求发送给相应的HRegionServer,在HRegionServer中它首先会将该Put操作写入WAL日志文件中(Flush到磁盘中),如下图:
- 完WAL日志文件后,HRegionServer根据Put中的TableName和RowKey找到对应的HRegion,并根据Column Family找到对应的HStore
- 将Put数据写入到该HStore的MemStore中。此时写成功,并返回通知客户端
- 上一节介绍过,MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。
- 它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序,如下示意图:
- 每一次Put请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或多个StoreFile(HFile)
- 注意:MemStore的最小Flush单元是HRegion而不是单个MemStore, 这就是建议使用单列族的原因,太多的Column Family一起Flush会引起性能问题
- MemStore触发Flush动作的时机:
- 当一个MemStore的大小超过了hbase.hregion.memstore.flush.size的大小,此时当前的HRegion中所有的MemStore会Flush到HDFS中
- 当全局MemStore的大小超过了hbase.regionserver.global.memstore.upperLimit的大小,默认40%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush顺序是MemStore大小的倒序,直到总体的MemStore使用量低于hbase.regionserver.global.memstore.lowerLimit,默认38%的内存使用量
- 待确认:一个HRegion中所有MemStore总和作为该HRegion的MemStore的大小还是选取最大的MemStore作为参考?
- 当前HRegionServer中WAL的大小超过了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush使用时间顺序,最早的MemStore先Flush直到WAL的数量少于hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs
- 注意:因为这个大小超过限制引起的Flush不是一件好事,可能引起长时间的延迟
- 在MemStore Flush过程中,还会在尾部追加一些meta数据,其中就包括Flush时最大的WAL sequence值,以告诉HBase这个StoreFile写入的最新数据的序列,那么在Recover时就直到从哪里开始。在HRegion启动时,这个sequence会被读取,并取最大的作为下一次更新时的起始sequence,如下图:
Compaction:
- MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题,HBase采用Compaction机制来解决这个问题
- HBase中Compaction分为两种:Minor Compaction和Major Compaction
- Minor Compaction: 是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile, 如下图:
- Major Compaction: 是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在
- Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间, 如下示意图:
- 修改Hbase配置文件可以控制compaction行为
- hbase.hstore.compaction.min :默认值为 3,(老版本是:hbase.hstore.compactionThreshold),即store下面的storeFiles数量 减去 正在compaction的数量 >=3是,需要做compaction
- hbase.hstore.compaction.max 默认值为10,表示一次minor compaction中最多选取10个store file
- hbase.hstore.compaction.min.size 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
- hbase.hstore.compaction.max.size 表示文件大小大于该值的store file 一定会被minor compaction排除
splite:
- 最初,一个Table只有一个HRegion,随着数据写入增加,如果一个HRegion到达一定的大小,就需要Split成两个HRegion,这个大小由hbase.hregion.max.filesize指定
- split时,两个新的HRegion会在同一个HRegionServer中创建,它们各自包含父HRegion一半的数据,当Split完成后,父HRegion会下线,而新的两个子HRegion会向HMaster注册上线
- 处于负载均衡的考虑,这两个新的HRegion可能会被HMaster分配到其他的HRegionServer,示意图如下:
- 在zookeeper上创建ephemeral的znode指示parent region正在splitting
- HMaster监控父Regerion的region-in-transition znode
- 在parent region的文件夹中创建临时split目录
- 关闭parent region(会flush 所有memory store(memory file),等待active compaction结束),从现在开始parent region 不可服务。同时从本地server上offline parent region,每个region server都维护了一个valid region的list,该步将parent region从该list中移除
- Split所有的store file,这一步为每个文件做一个reference file,reference file由两部分组成
- 第一部分是源文件的路径,第二部分是新的reference file引用源文件split key以及引用上半截还是下半截
- 举个例子:源文件是Table1/storefile.11,split point 是key1, 则split 成两个子文件可能可能是Table1/storefile.11.bottom.key1,Table1/storefile.11.up.key1,表示从key1切开storefile.11后,两个引用文件分别引用源文件的下半部分和上半部分
- 创建child region
- 设置各种属性,比如将parent region的访问指标平分给child region,每人一半
- 将上面在parent 文件夹中生成的临时文件夹(里面包含对parent region的文件reference)move到表目录下,现在在目录层次上,child region已经跟parent region平起平坐了
- 向系统meta server中写入parent region split完毕的信息,并将child region的名字一并写入(split状态在meta层面持久化)
- 分别Open 两个child region,主要包含以下几个步骤:
- 将child region信息写入meta server
- Load 所有store file,并replay log等
- 如果包含reference文件,则做一次compaction(类似merge),直到将所有的reference文件compact完毕,这里可以看到parent region的文件是会被拆开写入各个child regions的
- 将parent region的状态由SPLITTING转为SPLIT,zookeeper会负责通知master开始处理split事件,master开始offline parent region,并online child regions
- Worker等待master处理完毕之后,确认child regions都已经online,split结束
read:
- 根据Rowkey寻址(详情见上一节寻址部分),如下图:
获取数据顺序规则,如下图:
参考和来源:https://www.cnblogs.com/tgzhu/p/5857035.html
参考资料:
- http://hortonworks.com/blog/apache-hbase-region-splitting-and-merging/
- https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdNSN6Yp3qx
以上是 Hbase架构剖析 的全部内容, 来源链接: utcz.com/z/531883.html