Hadoop完全分布式集群搭建

Hadoop的运行模式
Hadoop一般有三种运行模式,分别是:
- 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统。,用于开发和调试。
- 伪分布式模式(Pseudo Distrubuted Mode),使用的是分布式文件系统,守护进程运行在本机机器,模拟一个小规模的集群,在一台主机模拟多主机,适合模拟集群学习。
- 完全分布式集群模式(Full Distributed Mode),Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
这里介绍的就是如何搭建一个Hadoop完全分布式集群。
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
安装环境介绍
准备了四个服务器,IP为192.168.0.236、192.168.0.237、192.168.0.238、192.168.0.239,其中192.168.0.236作为主节点,其他3个作为从节点。具体版本信息如下:
- CentOS 7.4
- JDK 8
- Hadoop 2.10.0
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
准备安装环境
设置主机名
在各个服务器上修改对应的主机名:
#在192.168.0.236上执行:hostnamectl set-hostname onemore-hadoop-master
#在192.168.0.237上执行:
hostnamectl set-hostname onemore-hadoop-slave1
#在192.168.0.238上执行:
hostnamectl set-hostname onemore-hadoop-slave2
#在192.168.0.239上执行:
hostnamectl set-hostname onemore-hadoop-slave3
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
关闭SELINUX
编辑/etc/selinux/config文件:
vi /etc/selinux/config把
SELINUX=enforcing修改为:
SELINUX=disabled重启服务器
reboot欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
设置hosts
cat >> /etc/hosts <<EOF192.168.0.236 onemore-hadoop-master
192.168.0.237 onemore-hadoop-slave1
192.168.0.238 onemore-hadoop-slave2
192.168.0.239 onemore-hadoop-slave3
EOF
关闭防火墙
停止防火墙
systemctl stop firewalld.service禁止防火墙开机启动
systemctl disable firewalld.service欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
设置免密登录
分布式集群搭建需要主节点能够免密登录至各个从节点上。因此,需要在主节点上生成公钥,把将主节点的公钥在从节点中加入授权。
- 在192.168.0.236上生成公钥。
ssh-keygen -t rsa- 在192.168.0.236上,把公钥发送到各个从节点
scp ~/.ssh/id_rsa.pub 192.168.0.237:~/.sshscp ~/.ssh/id_rsa.pub 192.168.0.238:~/.ssh
scp ~/.ssh/id_rsa.pub 192.168.0.239:~/.ssh
这时还不是免密登录登录的,需要输入用户名和密码。
- 将公钥追加到各个从节点的授权里。
在每个从节点执行一下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
安装JDK
参见之前的《详解在Linux系统中安装JDK》,这里就不再赘述了。
Hadoop环境配置
主节点配置
下载Hadoop
从北京理工大学的镜像上下载Hadoop:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz创建文件夹
mkdir /usr/local/hadoop解压
tar -xzvf hadoop-2.10.0.tar.gz -C /usr/local/hadoop欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
配置环境变量
追加Hadoop的环境变量到/etc/profile文件中
cat >> /etc/profile <<EOF#Hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
EOF
使环境变量生效
source /etc/profile欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
修改配置文件
修改core-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/core-site.xml修改其内容为:
<configuration> <property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://onemore-hadoop-master:9000</value>
</property>
</configuration>
修改hdfs-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hdfs-site.xml修改其内容为:
<configuration> <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
复制mapred-site.xml.template为mapred-site.xml
cp /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml再修改mapred-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml修改其内容为:
<configuration> <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://onemore-hadoop-master:9001</value>
</property>
</configuration>
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
修改yarn-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/yarn-site.xml修改其内容为:
<configuration> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>onemore-hadoop-master</value>
</property>
</configuration>
新建masters配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/masters新增内容为:
onemore-hadoop-master配置slaves文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/slaves修改其内容为:
onemore-hadoop-slave1onemore-hadoop-slave2
onemore-hadoop-slave3
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
从节点配置
下面以onemore-hadoop-slave1从节点为例进行叙述,您需参照以下步骤完成onemore-hadoop-slave2和onemore-hadoop-slave3从节点的配置。
下载Hadoop
还是从北京理工大学的镜像上下载Hadoop(如果下载速度慢,可以在主节点上发送到从节点):
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz创建文件夹
mkdir /usr/local/hadoop解压
tar -xzvf hadoop-2.10.0.tar.gz -C /usr/local/hadoop欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
配置环境变量
追加Hadoop的环境变量到/etc/profile文件中
cat >> /etc/profile <<EOF#Hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
EOF
使环境变量生效
source /etc/profile欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
修改配置文件
删除slaves文件
rm -rfv /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/slaves在主节点上把5个配置文件发送到从节点上
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/core-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hdfs-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/yarn-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/masters onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
启动Hadoop集群
格式化namenode
第一次启动服务前需要执行词操作,以后就不需要执行了。
hadoop namenode -format启动hadoop
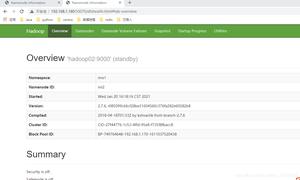
/usr/local/hadoop/hadoop-2.10.0/sbin/start-all.sh访问http://onemore-hadoop-master:50070/,就可以查看Hadoop集群的相关信息了,如图:
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
常用命令
查看Hadoop集群的状态
hadoop dfsadmin -report重启Hadoop
/usr/local/hadoop/hadoop-2.10.0/sbin/stop-all.sh/usr/local/hadoop/hadoop-2.10.0/sbin/start-all.sh
启动dfs服务
/usr/local/hadoop/hadoop-2.10.0/sbin/start-dfs.sh欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
常见错误
Error: JAVA_HOME is not set and could not be found.
这个错误大概意思是没有找到JDK的环境变量,可以修改hadoop-env.sh。
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hadoop-env.sh增加JDK的环境变量,比如:
export JAVA_HOME=/usr/local/java/jdk1.8.0_231因为是在主节点上修改的,还需要发送到各个从节点:
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hadoop-env.sh onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hadoop-env.sh onemore-hadoop-slave2:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hadoop-env.sh onemore-hadoop-slave3:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货。
以上是 Hadoop完全分布式集群搭建 的全部内容, 来源链接: utcz.com/z/531795.html